实现与提高算法设计能力的一般方法
Posted tkzc2013
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实现与提高算法设计能力的一般方法相关的知识,希望对你有一定的参考价值。
1,确定函数名字与原型
1,确定函数名字与原型
一旦拿到有关算法的问题,那么就应该分析问题,找到对应的输入输出,从而确定出算法的函数原型。我们写算法,其实就是写一个或者若干个普通的函数(而不是main函数)。因此,需要分析出,应该传什么参数给函数(作为输入参数),函数处理完后,应该把什么数据作为结果返回(作为输出参数)。最后还要给函数取一个符合算法意义的名字,名字最好用英语表示,如果用拼音,会显得特别山寨的感觉。函数的命名方式与变量的命名方式都有相关的约定,比如匈牙利命名法,Linux命名法或者驼峰命名法等。
比如,有这么一个典型的算法问题:将一个字符串逆置,比如:”hello world”-->”dlrow olleh”
对于这道题,我们分析之后,应该知道,输入是一个普通的字符串,输出是将这个字符串逆置之后的字符串,因此,可以确定函数的原型:
void reverse_str(char *str);//str既是输入,也是输出 //或者 void reverse_str(char *str, size_t len)//str既是输入又是输出,len是字符串的长度
很多初学者在这里容易犯的错误包括:只对字符串“hello world”进行了逆置而忽视了算法解决的是通用的一般性问题,或者把相关的代码直接写在了main()函数里。
此外,就是需要有模块化的思想。一个函数只单独完成一个单一的功能,函数的代码行数一般很少超过100行,加上注释不会超过300行。 因此,要把那些频繁使用而功能又比较单一的代码放在一个独立的函数里。不要在一个函数里完成N个功能,这不利于调试和维护,也和模块化是相背离的。
2,严进宽出
确定好了函数的原型之后,紧接着在完成这个函数的功能一开始的地方,就需要严格判断函数输入参数的合法性,我们称之为:严进宽出。具体点说,就是要判断函数参数中的指针是否为NULL,函数参数中缓存的长度是否在合理范围。这一点非常的重要。
比如同样对于第1点里的函数原型,那么我们就需要作出如下的判断:
void reverse_str(char *str, size_t len) /*首先判断str指针是否为NULL或者len是否为0和1,这些都是特殊情况或者非法输入,因此要严格检查,严进宽出。*/ if(str== NULL || *str==‘\\0‘|| len==0 || len==1) return; //程序如果执行到这里,那么参数检测就完成了并合法了。因此可以继续完成相应的功能了。 ......
严进宽出是写程序的一个非常好的习惯,可以避免程序在运行中出错,甚至避免各种严重漏洞的产生。比如曾经十分严重的SSL协议中的心脏流血漏洞,就是因为服务端程序在处理的时候,没有验证来自客户端对应的缓存长度的有效性,而造成了该漏洞的产生。
3,边界考虑
边界考虑就是要考虑程序中各种各样的特殊情况,而不是只考虑其中的一种情况。我们在写算法的时候,经常会忘记多种情况的周全考虑,而忽略了很多特殊的情况,对程序的健壮性带来影响。
1.边界条件是指软件计划的操作界限所在的边缘条件。
数据类型:数值、字符、位置、数量、速度、地址、尺寸等,都会包含确定的边界。应考虑的特征:第一个/最后一个、开始/完成、空/满、最慢/最快、相邻/最远、最小值/最大值、超过/在内、最短/最长、最早/最迟、最高/最低。这些都是可能出现的边界条件。边界条件测试通常是对最大值简单加1或者很小的数和对最小值减少1或者很小的数,例如:
l 第一个减1/最后一个加1;
l 开始减1/完成加1;
l 空了再减/满了再加;
l 慢上加慢/快上加快;
l 最大数加1/最小数减1;
l 最小值减1/最大值加1;
l 刚好超过/刚好在内;
l 短了再短/长了再长;
l 早了更早/晚了更晚;
l 最高加1/最低减1。
另一些该注意的输入:默认,空白,空值,零值和无;非法,错误,不正确和垃圾数据。根据边界来选择等价分配中包含的数据。然而,仅仅测试边界线上的数据点往往不够充分。提出边界条件时,一定要测试临近边界的合法数据,即测试最后一个可能合法的数据,以及刚超过边界的非法数据。
2.默认值测试(默认、空白、空值、零值和无)
好的软件会处理这种情况,常用的方法:一是将输入内容默认为合法边界内的最小值,或者合法区间内某个合理值;二是返回错误提示信息。
这些值在软件中通常需要进行特殊处理。因此应当建立单独的等价区间。在这种默认下,如果用户输入0或-1作为非法值,就可以执行不同的软件处理过程。
3.破坏测试(非法、错误、不正确和垃圾数据)
数据测试的这一类型是失败测试的对象。这类测试没有实际规则,只是设法破坏软件。不按软件的要求行事,发挥创造力吧。
举一个例子:实现C库中的memmove函数.举一个例子,很多程序员可能会很快写出如下程序:
void memcpy(void *pDst,const void *pSrc, size_t size) assert(pDst != NULL); assert(pSrc != NULL); char *pstrSrc= (char *)pSrc ; char *pstrDst = (char *)pDst ; /* 从起始部正向拷贝 */ while(size--) *pstrDst++ = *pstrSrc++;
但是,这里忽略了一个很重要的情况就是:pDst和pSrc指定的内存有可能是重叠的。如果按照这样拷贝的话,那么如果:
(pSrc<pDst) && ((char*)pSrc+size > pDst)
那么,按照上面的程序代码拷贝,将会把pSrc尾巴部分的数据覆盖污染了。
因此,必须清楚的考虑pSrc和pDst二者之间的关系,采取不同的算法,实际上,pSrc和pDst的位置关系有如下图4种情况,其中第2种情况,需要特殊处理。
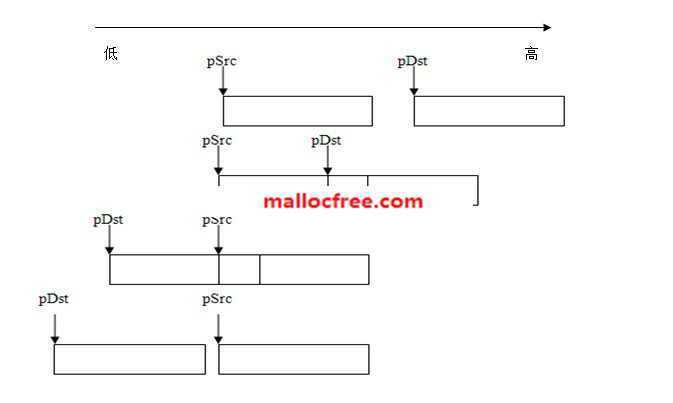
如上图的位置关系所示,在第2种位置中,也就是当(pSrc<pDst) && ((char*)pSrc+size > pDst)时,从前往后拷会有问题。必须从后往前面拷贝:
void memcpy(void *pDst,const void *pSrc, size_t size) assert(pDst != NULL); assert(pSrc != NULL); /* pSrc与pDst共享同一块内存区域 */ if((pSrc<pDst) && ((char*)pSrc+size > pDst)) char *pstrSrc= (char *)pSrc + size -1; char *pstrDst = (char *)pDst + size -1; / * 从尾部逆向拷贝 */ while(size--) *pstrDst -- = *pstrSrc--; else char *pstrSrc= (char *)pSrc ; char *pstrDst = (char *)pDst ; /* 从起始部正向拷贝 */ while(size--) *pstrDst++ = *pstrSrc++;
4,出错处理
出错处理,是指当代码在执行过程中,如果发生了异常或者错误,就必须要处理,否则程序就无法继续执行了,如果强制继续执行,往往可能会导致程序或者系统崩溃。
比如我们在打开文件的时候,如果文件不存在或者打开失败了;在分配内存的时候,返回内存为NULL,这些情况都需要及时处理。一般处理程序错误或者异常的方法有goto err或者try_except等方式。
出错处理的方式方式很多,也很灵活。只要不遗漏对错误的处理就行。现在介绍两种错误处理方式:
1)goto error方式
语句goto是大家不大喜欢使用的,也是程序设计专家建议不要使用的一句话。因此goto语句似乎就要退出历史的舞台。但幸好它找到了一个用武之地,那就是用goto error方式来处理出错。下面是一个例子:
NTSTATUS QueryObjectName(HANDLE h) int ret; NTSTATUS st; char *str = "Hello, how are u?"; char *pstr = (char *)malloc(256); if (pstr == NULL) printf("No more memory\\n"); goto Error; int len = strlen(str)>255?255:strlen(str); strncpy(pstr, str, len); pstr[len+1] = ‘\\0‘; char *namebuf = (char *)malloc(1024); if (buf == NULL) printf("No more memory\\n"); goto Error; st = NtQueryObject(h, FileNameInformation, namebuf, ret, NULL); if (!NT_SUCCESS(st)) printf("No more memory\\n"); goto Error; ... Error: if (buf) free(buf); if (pstr) free(pstr); return st;
goto error方式把错误进行了集中处理,防止了在分支复杂的程序中错误情况的遗漏。
2)SHE:__try__leave__exception方式
SEH( structured exception handling ),即结构化异常处理方式,它是Windows系统独有的异常处理模型,主要由try-except语句来完成,与标准的try-catch相似。C++异常处理模型使用catch关键字来定义异常处理模块,而SEH是采用except关键字来定义;catch关键字后面像接受一个函数参数一样,可以是各种类型的异常数据对象,except关键字则不同,它后面跟的是一个表达式。
NTSTATUS QueryObjectName(HANDLE h) int ret; NTSTATUS st; __try char *str = "Hello, how are u?"; char *pstr = (char *)malloc(256); if (pstr == NULL) printf("No more memory\\n"); __leave; int len = strlen(str)>256?256:strlen(str); strncpy(pstr, str, len); pstr[strlen(str)] = ‘\\0‘; char *namebuf = (char *)malloc(1024); if (buf == NULL) printf("No more memory\\n"); __leave; st = NtQueryObject(h, FileNameInformation, namebuf, ret, NULL); if (!NT_SUCCESS(st)) printf("NtQueryObject failed\\n"); __leave; __except(EXCEPTION_EXECUTE_HANDLER) //获得异常代码 st = GetExceptionCode(); if (buf) free(buf); if (pstr) free(pstr); return st;
5,性能优化(时间复杂度,空间复杂度)
大家有时候去参加面试,自我感觉良好,面试官出的算法题,自己感觉也做出来了,也做对了,可为什么面试结束后,迟迟等不来Offer呢?那就很可能是因为你的算法题虽然做出来了,但不是最优的。
总的来说,衡量算法的优劣有2种标准:时间复杂度和空间复杂度。简单的来说,所谓时间复杂度,就是嵌套的循环越少越好,比如一层循环优于二层循环,面试中一般很少有三层循环的算法;而所谓空间复杂度,就是尽量不要调用malloc或者new来分配额外的内存。复杂度可以用O()来表示,它们之间的效率关系为:
O(1)>O(n)>O(nlogn)>O(n²)>O(2^n)
对于第1点中的字符串逆置的问题,有如下2种解决方法:
//算法1:直接基于str所在内存进行逆置 void reverse_str(char* str, size_t len) if (NULL == str || ‘\\0‘ == *str || 0==len || 1==len) return; char *p1=str; char *p2=str+len-1; while(p1<p2) char c = *p1; *p1 = *p2; *p2 = c; p1++; p2--; //算法2,分配一个额外的内存,把字符串从后往前拷贝到内存中 char *reverse_str(char* str, size_t len) if (NULL == str || ‘\\0‘ == *str || 0==len || 1==len) return; char *buf=malloc(len+1); char *p2=str +len-1; char *p1=buf; if(buff == NULL) return NULL; memset(buf, 0,len+1); while(len--) *p1++=*p2--; return buf;
2种解法都能够完成把字符串逆置的任务。但是,第二种算法,额外分配了内存(复杂度为O(n)),空间复杂度上第一种占据了优势。
空间复杂度很好理解。而时间复杂度,想要容易的写出O(n)或者O(1)的算法,就需要仔细思考问题和设计算法了,并且还应该学习一些常见的算法技巧。比如:2个指针跑步,比如hash算法,比如递归等,详见下面的方法总结。
思考题:用尽量高效的方法(比如O(1))来删除单向非循环链表中的某个结点。
原型:bool delete_node(node *&head, node *p)
6,循环的掌握
一个再复杂的算法程序,都是由循环,条件,顺序三种语句构成的(switch语句也可以转化为条件语句)。而这三种语句中,循环语句的使用是其中的关键。循环语句用来遍历和操作对应的数据结构。前几节中,几乎每个算法都用到了循环语句。以循环语句为核心,循环语句把其他语句联系起来。因此,算法中,最重要的地方就是对循环的熟练掌握与使用。
下面把常用的各种数据结构的循环语句列出,方便大家在编程的时候使用:
1.数组
for (int i = 0; i < n; i++) printf(“%d\\n”, a[i]);
2.字符串
while (*str !=’\\0’) str++;
3.链表
while (p) p = p->next;
4.栈空/栈满/队空/队满
while(栈非空) 出栈; 操作出栈元素
5.指针大小比较
while (pStart < pEnd) pStart++;
6.数为正
while (size--) //或 do while(size--)
7.反复循环直到条件成熟
while(1) if (something is true) break;
熟练各种循环语句的写法,为实现各种复杂的算法奠定了基础。因此,要在各种循环语句上下功夫,达到熟练书写,灵活运用的程度。
7,递归的应用
对于一些复杂的算法问题,还可以通过递归的思想来解决。有的问题,用传统的方法来解决,显得很复杂。这个时候,可以考虑是不是可以用递归来解决。因为用递归的思想解决问题,既简单,又清晰,往往让看似复杂的问题得到简单解决的可能。
笔者曾经在面试微软的时候遇到考官考查了一道树的结点和它的兄弟之间的关系问题。开始我试着用队列结合树的遍历去解决这个问题,但是发现如果那样去解决会显得很麻烦,最后能否行得通也还是一个问题。而当时面试官也提醒我,一旦确定了思路,就不能再改变。于是我发现原来的想法显得很复杂,还有可能陷入死胡同。
于是我决定放弃原来的思路,重新分析问题。经过我的重新分析,结合以往的经验,对于树的问题,几乎都可以考虑用递归的方法去实现,笔者按照递归的方法,首先分析了这个问题最简单的情况(即递归的出口),然后再对复杂的情况利用递归方法调用它自身。思路越来越清晰,我便开始动手写在纸上写起代码来。没过多久,代码就完成了,并交给了面试官。面试官看完代码后,很满意的点点头。问题最终得到圆满的解决。
题目:用一条语句,不声明临时变量,实现strlen来计算一个字符串的长度。
如strlen(“hello world”)=11
size_t strlen (const char * str )//常规方法 const char *eos = str; while( *eos++ ) ; return( eos - str - 1 ); size_t strlen(const char *str)//递归方法 return (str==NULL || *str==’\\0’)?0:1+strlen(str+1);
题目:将一个字符串逆置。
比如:”hello world”-->”dlrow olleh”
void reverse_str(char* str, unsigned int len)//常规方法 if (NULL == str) return; char *p1=str; char *p2=str+len-1; while(p1<p2) char c = *p1; *p1 = *p2; *p2 = c; p1++; p2--; void reverse_str(char *str, size_t len)//递归方法 if(len==0 || len==1 || str == NULL || *str==‘\\0‘) return; char tmp = str[0]; str[0]=str[len-1]; str[len-1]=tmp; reverse_str(str+1, len-2);
递归算法的关键是找到递归的出口和递归公式。
8,2个指针跑步
2个指针跑步法,是麦洛克菲在算法教学过程中总结的一个很好的编程方法。就是在算法实现过程中,我们可以定义2个指针,一前一后,或者相向而行,同时遍历对应的数据结构(如数组,链表,字符串等),在遍历过程中解决对应的问题。在大量的名企面试题中,都可以使用该方法来解决并降低算法的复杂度。下面的例子详细的描述了这个方法的使用方法:
题目1:计算一个链表的中间节点。
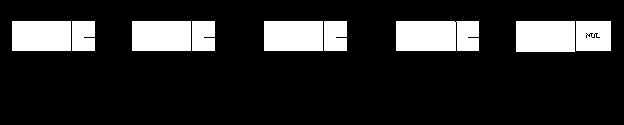
思路:定义2个指针,一个跑2步,一个跑1步,当跑2步的到链表终点,跑1步的正好到达中间结点
node * find_list_middle_node(node * list) if(list == NULL || list->next == NULL) return list; node *p1 = list; node *p2 = list; while(p1&&p2&&p2->next) p1=p1->next; p2=p2->next->next; if(p2->next==NULL || p2==NULL) return p1;
题目2:判断一个单向链表是否存在循环。
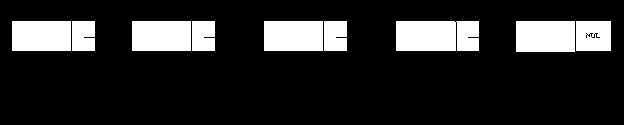
思路:定义2个指针,一个指针跑一步,一个指针跑2步;如果2个指针相遇,就存在循环,否则不存在循环。
int find_loop(node *head) node *p = NULL; node *q = NULL; if (head == NULL) return 0; p = head; q = head->next; while (p!=NULL && q!=NULL&&q->next!=NULL&&p!=q) p = p->next; q = q->next->next if (p==q) return 1; else return 0;
题目3:从一个字符串中删除某一个特定的字符。
如:”hello world”,’o’-->”hell wrld”
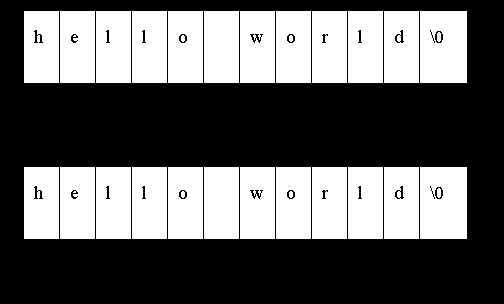
思路:定义2个指针,一个是读指针,一个是写指针。读指针从头到尾扫描字符串,遇到不需要删除的字符,传递给写指针保存对应的字符,如果遇到要删除的字符直接忽略。
char* del_char(char *str,char ch) char *p1=str,*p2=str; if(NULL==str) return NULL; while(*p2!=‘\\0‘) if(*p2!=ch) *p1++=*p2++; else p2++; *p1=‘\\0‘; return str;
9. Hash算法
Hash算法一般是用一个hash数组来记录一个key对应的有无或者统计对应的个数,用key作为hash数组的下标,而下标对应的值用来表示该key的存在与否以及统计对应的个数。
例1:请编写一个高效率的函数来找出字符串中的第一个无重复字符。例如,"total"中的第一个无重复字符上一"o"
char find_first_single_char(const char *str) int tmp[256]=0;//hash数组 char *s= (char *)str; while(*s!=‘\\0‘) tmp[*s]++; s++; s=(char*)str; while(*s!=‘\\0‘) if(tmp[*s]==1) return *s; s++; return ‘\\0‘;
例2:找出一系列整数(都小于65536)中存在的重复数字。
#define MAXMUM 65536 void find_repeated_number(int a[], in n) int tmp[MAXMUM];//hash数组 int i; for (i = 0; i < MAXMUM; i++) tmp[i] = 0; for (i = 0; i < n; i ++) tmp[a[i]]++; for (i = 0; i < MAXMUM; i++) if (tmp[i]>1) printf(“%d:%d”, i, tmp[i]);
以上是关于实现与提高算法设计能力的一般方法的主要内容,如果未能解决你的问题,请参考以下文章