监督学习之模型评估与选择
Posted wjh123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了监督学习之模型评估与选择相关的知识,希望对你有一定的参考价值。
一、定义:
监督学习主要包括分类和回归
当输出被限制为有限的一组值(离散数值)时使用分类算法
当输出可以具有范围内的任何树值(连续数值)时使用回归算法
相似度学习是和回归和分类都密切相关的一类监督学习,它的目的是使用相似函数从样本中学习,这个函数可以度量两个对象之间的相似度或关联度
二、监督学习三要素
模型:总结数据的内在规律,用数据函数描述的系统
策略:选取最优模型的评价准则
算法:选取最优模型的具体方法
三、模型评估:
1、训练集和测试集
- 训练集(training set):训练模型的数据
- 测试集(test set):测试模型的好坏
2、损失函数和经验风险
a、损失函数(loss function):用来度量偏差的程度,记作:L(Y,f(X)). Y为真实结果,f(X)为预测结果,
- 损失函数是模型里面系数的函数
- 损失函数值越小,模型就越好。
- 常见的损失函数:

b、经验风险(Empirical risk):模型f(X)关于训练数据集的平均损失。
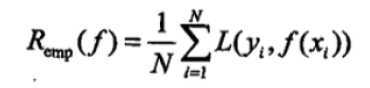
经验风险最小化(Empirical risk Minimization ERM):经验风险最小的模型就是最优模型。【样本足够大时,ERM的学习有很好的效果】
3、训练误差和测试误差
训练误差:关于训练集的平均损失
测试误差:关于测试集的平均损失,反映了模型对未知数据的预测能力,这种能力称为泛化能力。
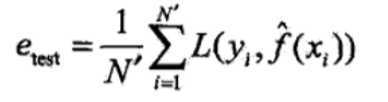
四、模型选择:
1、过拟合和欠拟合
- 过拟合:特征集过大,把噪声数据的特征也学习到了,不能很好地识别数据,不能正确的分类
- 欠拟合:特征集过小,导致模型不能很好地拟合数据【对数据的特征学习得不够】
2、正则化和交叉验证
a、正则化(防止过拟合):将结构风险最小化(Structural rick Minimization SRM )的过程。
在经验风险上加上表示模型复杂度的正则化项(regularizer),或者叫惩罚项。
正则化项:一般是模型复杂度的单调递增函数,即模型越复杂,正则化值越大。

b、交叉验证:数据集不足时,可以重复地利用数据。
- 简单交叉验证
- S折交叉验证
- 留一交叉验证
以上是关于监督学习之模型评估与选择的主要内容,如果未能解决你的问题,请参考以下文章