hadoop 批量处理脚本编写
Posted yuanweiblogger
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop 批量处理脚本编写相关的知识,希望对你有一定的参考价值。
编写shell脚本就是解决批量处理
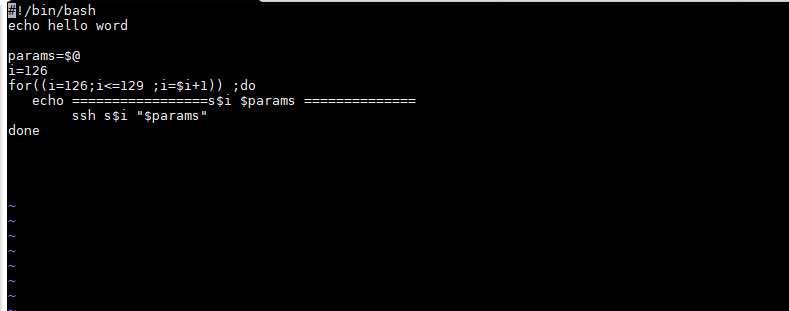
1. 在/usr/local/bin 创建脚本 并授权所有用户 chmod a+x xcall.sh
xcall.sh
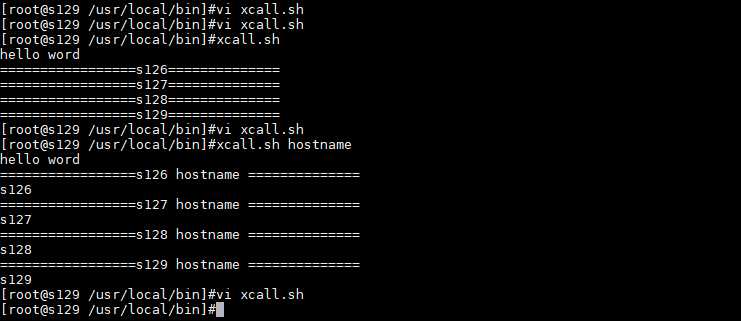
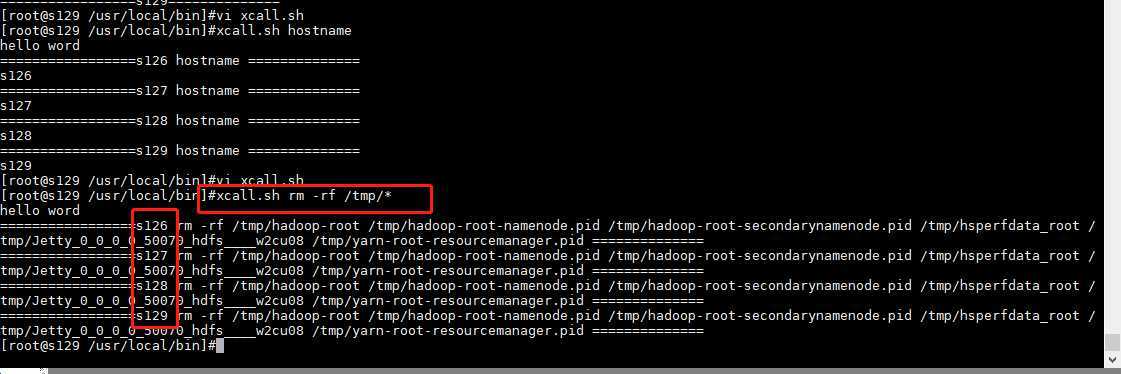
比如:删除/tmp/*所有文件 批量删除4台服务器的/tmp/*所有文件
xcall.sh rm -rf /tmp/*
2 rsync 远程同步 速度快
四个机器均安装rsync命令。 s129 s128 s127 s126
远程同步.
$>sudo yum install rsync 或 yum install rsync
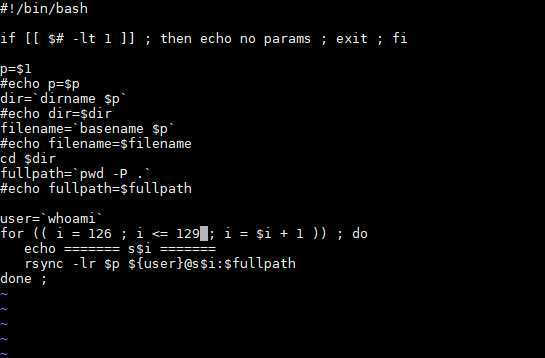
rsync -lr 赋值链接(包括符号链接)
远程同步,支持符号链接。
rsync -lr xxx xxx
权限配置
ssh权限问题
----------------
1.~/.ssh/authorized_keys
644
2.$/.ssh
700
3.root

以上是关于hadoop 批量处理脚本编写的主要内容,如果未能解决你的问题,请参考以下文章