drf--ModelSerializers序列化
Posted hades123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了drf--ModelSerializers序列化相关的知识,希望对你有一定的参考价值。
目录
drf--ModelSerializers序列化
项目准备
配置 settings.py
# 注册rest_framework app
INSTALLED_APPS = [
# ...
'rest_framework',
]
# 连接mysql数据库
DATABASES =
'default':
'ENGINE': 'django.db.backends.mysql',
'NAME': 'dg_proj',
'USER': 'root',
'PASSWORD': '123',
'HOST': '127.0.0.1',
'PORT': 3306
# 导入pymysql模块
"""
任何__init__文件
import pymysql
pymysql.install_as_MySQLdb()
"""
# 汉化
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai'
USE_I18N = True
USE_L10N = True
USE_TZ = False
# 配置静态文件路径以及媒体文件路径
STATIC_URL = '/static/'
STATICFILES_DIRS = (
os.path.join(BASE_DIR, 'static'),
)
MEDIA_URL = '/media/'
MEDIA_ROOT = os.path.join(BASE_DIR, 'media')路由
主路由 urls.py
from django.conf.urls import url, include
from django.contib import admin
from django.views import serve
from django.conf import settings
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^api/', include('api.urls')),
url(r'^media/(?P<path>.*)', serve, 'document_root': settings.MEDIA_ROOT),
]子路由 api/urls.py
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^books/$', views.BookAPIView.as_view()),
url(r'^books/(?P<pk>\\d+)/$', views.BookAPIView.as_view()),
]多表设计
表关系分析
"""
Book表:
name, price, img, publish(关联Publish表), authors(关联Author表), is_delete, create_time
Publish表:
name, address, is_delete, create_time
Author表:
name, age, is_delete, create_time
AuthorDetail表:
mobile, author(关联Author表), is_delete, create_time
因为每个字段都有is_delete, create_time这两个字段,所以我们可以设置一个基表,其他的表继承基表
BaseModel表:
is_delete, create_time
"""表关系图:
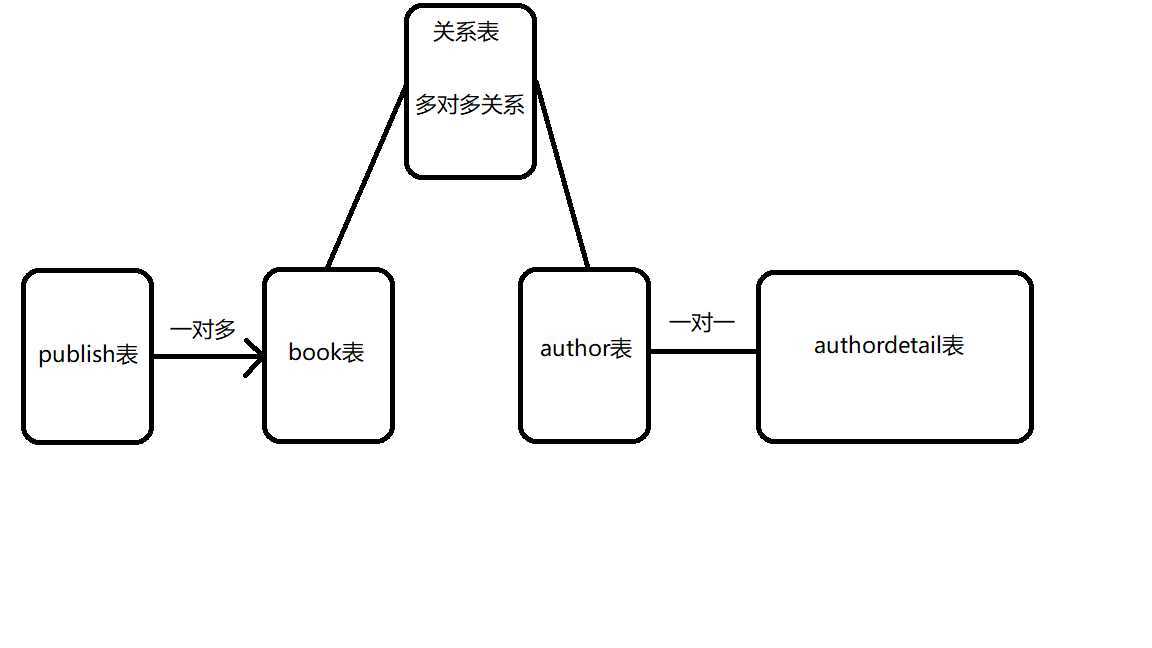
创建models
基表 utils/models.py
from django.db import models
class BaseModel(models.Model):
is_delete = models.BooleanField(default=False)
create_time = models.DateTimeField(auto_now_add=True, null=True)
class Meta:
# 抽象表, 不会完成数据库迁移
abstract = True模型层 api/models.py
from django.db import models
from utils.models import BaseModel
"""
relate_name: 从表在查主表时,可以通过relate_name进行查询,无需再进行反向查询(表名小写_set)
db_constraint: 设为False表示断开表关系
on_delete: 默认为CASCSADE, 表示主表进行删除操作时进行级联删除
DO_NOTHING, 表示主表进行删除时, 不进行任何操作
SET_NULL, 表示主表进行删除时, 该字段设为null, 此时null要设为True
SET_DEFAULT, 表示主表进行删除时, 该字段设为默认值, 此时default要进行设置
注意: on_delete操作, 从表删除时,主表不会有任何变化
db_table: 设置建表是的表名, 不采用默认表名
verbose_name: 在admin中进行操作时, 反馈到前台表或者字段的名字
"""
# Create your models here.
class Book(BaseModel):
name = models.CharField(max_length=64)
price = models.DecimalField(max_digits=6, decimal_places=2)
img = models.ImageField(upload_to='icon', default='icon/default.png')
publish = models.ForeignKey(to='Publish',
null=True,
related_name='books',
db_constraint=False,
on_delete=models.DO_NOTHING
# on_delete=models.SET_NULL, null=True
# on_delete=models.SET_DEFAULT, default=1
)
authors = models.ManyToManyField(to='Author',
related_name='authors',
db_constraint=False
)
# 自定义model类的方法,完成插拔式跨表查询,默认在校验时为read_only
@property
def publish_info(self):
return 'name': self.publish.name, 'address': self.publish.address
@property
def author_info(self):
author_list = []
for author in self.authors.all():
detail = AuthorDetail.objects.filter(author_id=self.author.id)
author_list.append(
'name': author.name,
'age': author.age,
# 注意点:当author.detail为空时,就直接不走这一步了
# 'mobile': author.detail.mobile
'mobile': '未知' if not detail else author.detail.mobile
)
return author_list
class Meta:
db_table = "books"
verbose_name = '书籍'
verbose_name_plural = verbose_name
def __str__(self):
return self.name
class Author(BaseModel):
name = models.CharField(max_length=64)
age = models.IntegerField()
@property
def mobile(self):
return self.detail.mobile
class Meta:
db_table = 'author'
verbose_name = '作者'
verbose_name_plural = verbose_name
def __str__(self):
return self.name
class AuthorDetail(BaseModel):
mobile = models.CharField(max_length=11)
author = models.OneToOneField(to='Author',
null=True,
related_name='detail',
db_constraint=False,
on_delete=models.CASCADE
)
class Meta:
db_table = 'detail'
verbose_name = '作者详情'
verbose_name_plural = verbose_name
def __str__(self):
return f"self.author.name的详情"
class Publish(BaseModel):
name = models.CharField(max_length=64)
address = models.CharField(max_length=128)
class Meta:
db_table = 'publish'
verbose_name = '出版社'
verbose_name_plural = verbose_name
def __str__(self):
return self.name模型序列化
继承自rest_framework.serializers中的ModelSerializer
在自定义的ModelSerializer类中设置class Meta
model 绑定序列化的模型类
fields 通过插拔的方式指定序列化字段
在模型类中,通过在模型表中方法属性来自定义连表查询的字段,然后在fields中插拔
如果使用外键字段完成连表查询,用序列化深度
eg:publish = PublishModelSerializer()
自定义模型序列化 api/serializers.py
from rest_framework import serializers
from . import models
# 序列化深度
class PublishModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Publish
fields = ('name', 'address')
# 序列化深度
class AuthorModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Author
fields = ('name', 'age', 'mobile')
class BookModelSerializer(serializers.ModelSerializer):
# 正向序列化深度
publish = PublishModelSerializer()
authors = AuthorModelSerializer(many=True)
"""了解:
在ModelSerializer中不建议使用,如何书写了必须在fields中声明使用
p_n = serializers.SerializerMethodField()
def get_p_n(self, obj: models.Book):
return obj.publish.name
"""
class Meta:
# 绑定序列化的模型类
model = models.Book
# 插拔字段
fields = ('name', 'price', 'img', 'publish', 'authors', 'publish_info', 'author_info')
"""了解:
fields = "__all__" :拿出所有字段
exclude = ('id', 'is_delete'):除了这些字段,其它字段全部拿出来
depth = 1 :跨表查询的深度(展示外键的所有字段)
"""视图中使用 api/views.py
from rest_framework.views import APIView
from utils.response import APIResponse
from . import models, serializers
class BookAPIView(APIView):
def get(self, request, *args, **kwargs):
# 单取
pk = kwargs.get('pk')
if pk:
book_obj = models.Book.objects.filter(pk=pk, is_delete=False).first()
if not book_obj:
return APIResponse(1, 'pk有误')
book_ser = serializers.BookModelSerializer(book_obj)
return APIResponse(0, 'ok', results=book_ser.data)
book_obj_list = models.Book.objects.filter(is_delete=False).all()
if not book_obj_list:
return APIResponse(1,'没有数据')
book_ser = serializers.BookModelSerializer(book_obj_list, many=True)
return APIResponse(0,'ok',results=book_ser.data)模型反序列化
继承自rest_framework.serializers中的ModelSerializer
在自定义的ModelSerializer类中设置class Meta
models:绑定反序列化相关的模型类
fields:插拔方式指定反序列化字段
extra_kwargs:定义系统校验字段的规则
可以自定义局部钩子和全局钩子完成字段的复杂校验规则
不需要重写create和update完成增加修改,ModelSerializer类已经帮我们实现了
自定义模型反序列化 api/serializers.py
from rest_framework import serializers
from . import models
class BookModelDeserializer(serializers.ModelSerializer):
# 自定义的校验字段,一定要插入到fields中
re_name = serializers.CharField(
min_length=3,
required=True,
error_messages=
'min_length': '太短了',
'required': '不能为空'
)
class Meta:
model = models.Book
fields = ('name', 're_name', 'price', 'publish', 'authors')
extra_kwargs =
'name':
'min_length': 3,
'error_messages':
'min_length': '太短了',
'required': '不能为空'
,
# 有默认值的字段会默认required为False,在反序列化中就不会进行校验
'publish':
'required': True,
'error_messages':
'required': '不能为空'
,
'authors':
'required': True,
'error_messages':
'required': '不能为空'
# 自定义校验规则
# 局部钩子
def validate_name(self, value):
if 'sb' in value:
raise serializers.ValidationError('书名包含敏感词汇')
return value
def validate(self, attr):
name = attr.get('name')
re_name = attr.get('re_name')
publish = attr.get('publish')
if name != re_name:
raise serializers.ValidationError(
're_name': '两次书名不一致'
)
if models.Book.objects.filter(name=name, publish=publish):
raise serializers.ValidationError(
'book': '书籍已存在'
)
return attr 视图中使用 api/views.py
from rest_framework.views import APIView
from utils.response import APIResponse
from . import models, serializers
class BookAPIView(APIView):
def post(self, request, *args, **kwargs):
book_ser = serializers.BookModelDeserializer(data=request.data)
if book_ser.is_valid():
book_obj = book_ser.save()
results = serializers.BookModelDeserializer(book_obj).data
return APIResponse(0, 'ok', results=results)
else:
return APIResponse(1, '添加失败', resultes=book_ser.errors)模型序列化器(序列化与反序列化整合*****)
子路由 api/urls.py
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^v2/books/$', views.BookV2APIView.as_view()),
url(r'^v2/books/(?P<pk>.*)/$', views.BookV2APIView.as_view()),
]自定义序列化器 api/serializers.py
from rest_framework import serializers
from . import models
class BookV2ModelSerializer(serializers.ModelSerializer):
re_name = serializers.CharField(
min_length=3,
required=True,
write_only=True, # 只参与反序列化
error_messages=
'min_length': '太短了',
'required': '不能为空'
)
class Meta:
model = models.Book
fields = ('name', 're_name', 'price', 'img', 'publish', 'publish_info', 'authors', 'authors_info')
extra_kwargs =
'name':
'min_length': 3,
'error_messages':
'min_length': '太短了',
'required': '不能为空'
,
# 有默认值的字段会默认required为False,在反序列化中如果不传值不会进行校验,但是如果传值就会进行校验
'publish':
'required': True,
'write_only': True,
'error_messages':
'required': '不能为空'
,
'authors':
'required': True,
'write_only': True,
'error_messages':
'required': '不能为空'
,
# 自定义校验规则
# 局部钩子
def validate_name(self, value):
if 'sb' in value:
raise serializers.ValidationError('书名包含敏感词汇')
return value
def validate(self, attr):
name = attr.get('name')
re_name = attr.get('re_name')
publish = attr.get('publish')
if name != re_name:
raise serializers.ValidationError(
're_name': '两次书名不一致'
)
if models.Book.objects.filter(name=name, publish=publish):
raise serializers.ValidationError(
'book': '书籍已存在'
)
return attr
视图中使用 api/views.py
class BookV2APIView(APIView):
def get(self, request, *args, **kwargs):
pk = request.get('pk')
# 单取
if pk:
book_obj = models.Book.objects.filter(is_delete=False, pk=pk).first()
if not pk:
return APIResponse(1, 'pk有误')
book_ser = serializers.BookV2ModelSerializer(book_obj)
return APIResponse(0, 'ok', results=book_ser.data)
# 群取
book_obj_list = models.Book.objects.filter(is_delete=False).all()
if not book_obj_list:
return APIResponse(1, '没有数据')
book_ser = serializers.BookV2ModelSerializer(book_obj_list, many=True)
return APIResponse(0, 'ok', results=book_ser.data)
# 增加一个
def post(self, request, *args, **kwargs):
book_ser = serializers.BookV2ModelSerializer(data=request.data)
if book_ser.is_valid():
book_obj = book_ser.save()
results = serializers.BookV2ModelSerializer(book_obj).data
return APIResponse(0, 'ok', results=results)
else:
return APIResponse(1, '添加失败', results=book_ser.errors)
# 局部修改一个
def patch(self, request, *args, **kwargs):
pk = request.get('pk')
if not pk:
return APIResponse(1, 'pk有误')
try:
book_obj = models.Book.objects.get(is_delete=False, pk=pk)
except:
return APIResponse(1, 'pk不存在')
book_ser = serializers.BookV2ModelSerializer(instance=book_obj, data=request.data, partial=True)
if book_ser.is_valid():
book_obj = book_ser.save()
results = serializers.BookV2ModelSerializer(book_obj)
return APIResponse(0, 'ok', results=results)
else:
return APIResponse(1, '修改失败', results=book_ser.errors)
# 整体修改一个
def put(self, request, *args, **kwargs):
pk = request.get('pk')
if not pk:
return APIResponse(1, 'pk有误')
try:
book_obj = models.Book.objects.get(is_delete=False, pk=pk)
except:
return APIResponse(1, 'pk不存在')
book_ser = serializers.BookV2ModelSerializer(instance=book_obj, data=request.data)
if book_ser.is_valid():
book_obj = book_ser.save()
results = serializers.BookV2ModelSerializer(book_obj)
return APIResponse(0, 'ok', results=results)
else:
return APIResponse(1, '修改失败', results=book_ser.errors)
# 删除
def delete(self, request, *args, **kwargs):
# 单删 /books/(pk)/
# 群删 /books/ 数据包携带 pks => request.data
pk = request.get('pk')
if pk:
pks = [pk, ]
else:
pks = request.data.get('pk')
if not pks:
return APIResponse(1, 'pk有误')
book_obj_list = models.Book.objects.filter(is_delete=False, pk__in=pks)
if not book_obj_list.update(is_delete=True):
return APIResponse(1, '删除失败')
return APIResponse(0, '删除成功')以上是关于drf--ModelSerializers序列化的主要内容,如果未能解决你的问题,请参考以下文章