大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]() ?
?![]() QQ:3025393450
QQ:3025393450
![]() ?
?
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询

欢迎选修我们的R语言数据分析挖掘必知必会课程!

Posted tecdat
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言中的划分聚类模型相关的知识,希望对你有一定的参考价值。
划分聚类 是用于基于数据集的相似性将数据集分类为多个组的聚类方法。
分区聚类,包括:
对于这些方法中的每一种,我们提供:
数据准备:
my_data <- USArrests
# Remove any missing value (i.e, NA values for not available)
my_data <- na.omit(my_data)
# Scale variables
my_data <- scale(my_data)
# View the firt 3 rows
head(my_data, n = 3)## Murder Assault UrbanPop Rape
## Alabama 1.2426 0.783 -0.521 -0.00342
## Alaska 0.5079 1.107 -1.212 2.48420
## Arizona 0.0716 1.479 0.999 1.04288确定k-means聚类的最佳聚类数:
fviz_nbclust(my_data, kmeans,
method = "gap_stat")## Clustering k = 1,2,..., K.max (= 10): .. done
## Bootstrapping, b = 1,2,..., B (= 100) [one "." per sample]:
## .................................................. 50
## .................................................. 100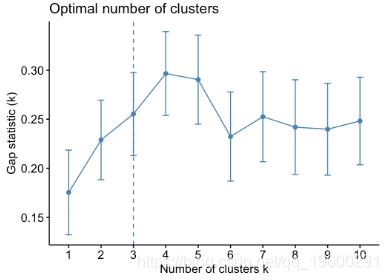
![]() ?
?
计算和可视化k均值聚类:
fviz_cluster(km.res, data = my_data,
ellipse.type = "convex",
palette = "jco",
repel = TRUE,
ggtheme = theme_minimal())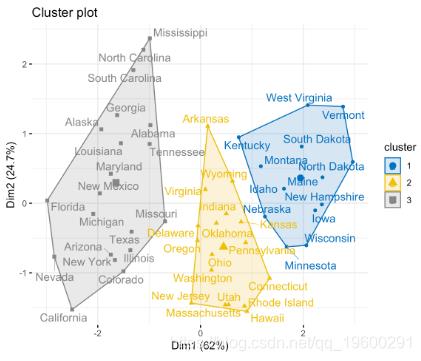
![]() ?
?
同样,可以如下计算和可视化PAM聚类:
pam.res <- pam(my_data, 4)
# Visualize
fviz_cluster(pam.res)
大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]() ?
?![]() QQ:3025393450
QQ:3025393450
![]() ?
?
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询
欢迎选修我们的R语言数据分析挖掘必知必会课程!
以上是关于R语言中的划分聚类模型的主要内容,如果未能解决你的问题,请参考以下文章