mapreduce案例:获取PI的值
Posted 2016-zck
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mapreduce案例:获取PI的值相关的知识,希望对你有一定的参考价值。
mapreduce案例:获取PI的值
* content:核心思想是向以(0,0),(0,1),(1,0),(1,1)为顶点的正方形中投掷随机点。
* 统计(0.5,0.5)为圆心的单位圆中落点占总落点数的百分比,即可算出单位圆的面积Pi/4,
* 然后乘以4即得到Pi的近似值。从输入文件中读入一行内容。每一行都是一个数字,
* 代表随机投掷那么多点来估算Pi的值。在Mapper中则随机生成指定数量的随机点(x,y)。
* x和y的范围在0-1之间。然后求出(x,y)与(0.5,0.5)的距离。
* 如果超过0.5,则输出
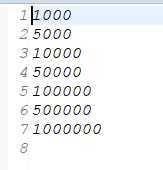
输入的文件内容:即进行的次数
package com.hadoop.Pi; import java.io.IOException; import java.util.Random; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.DoubleWritable; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /* * @author:翟超科 * time:2019.9.3 * content:核心思想是向以(0,0),(0,1),(1,0),(1,1)为顶点的正方形中投掷随机点。 * 统计(0.5,0.5)为圆心的单位圆中落点占总落点数的百分比,即可算出单位圆的面积Pi/4, * 然后乘以4即得到Pi的近似值。从输入文件中读入一行内容。每一行都是一个数字, * 代表随机投掷那么多点来估算Pi的值。在Mapper中则随机生成指定数量的随机点(x,y)。 * x和y的范围在0-1之间。然后求出(x,y)与(0.5,0.5)的距离。 * 如果超过0.5,则输出 * */ public class Pi public static class PiMapper extends Mapper<Object, Text, Text, IntWritable> //生成一个0-1的随机数 private static Random rd = new Random(); //执行map public void map(Object key, Text value, Context context ) throws IOException, InterruptedException //实验进行pointNum次 int pointNum = Integer.parseInt(value.toString()); for(int i = 0; i < pointNum; i++) // 取随机数 double x = rd.nextDouble(); double y = rd.nextDouble(); // 计算与(0.5,0.5)的距离,如果小于0.5就在单位圆里面 x -= 0.5; y -= 0.5; double distance = Math.sqrt(x*x + y*y); //如果随机点在圆外,定义结果是0,否则为1 IntWritable result = new IntWritable(0); if (distance <= 0.5) result = new IntWritable(1); //将键值对交给reduce处理 context.write(value, result); public static class PiReducer extends Reducer<Text,IntWritable,Text,DoubleWritable> //定义结果变量 private DoubleWritable result = new DoubleWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException double pointNum = Double.parseDouble(key.toString()); double sum = 0; //求结果等于1的和 for (IntWritable val : values) sum += val.get(); //结果*4即为PI值 result.set(sum/pointNum*4); //输出结果到输出文件目录 context.write(key, result); public static void main(String[] args) throws Exception Configuration conf = new Configuration(); Job job = Job.getInstance(conf,"calculate pi"); job.setJarByClass(Pi.class); job.setMapperClass(PiMapper.class); job.setReducerClass(PiReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(DoubleWritable.class); FileInputFormat.addInputPath(job, new Path("hdfs://192.168.13.101:9000/pi"));//输入文件目录 FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.13.101:9000/output2"));//输出文件目录 System.exit(job.waitForCompletion(true) ? 0 : 1);
以上是关于mapreduce案例:获取PI的值的主要内容,如果未能解决你的问题,请参考以下文章