IDEA15 下运行Scala遇到问题以及解决办法
Posted 尧字节
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IDEA15 下运行Scala遇到问题以及解决办法相关的知识,希望对你有一定的参考价值。
为了让Scala运行起来还是很麻烦,为了大家方便,还是记录下来:
1、首先我下载的是IDEA的社区版本,版本号为15.
2、下载安装scala插件:
2.1 进入设置菜单。
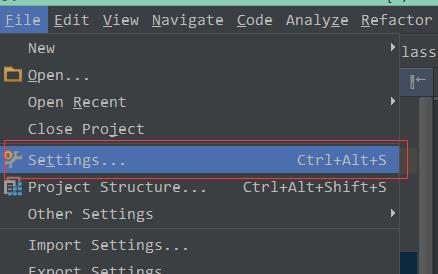
2.2 点击安装JetBrains plugin
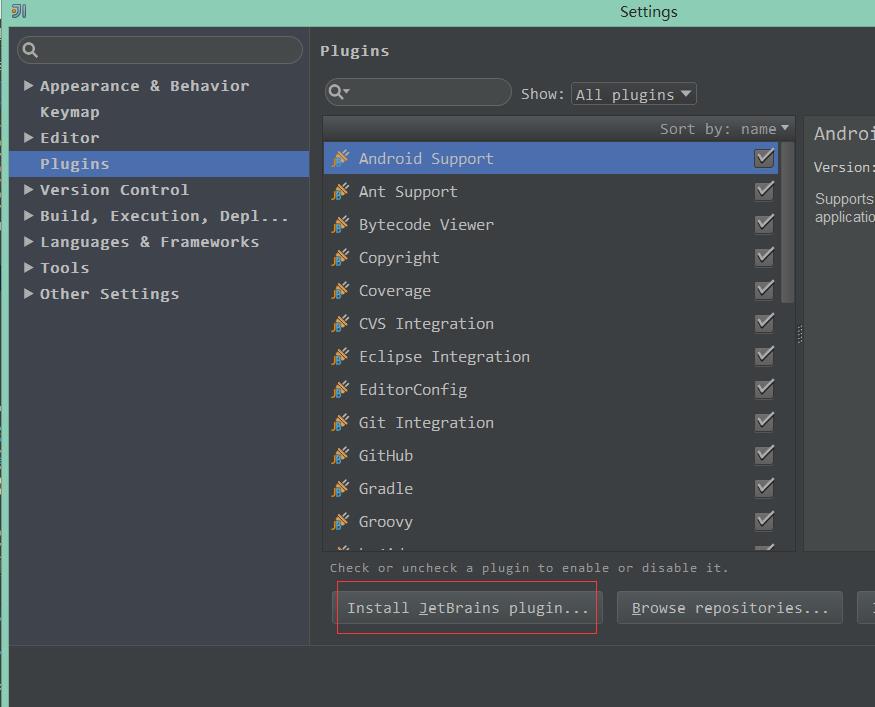
2.3 输入scala查询插件,点击安装
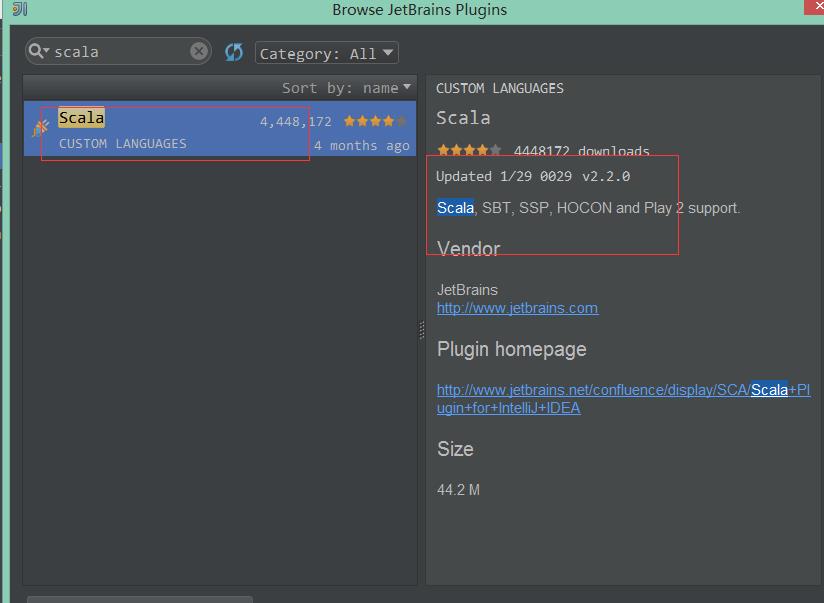
说明:我的IDEA已经安装,所以这里面没有显示出来安装按钮,否则右边有显示绿色按钮。
3、新建Scala工程
3.1 新建工程
通过菜单:File----》New Project 选择Scala工程。
并且设置项目基本信息,如下图:

3.2 设置Modules
1)点击右上角的方块:
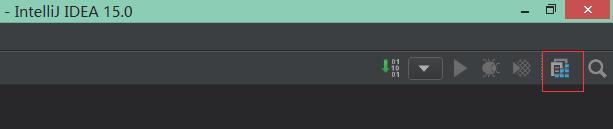
2)在左边选择Libraries---》+---》Scala SDK--》选择版本为2.10.4
说明:如果不存在这个版本可以通过左下角的download去下载。
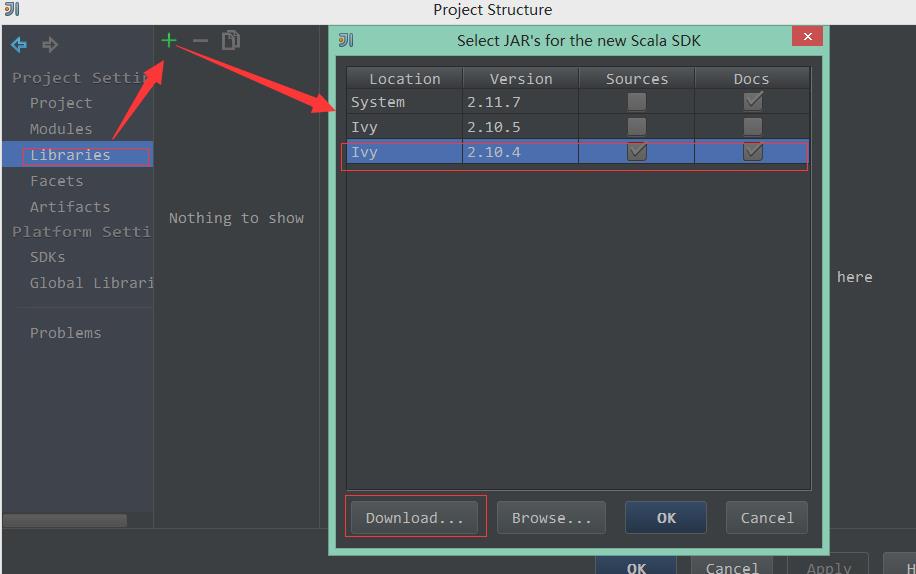
3)选择添加Java的Jar文件,选择Spark和Hadoop关联的Jar
我这里添加的是:spark-assembly-1.6.1-hadoop2.6.0.jar 这个是spark安装时候自带的lib里面有,很大。
定位到jar所在的目录后,刷新,选择这个文件,点击OK,会花费比较长时间建索引。
4)在Src源码目录新建文件:WordCount.scala
且输入如下代码:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.SparkContext._
object WordCount {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage:<File>")
System.exit(1)
}
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
val line = sc.textFile(args(0))
val words = line.flatMap(_.split("")).map((_, 1))
val reducewords = words.reduceByKey(_ + _).collect().foreach(println)
sc.stop()
}
}
5)编译运行:
需要输入参数,所以要设置下相关参数信息:
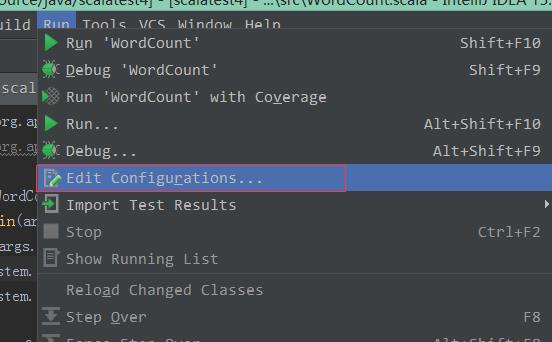
随便复制个文件过去,然后设置下:
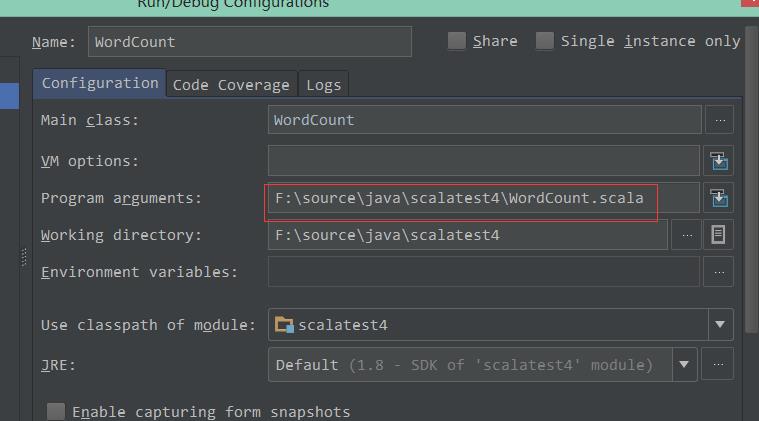
- 抛出异常:
Exception in thread "main" org.apache.spark.SparkException: A master URL must be set in your configuration
at org.apache.spark.SparkContext.<init>(SparkContext.scala:401)
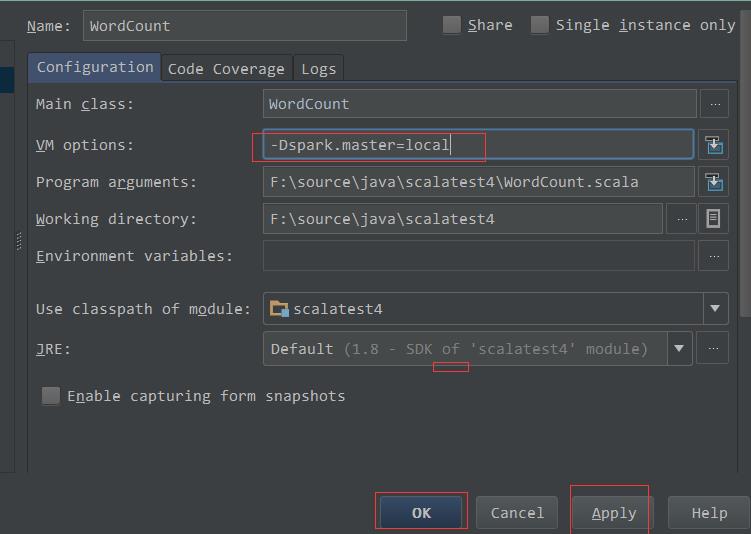
解决办法:需要设置下SparkContext的地址:
- 抛出异常:
16/06/25 12:14:18 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\\bin\\winutils.exe in the Hadoop binaries.
解决办法:
http://stackoverflow.com/questions/19620642/failed-to-locate-the-winutils-binary-in-the-hadoop-binary-path
可能是因为我没有安装hadoop的原因,设置下相关信息就可以:
下载:
<a href="http://www.srccodes.com/p/article/39/error-util-shell-failed-locate-winutils-binary-hadoop-binary-path">Click here</a>
设置:HADOOP_HOME为下载后解压内容的上级目录,然后在PATH里面添加%HADOOP_HOME%/bin;
4、其他异常
1)异常内容:类或Object XXX已经被定义
解决办法: 这个可能是工程里面设置了两个source目录,需要删除一个。
2)异常内容:sparkContext.class 依赖不存在
解决办法:需要引入hadoop的jar包,我这里是:spark-assembly-1.6.1-hadoop2.6.0.jar
3)异常内容:Error:(17, 29) value reduceByKey is not a member of org.apache.spark.rdd.RDD[(String, Int)]
解决办法: 导入这个: import org.apache.spark.SparkContext._
4)异常内容:Exception in thread "main" java.lang.NoClassDefFoundError: com/google/common/util/concurrent/ThreadFactoryBuilder
解决办法:添加依赖Jar :guava-11.0.2.jar
5)异常内容:Exception in thread "main" java.lang.NoSuchMethodError: scala.collection.immutable.HashSet$.empty()Lscala/collection/immutable/HashSet;
解决办法:更改scala-sdk版本为2.10,如果没有通过如下方式下载:(速度奇慢)
5、打包成Jar
1、设置下导出Jar信息:
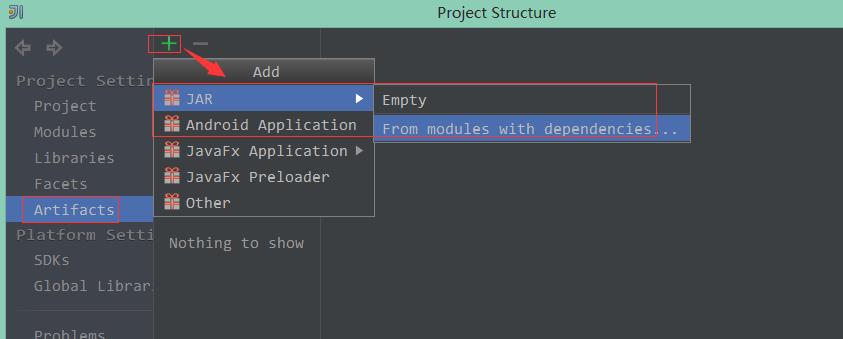
2、设置导出的工程还导出的Main类:
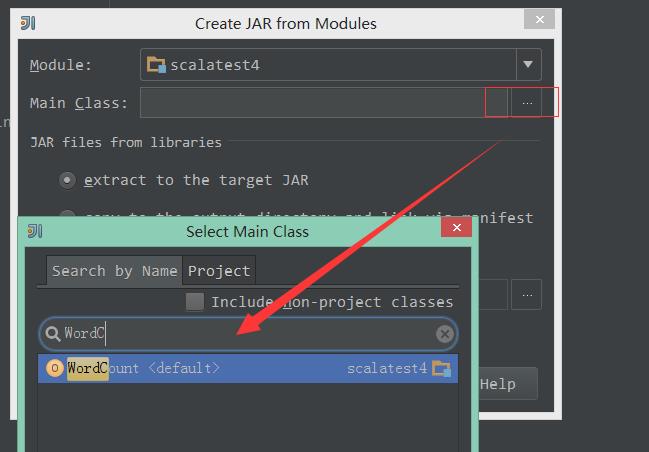
3、通过选择点击-号删除其他依赖的class
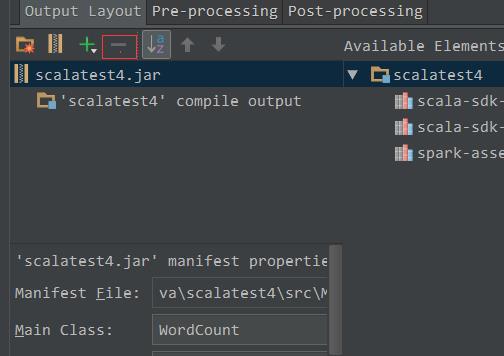
4、导出Jar包:
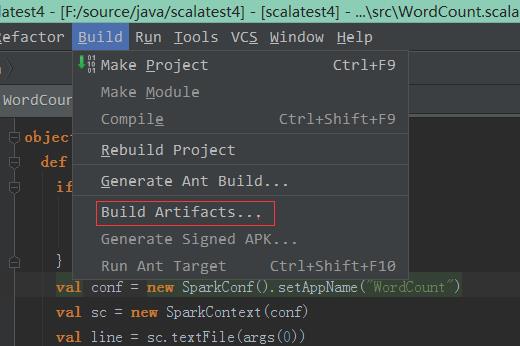
5、上传后执行Jar包
./spark-submit --master spark://inas:7077 --class WordCount --executor-memory 512m /home/hadoop/sparkapp/scalatest4.jar hdfs://inas:9000/user/hadoop/input/core-site.xml
说明: hadoop文件为以前新建的,在提交之前需要先启动hadoop再自动spark,然后再用以上办法提交。
启动Hdfs: ./start-dfs.sh
启动spark:./sbin/start-all.sh(没试过)
可以通过如下方法启动:
~/project/spark-1.3.0-bin-hadoop2.4 $./sbin/start-master.sh
~/project/spark-1.3.0-bin-hadoop2.4 $./bin/spark-class org.apache.spark.deploy.worker.Worker spark://inas:7077
注意:必须使用主机名
启动模式为standaline模式。
Spark Standalone Mode 多机启动,则其他主机作为worker启动,设置master主题。
以上是关于IDEA15 下运行Scala遇到问题以及解决办法的主要内容,如果未能解决你的问题,请参考以下文章
scala配置intellij IDEA15.0.3环境及hello world!
mavan下scala编译中文乱码的问题.以及内存溢出问题解决
Intellij idea: java.lang.ClassNotFoundException:javax.el.ELResolver异常解决办法