边缘缓存模式(Cache-Aside Pattern)
Posted meteorseed
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了边缘缓存模式(Cache-Aside Pattern)相关的知识,希望对你有一定的参考价值。
边缘缓存模式(Cache-Aside Pattern),即按需将数据从数据存储加载到缓存中。此模式最大的作用就是提高性能减少不必要的查询。
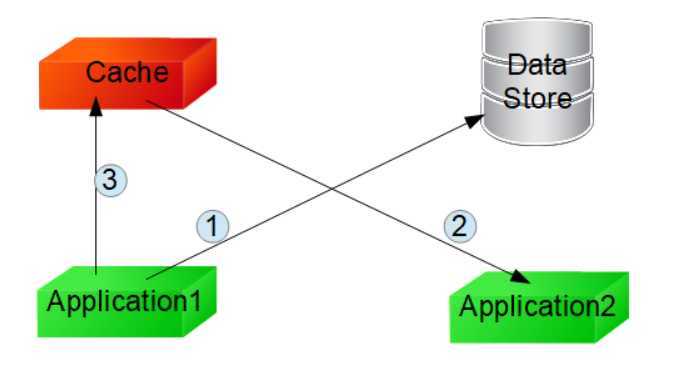
1 模式
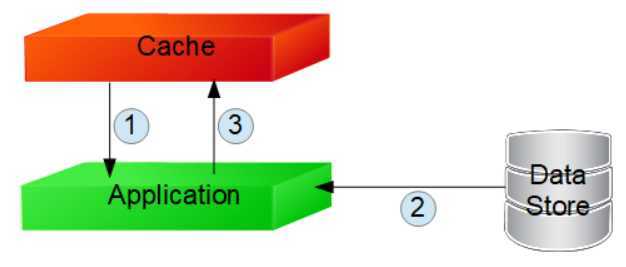
- 先从缓存查询数据
- 如果没有命中缓存则从数据存储查询
- 将数据写入缓存
代码形如:
public async Task<MyEntity> GetMyEntityAsync(int id) // Define a unique key for this method and its parameters. var key = string.Format("StoreWithCache_GetAsync_0", id); var expiration = TimeSpan.FromMinutes(3); bool cacheException = false; try // Try to get the entity from the cache. var cacheItem = cache.GetCacheItem(key); if (cacheItem != null) return cacheItem.Value as MyEntity; catch (DataCacheException) // If there is a cache related issue, raise an exception // and avoid using the cache for the rest of the call. cacheException = true; // If there is a cache miss, get the entity from the original store and cache it. // Code has been omitted because it is data store dependent. var entity = ...; if (!cacheException) try // Avoid caching a null value. if (entity != null) // Put the item in the cache with a custom expiration time that // depends on how critical it might be to have stale data. cache.Put(key, entity, timeout: expiration); catch (DataCacheException) // If there is a cache related issue, ignore it // and just return the entity. return entity; public async Task UpdateEntityAsync(MyEntity entity) // Update the object in the original data store await this.store.UpdateEntityAsync(entity).ConfigureAwait(false); // Get the correct key for the cached object. var key = this.GetAsyncCacheKey(entity.Id); // Then, invalidate the current cache object this.cache.Remove(key); private string GetAsyncCacheKey(int objectId) return string.Format("StoreWithCache_GetAsync_0", objectId);
2 关注点
2.1 缓存数据的选择
对于相对静态的数据或频繁读取的数据,缓存是最有效的。
2.2 缓存数据的生命周期
过期时间短,会导致频繁查询数据源而失去缓存的意义;设置时间过长,可能发生缓存的数据过时不同步的情况。
2.3 缓存过期策略的选择
一般缓存产品都有自己内置的缓存过期策略,最长使用的是“最近最不常使用”算法,需要在使用时,了解产品的默认配置和可配置项,根据实际需求选择。
2.4 本地缓存与分布式缓存的选择
本地缓存的查询速度更快,但在一个分布式环境中,需要保证不同机器的本地缓存统一,这需要我们在程序中处理;分布式缓存性能不如本地缓存,但大多数时候,分布式缓存更适合大型项目,分布式缓存产品家族自带的管理和诊断工具十分适合运维和性能监控。
2.5 一致性问题
实现边缘缓存模式不能保证数据存储和缓存之间的实时一致性。数据存储中的某个项可能随时被外部进程更改,并且此更改可能在下次将项加载到缓存中之前不会反映在缓存中。
3 一致性
3.1 淘汰还是更新缓存
淘汰缓存:数据写入数据存储,并从缓存删除
优点:简单
缺点:缓存增加一次miss,需要重新加载数据到缓存
更新缓存:数据写入数据存储,并更新缓存
优点:缓存不会增加一次miss,命中率高
缺点:更新缓存比淘汰缓存复杂
淘汰还是更新缓存主要取决于——更新缓存的复杂度,数据查询时间以及更新频率。
如果更新缓存复杂度低,从数据存储查询查询数据有比较耗时,更新频率又高,则为了保证缓存命中率,更新缓存比较适合。此外大大多数情景,都可以用淘汰缓存,来满足需求。
3.2 操作顺序
先操作数据存储,再操作缓存
先操作缓存,再操作数据存储
3.3 一致性问题
非并发场景——场景为Application修改数据(考虑操作失败的影响)
先操作缓存,再操作数据存储
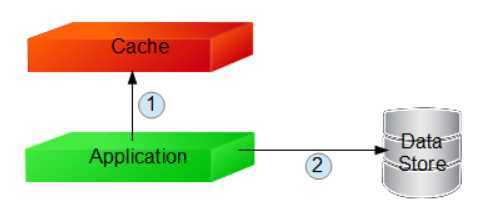

淘汰缓存时:
step 1:淘汰缓存成功
step 2:更新数据存储失败
结果:数据存储未修改,缓存已失效
修改缓存时:
step 1:修改缓存成功
step 2:更新数据存储失败
结果:数据不一致
先操作数据存储,再操作缓存
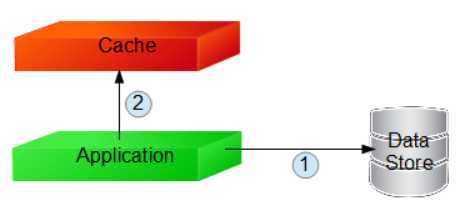

淘汰缓存时:
step 1:更新数据存储成功
step 2:淘汰缓存失败
结果:数据不一致
修改缓存时:
step 1:更新数据存储成功
step 2:修改缓存失败
结果:数据不一致
并发场景——场景位Application1修改数据,Application2读取数据,(不考虑操作失败的影响,仅考虑执行顺序的影响)
先操作缓存,再操作数据存储
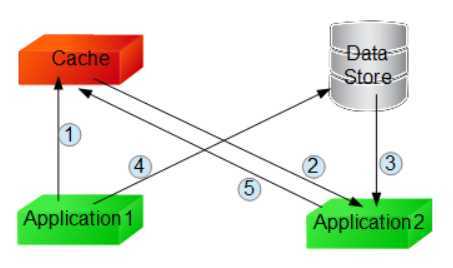

淘汰缓存时:
step 1:Application1先淘汰缓存
step 2:Application2从缓存读取数据,但是没有命中缓存
step 3:Application2从数据存储读取旧数据
step 4:Application1完成数据存储的更新
step 5:Application2把旧数据写入缓存,造成缓存与数据存储不一致
结果:数据不一致
更新缓存时:
step 1:Application1先更新缓存
step 2:Application2从缓存读取到新数据
step 3:Application2
step 4:Application1更新数据存储成功
step 5:Application2
结果:数据一致
先操作数据存储,再操作存储
 淘汰缓存时:
淘汰缓存时:step 1:Application1更新数据存储完成
step 2:Application2从缓存读取数据,查询到旧数据
step 3:Application1从缓存中删除数据
结果:缓存已淘汰,下次加载新数据
更新缓存时:
step 1:Application1更新数据存储完成
step 2:Application2从缓存读取数据,查询到旧数据
step 3:Application1从更新缓存数据
结果:数据一致
由此可见,不管我们如何组织,都可能完全杜绝不一致问题,而影响一致性的两个关键因素是——“操作失败”和“时序”。
对于“淘汰还是更新缓存”、“先缓存还是先数据存储”的选择,不应该脱离具体需求和业务场景而一概而论。我们把关注点重新回到“操作失败”和“时序”问题上来.
对于“操作失败”,首先要从程序层面提高稳定性,比如“弹性编程”,“防御式编程”等技巧,其次,要设计补偿机制,在操作失败后要做到保存足够的信息(包括补偿操作需要的数据,异常信息等),并进行补偿操作(清洗异常数据,回滚数据到操作前的状态),通过补偿操作,实现最终一致性。
对于“时序”问题,需要根据程序结构,梳理出潜在的时序问题。本文例子中,不设计补偿操作,如果引入的话,操作组合的时序图可能会更加复杂。解决的思路就是对于单个用户来说操作应该是“原子的”在分布式环境中,多个用户的操作应该是“串行”的。最简单的思路,就是使用分布式锁,来保证操作的串行化。当然,我们也可以通过队列来进行异步落库,实现最终一致性。
4 缓存穿透、缓存击穿、缓存雪崩
4.1 缓存穿透
缓存穿透是指用户频繁查询数据存储中不存在的数据,这类数据,查不到数据所以也不会写入缓存,所以每次都会查询数据存储,导致数据存储压力过大。
解决方案:
-
- 增加数据校验
- 查询不到时,缓存空对象
4.2 缓存击穿
高并发下,当某个缓存失效时,可能出现多个进程同时查询数据存储,导致数据存储压力过大。
解决方案:
-
-
- 使用二级缓存
- 通过加锁或者队列降低查询数据库存储的并发数量
- 考虑延长部分数据是过期时间,或者设置为永不过期
-
4.3 缓存雪崩
高并发下,大量缓存同时失效,导致大量请求同时查询数据存储,导致数据存储压力过大。
解决方案:
-
-
- 使用二级缓存
- 通过加锁或者队列降低查询数据库存储的并发数量
- 根据数据的变化频率,设置不同的过期时间,避免在同一时间大量失效
- 考虑延长部分数据是过期时间,或者设置为永不过期
-
总之,设计不能脱离具体需求和业务场景而存在,这里没有最优的组合方式,以上对该模式涉及问题的讨论,旨在发掘潜在的问题,以便合理应对。
以上是关于边缘缓存模式(Cache-Aside Pattern)的主要内容,如果未能解决你的问题,请参考以下文章
成为架构师课程系列使用 Cache-Aside 模式将数据存储在缓存中( Using the Cache-Aside pattern to store data in the cache)
缓存模式(Cache AsideRead ThroughWrite ThroughWrite Behind)
缓存模式:Caching Aside / Read Through / Write Through / Write Behind