HDFS集群中DataNode的上线与下线
Posted tesla-turing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS集群中DataNode的上线与下线相关的知识,希望对你有一定的参考价值。
在HDFS集群的运维过程中,肯定会遇到DataNode的新增和删除,即上线与下线。这篇文章就详细讲解下DataNode的上线和下线的过程。
背景
在我们的微职位视频课程中,我们已经安装了3个节点的HDFS集群,master机器上安装了NameNode和SecondaryNameNode角色,slave1和slave2两台机器上分别都安装了DataNode角色。
我们现在来给这个HDFS集群新增一个DataNode,这个DataNode是安装在master机器上
我们需要说明的是:在实际环境中,NameNode和DataNode最好是不在一台机器上的,我们这里都放在master上,是因为我们的虚拟机资源有限。
我们现在启动master、slave1和slave2三台虚拟机,然后启动HDFS集群,我们在HDFS的Web UI上可以看到有两个DataNode:
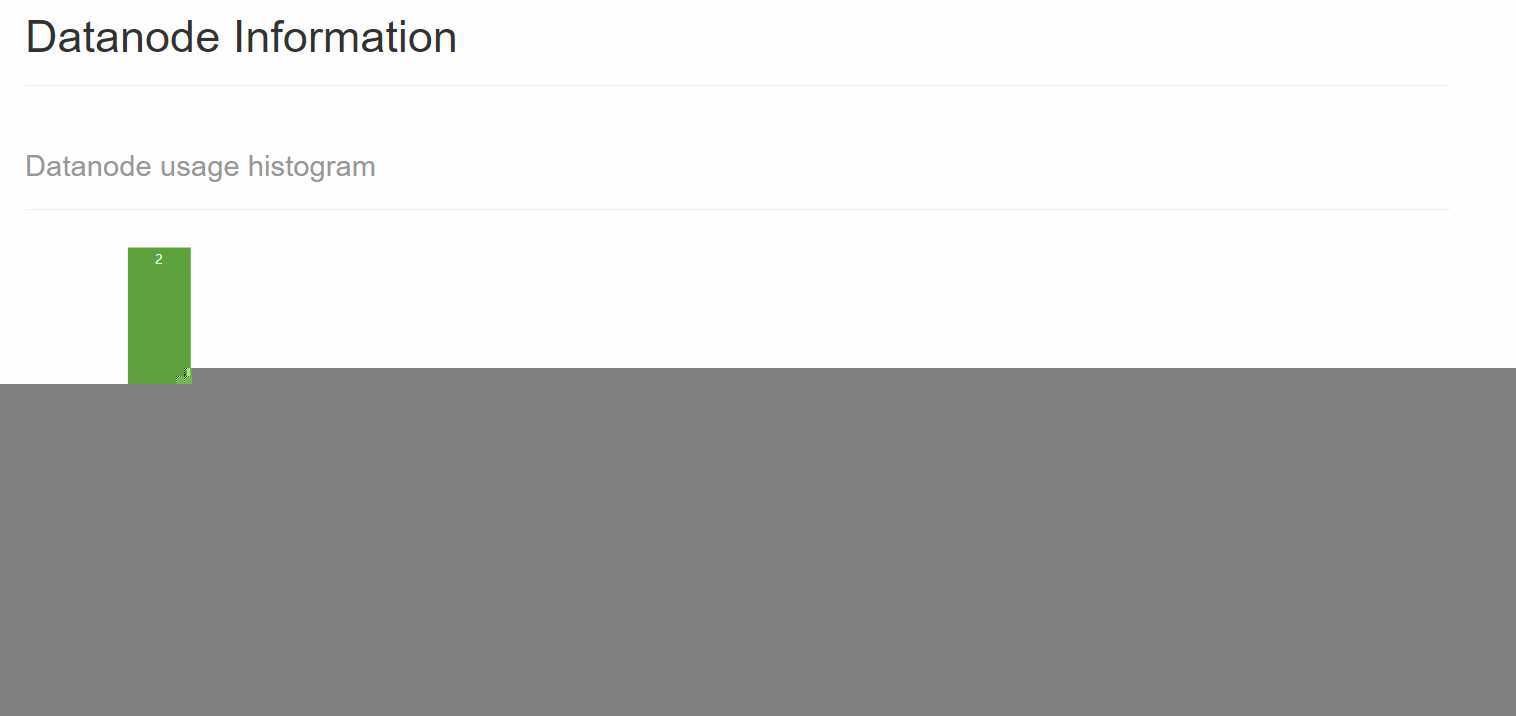
DataNode上线
在NameNode所在的机器(master)上的配置文件hdfs-site.xml中增加"白名单"配置:
<property>
<!-- 白名单信息-->
<name>dfs.hosts</name>
<value>/home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/dfs.include</value>
</property>
在master机器上执行下面的命令:
## 创建白名单文件 touch /home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/dfs.include
在/home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/dfs.include文件中增加如下内容:
slave1 slave2 master
其中,上面的master是新增的DataNode所在的机器
在/home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/slaves文件中新增:
master
3.然后在NameNode所在的机器(master)上执行如下的命令:
hdfs dfsadmin -refreshNodes
然后,我们在HDFS的Web UI上查看DataNode的信息:
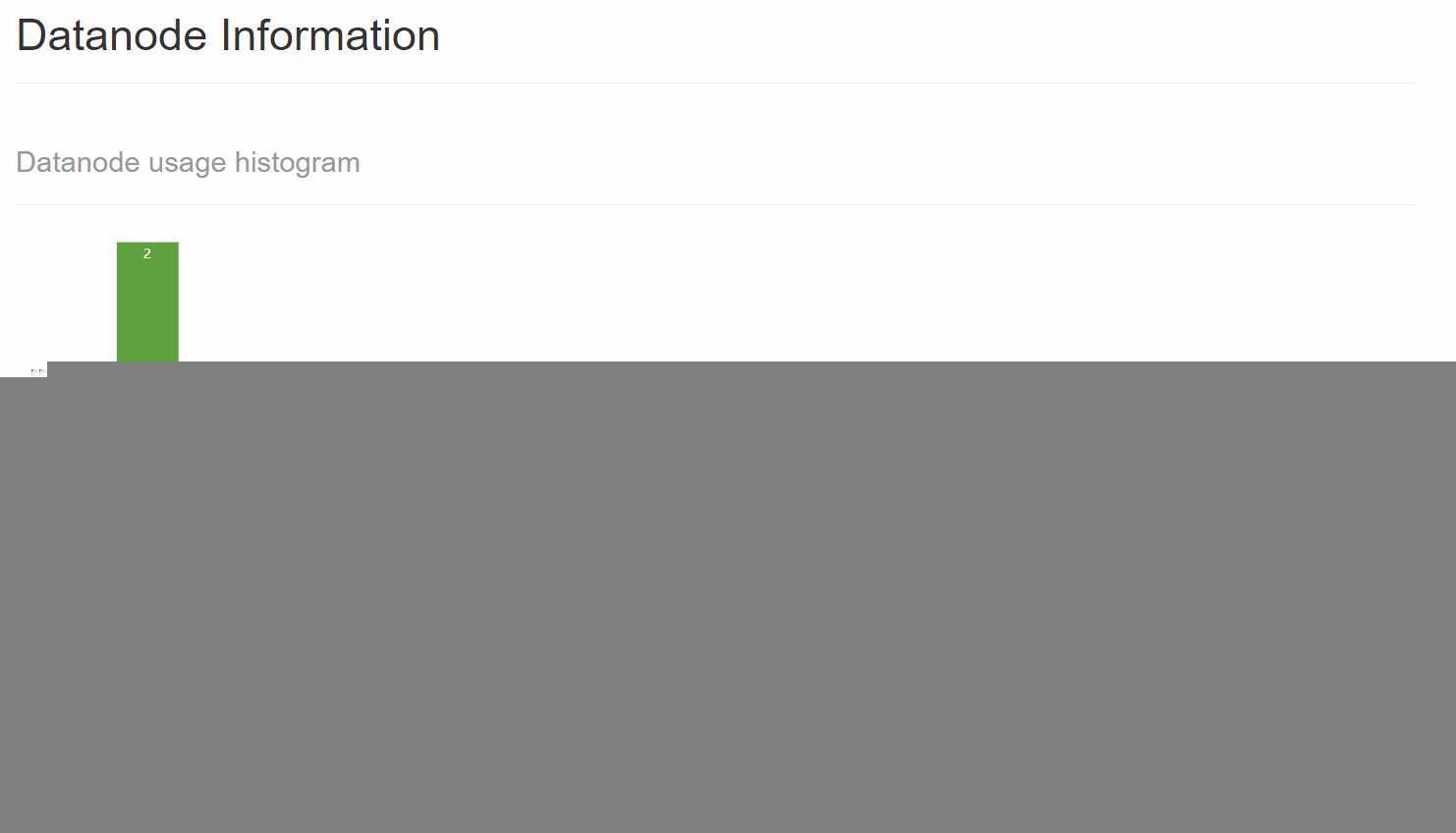
可以看出,多了一个状态为Dead的DataNode

可以看出,多了一个状态为Dead的DataNode
4.在master机器上启动DataNode:
hadoop-daemon.sh start datanode
然后我们刷新HDFS的Web UI的DataNode信息,如下图:
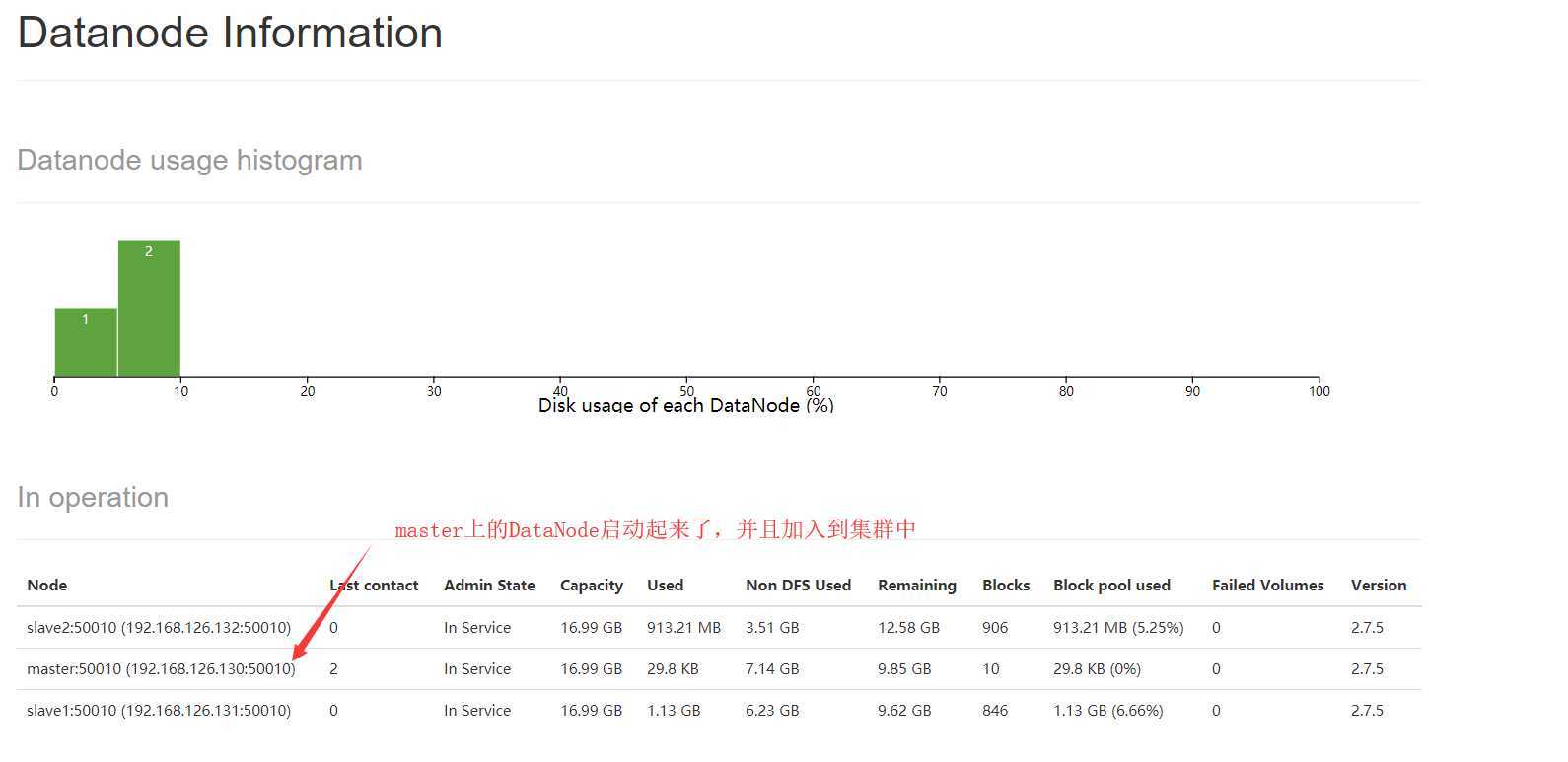
可以看出,DataNode现在是3个了,master上的DataNode已经启动起来,并且加入集群中
DataNode的下线
我们现在下线master上的DataNode,步骤如下:
- 在NameNode所在的机器(master)上的配置文件hdfs-site.xml中增加"黑名单"配置:
<property>
<!-- 黑名单信息-->
<name>dfs.hosts.exclude</name>
<value>/home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/dfs.exclude</value>
</property>
在master机器上执行下面的命令:
## 创建黑名单文件 touch /home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/dfs.exclude
在/home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/dfs.exclude文件中增加如下内容:
master
其中,上面的master是需要下线的DataNode所在的机器
在/home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/slaves文件中删除master行
然后在NameNode所在的机器(master)上执行如下的命令:
hdfs dfsadmin -refreshNodes
然后我们刷新HDFS的Web UI的DataNode信息,如下图:
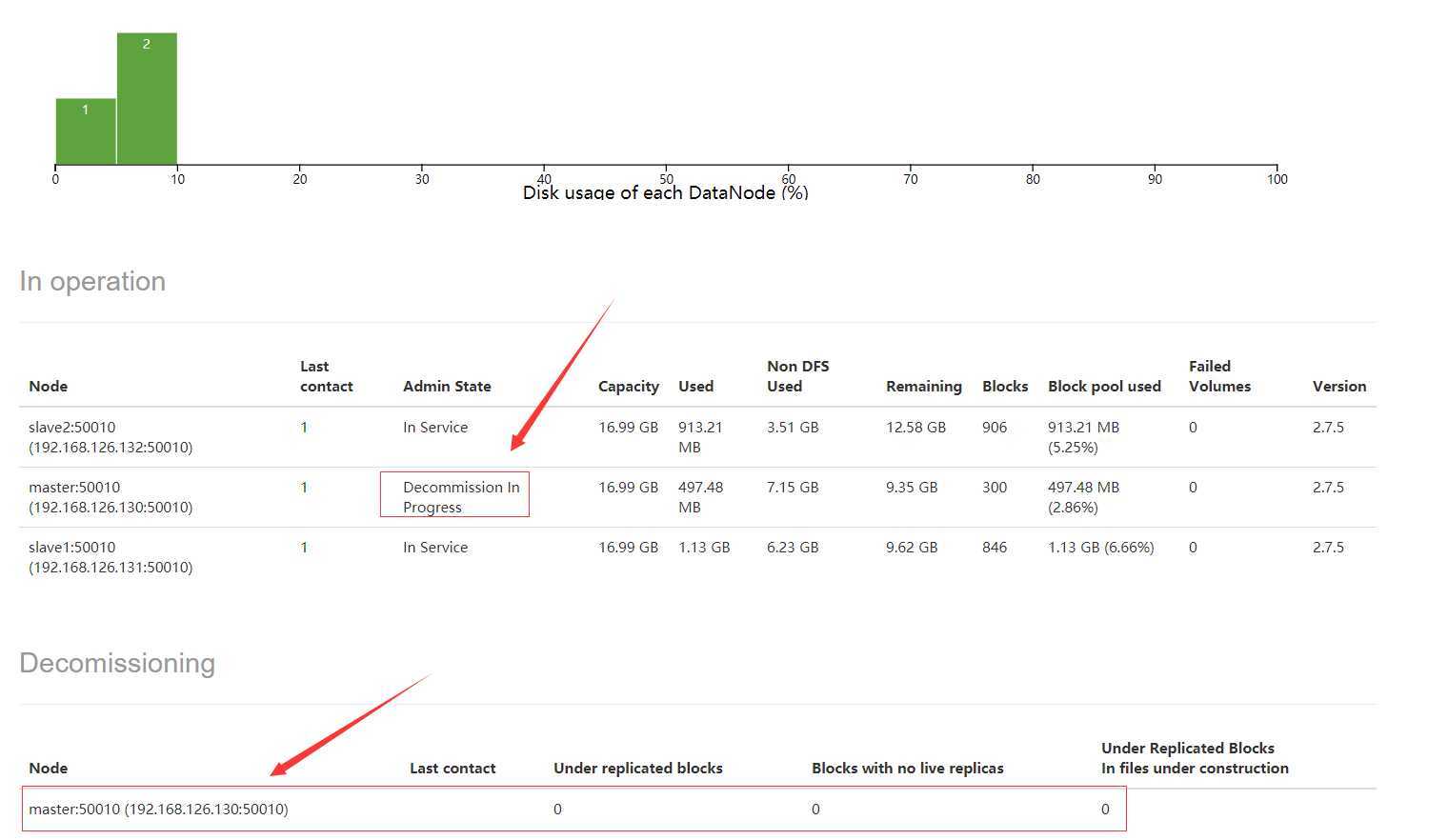
这个时候,master上的DataNode的状态变为Decommission In Progress。这个时候,在master上的DataNode的数据都在复制转移到其他的DataNode上,当数据转移完后,我们再刷新HDFS Web UI后,可以看到DataNode的状态变为Decommissioned,表示这个DataNode已经下线,如下图:
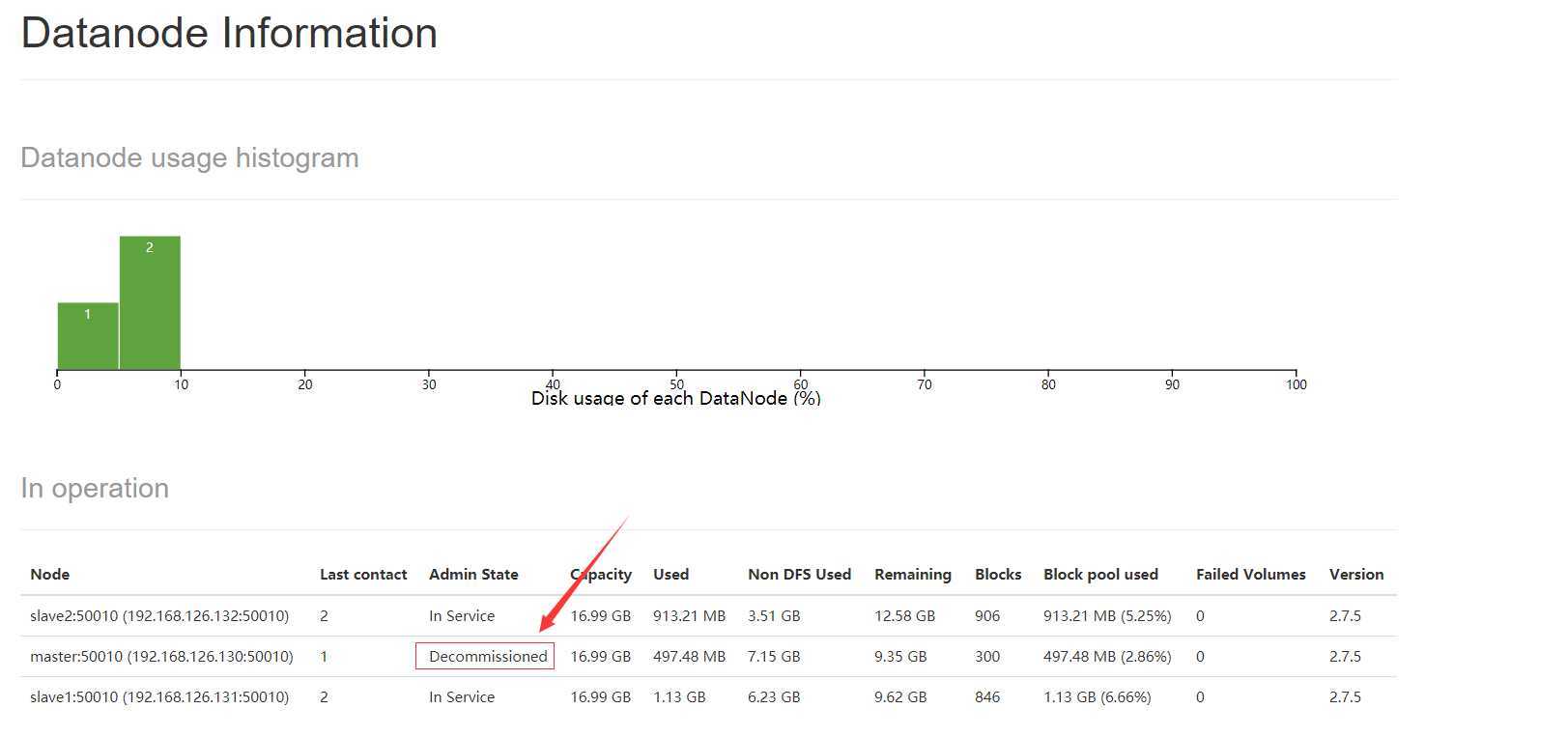
4. 在master上停止DataNode:
hadoop-daemon.sh stop datanode
5.刷新DataNode:
hdfs dfsadmin -refreshNodes
以上是关于HDFS集群中DataNode的上线与下线的主要内容,如果未能解决你的问题,请参考以下文章
格式化hdfs后,hadoop集群启动hdfs,namenode启动成功,datanode未启动