java 容器
Posted angelica-duhurica
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java 容器相关的知识,希望对你有一定的参考价值。
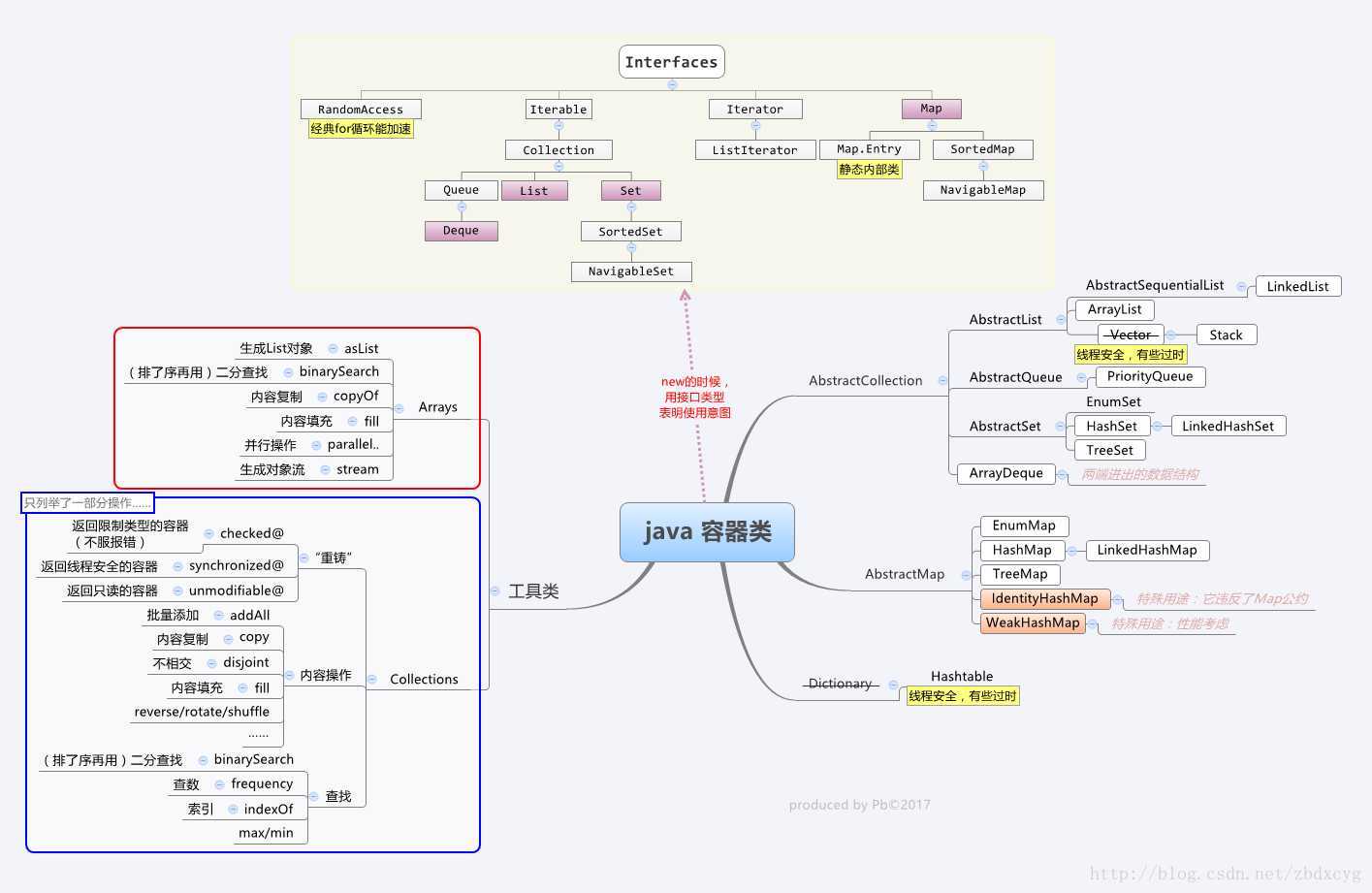
概述
List接口、Queue接口、Set接口均继承了Collection接口,而Collection接口又继承了Iterable接口。
public interface Iterable<T>
@NotNull
Iterator<T> iterator(); // 在子类中以内部类的方式实现
public interface Iterator<E>
@Contract(pure=true)
boolean hasNext();
E next();
// AbstractList实现了该接口,并实现了remove方法
default void remove()
throw new UnsupportedOperationException("remove");
default void forEachRemaining(Consumer<? super E> action)
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
List接口
有序、可重复 // ListIterator向前遍历
ArrayList:数组、线程不安全
LinkedList:链表、线程不安全
Vector:数组、线程安全
Set接口
不可重复
HashSet:哈希表(一个元素为链表的数组)
TreeSet:红黑树(一个自平衡的二叉树)保证元素排序方式
LinkedHashSet:哈希表+链表
Queue接口
两种实现方式:
- 循环数组(高效,但有界)
- 链表
List
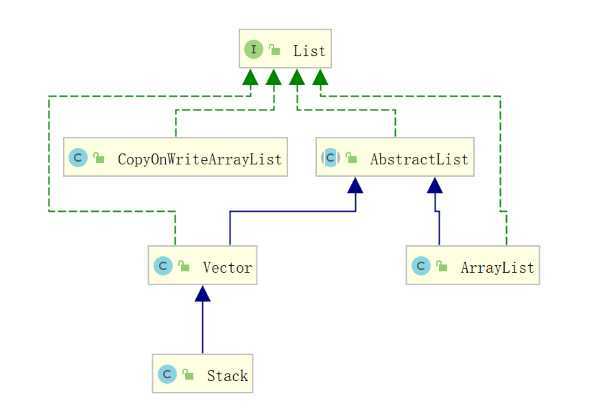
ArrayList
数组 ---扩容1.5倍---> “动态”增长 private static final int DEFAULT_CAPACITY = 10;
非线程安全 ------> 实现同步:List list = Collections.synchronizedList(arrayList);
add(E e)检查是否需要扩容(扩容,若仍不够,则扩为参数minCapacity)add(int index, E e)检查角标;检查是否需要扩容。可以添加null值get(int index)/set(int index, E e)检查角标remove(int index)检查角标;删除元素;计算个数并移动;设置null,让gc回收(删除元素时不会减少容量,可用trimToSize())注意:size和capacity不是一个概念!native void arraycopy();这是底层代码,由C/C++编写。所谓扩容就是新建一个新的数组,然后将老的数据里面的元素复制到新的数组里面,所以如1.2.4的实现都用这个。
public void trimToSize()
modCount++;
if (size < elementData.length)
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
Vector
数组 ---扩容2倍---> “动态”增长 public Vector() this(10);
如果初始化的时候没有设置capacityIncrement,那么默认是2倍的扩容,消耗内存多。
线程安全:基本所有方法用synchronized实现,有性能损失。
Stack
Stack<E> extends Vector<E>- `push(E item)``
- `
pop() - peek()`只是查看栈顶,并不移除
从Stack的源码中可以看到,它的入栈,出栈,查询操作均是利用Vector中的实现方法,并且都是同步的,因此是线程安全,但是性能是有所损耗。
LinkedList
非线程安全
class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>
// 双向链表
transient Node<E> first;
transient Node<E> last;利于插入删除,不利于查询。
CopyOnWriteArrayList
CopyOnWriteArrayList只是在增删改上加锁,但是读不加锁,在读方面的性能就好于Vector。
CopyOnWriteArrayList增删改都需要获得锁,并且锁只有一把,而读操作不需要获得锁,支持并发。支持读多写少的并发情况。
package java.util.concurrent;
final transient ReentrantLock lock = new ReentrantLock();
private transient volatile Object[] array;插入:
add(E e)add(int index, E element)addIfAbsent(E e, Object[] snapshot)addAllAbsent(Collection<? extends E> c)addAll(Collection<? extends E> c)addAll(int index, Collection<? extends E> c)newElements = Arrays.copyOf(elements, len + cs.length);set(int index, E element)删除:
remove(int index)remove(Object o, Object[] snapshot, int index)removeRange(int fromIndex, int toIndex)removeAll(Collection<?> c)removeIf(Predicate<? super E> filter)Object[] newElements = new Object[len - 1];retainAll(Collection<?> c)replaceAll(UnaryOperator<E> operator)sort(Comparator<? super E> c)subList(int fromIndex, int toIndex)clear()
final ReentrantLock lock = this.lock;
lock.lock();
try
// 读写分离,写时复制出一个新的数组,完成增、删、改操作后将新数组赋值给array
// 保证get的时候都能获取到元素,如果直接修改原来的数组,可能会造成执行读操作获取不到数据。
...
finally
lock.unlock();
Set
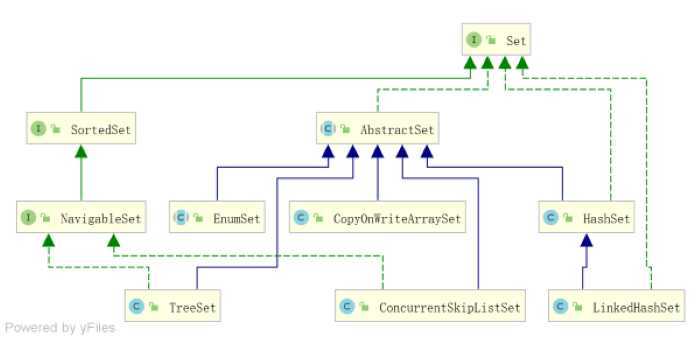
EnumSet
有序,不允许插入null
非线程安全 ------> 实现同步,Collections.synchronizedSet(set)
// 这个类及对应的子类是专门为枚举服务的,所以EnumSet中的数据也都是枚举类型。
abstract class EnumSet<E extends Enum<E>>
// 当EnumSet的容量大于64的时候,创建的是JumboEnumSet,否则创建的是RegularEnumSet。
if (universe.length <= 64)
return new RegularEnumSet<>(elementType, universe);
else
return new JumboEnumSet<>(elementType, universe);是一个抽象类,对这个数据结构不是很了解,看一下它的使用场景~
public class StatusWrapper
public enum Status IN_STORED, ON_THE_WAY
public void setStatus(Set<Status> status) ...
// of(E first, E... rest)可以设置多个状态~
wrapper.setStatus(EnumSet.of(Status.IN_STORED, Status.ON_THE_WAY));看实现类~
RegularEnumSet
其实RegularEnumSet中进行的操作就是围绕长整型elements的二进制位上的1和0进行的。添加元素,设置为1,删除元素,设置为0,清空,直接将该长整型置为0。
// 使用位向量保存,保存的时候保存的并不是实际的元素,而是保存的是bit,0和1;
private long elements = 0L;
public boolean add(E e)
typeCheck(e);
long oldElements = elements;
// add之后,elements二进制对应的ordinal位设置为了1
// 也就是每一个枚举元素在elements的二进制中占用一位
// 因为long是64位,所以RegularEnumSet的长度自然是不能大于64的
elements |= (1L << ((Enum<?>)e).ordinal());
// 直接通过判断添加前后elements的值有没有变化来判断
return elements != oldElements;
public int size()
// 统计long类型二进制中1的个数
return Long.bitCount(elements);
JumboEnumSet
private long elements[];
JumboEnumSet(Class<E>elementType, Enum<?>[] universe)
super(elementType, universe);
// 除以64
elements = new long[(universe.length + 63) >>> 6];
void addAll()
for (int i = 0; i < elements.length; i++)
elements[i] = -1; // -1的二进制是1111....1111
// 计算long数组中最后一个long元素二进制位上的1和0
elements[elements.length - 1] >>>= -universe.length;
size = universe.length;
因为基本上都是位运算,所以时间上可以认为是常数!
HashSet
底层是HashMap
允许有且仅有一个空值,不保证顺序
private transient HashMap<E,Object> map;
public HashSet()
map = new HashMap<>();
// 其他构造方法和基本方法几乎都使用map实现
public boolean add(E e)
// set中的element是map中的key,以此来保证不会重复
// 对于HashSet中保存的对象,注意正确重写其equals和hashCode方法,以保证放入的对象的唯一性。
return map.put(e, PRESENT)==null;
public boolean remove(Object o)
return map.remove(o)==PRESENT;
LinkedHashSet
底层是LinkedHashMap
class LinkedHashSet<E> extends HashSet<E> // 所有的构造方法都会调用父类HashSet的一个构造方法,使用底层的LinkedHashMap去实现功能。
HashSet(int initialCapacity, float loadFactor, boolean dummy)
map = new LinkedHashMap<>(initialCapacity, loadFactor);
TreeSet
底层是TreeMap
TreeSet<E> implements NavigableSet<E>
NavigableSet<E> extends SortedSet<E> // 可以排序 private transient NavigableMap<E,Object> m;
TreeSet(NavigableMap<E,Object> m)
this.m = m;
public TreeSet()
this(new TreeMap<E,Object>());
CopyOnWriteArraySet
底层是CopyOnWriteArrayList
package java.util.concurrent;
public CopyOnWriteArraySet()
al = new CopyOnWriteArrayList<E>();
ConcurrentSkipListSet
底层是ConcurrentSkipListMap
package java.util.concurrent;
class ConcurrentSkipListSet<E> implements NavigableSet<E>
NavigableSet<E> extends SortedSet<E> // 可以排序
private final ConcurrentNavigableMap<E,Object> m;
public ConcurrentSkipListSet()
m = new ConcurrentSkipListMap<E,Object>();
Queue
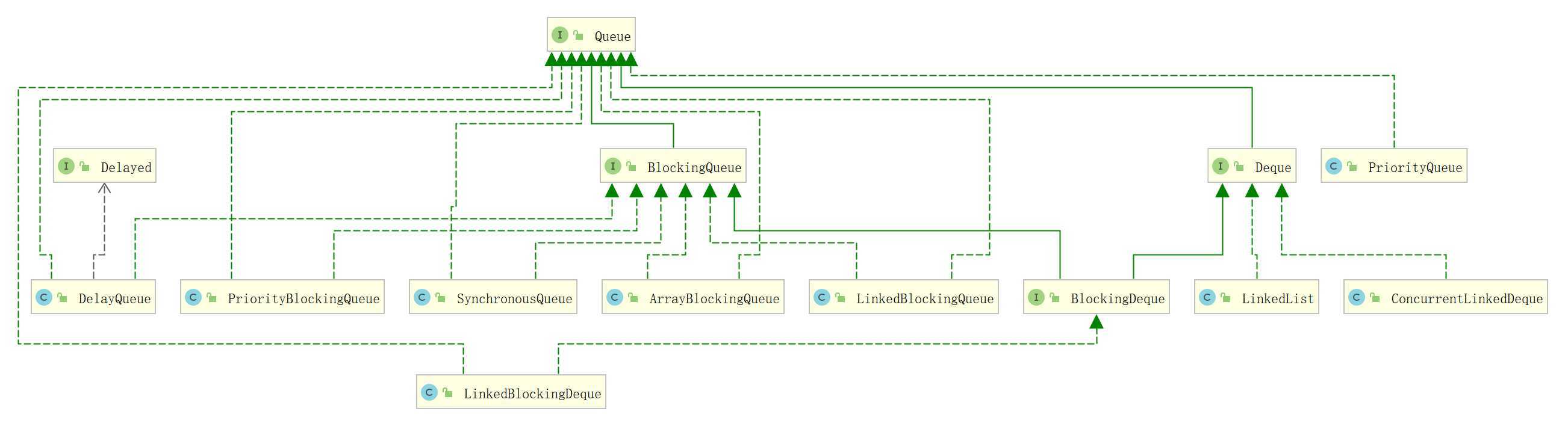
PriorityQueue
优先级队列:每次取出的元素都是队列中优先级最高的,默认是取出元素值最小的
不允许null
非线程安全 ------> PriorityBlockingQueue
// 基于优先级堆(最小堆),使用数组来构造堆
transient Object[] queue; // non-private to simplify nested class access
// 扩容的时候,先判断当前队列容量是否小于64,如果是扩容一倍容量,如果不是,扩容原容量的1/2。
// 上浮和下沉TaskQueue
private TimerTask[] queue = new TimerTask[128];下面是并发包里的~
ArrayBlockingQueue
底层用数组实现的阻塞队列。
// 数组
final Object[] items;
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull;
// 可以发现是通过lock和condition合作实现的,take方法同样~
public void put(E e) throws InterruptedException
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try
while (count == items.length)
notFull.await();
enqueue(e);
finally
lock.unlock();
ConcurrentLinkedQueue
不允许使用null
private transient volatile Node<E> head;
private transient volatile Node<E> tail;LinkedBlockingQueue
transient Node<E> head;
private transient Node<E> last;
// 取元素(出队列)和存元素(入队列)是采用不同的锁,进行了读写分离,有利于提高并发度。
private final ReentrantLock takeLock = new ReentrantLock();
private final Condition notEmpty = takeLock.newCondition();
private final ReentrantLock putLock = new ReentrantLock();
private final Condition notFull = putLock.newCondition();ConcurrentLinkedQueue和LinkedBlockingQueue的区别还是很明显的(前者在取元素时,若队列为空,则返回null;后者会进行等待)
DelayQueue
LinkedTransferQueue
PriorityBlockingQueue
SynchronousQueue
底层可能两种数据结构:队列(实现公平策略)和栈(实现非公平策略),队列与栈都是通过链表来实现的。
abstract static class Transferer<E>
abstract E transfer(E e, boolean timed, long nanos);
static final class TransferStack<E> extends Transferer<E>
/** Node represents an unfulfilled consumer */
static final int REQUEST = 0;
/** Node represents an unfulfilled producer */
static final int DATA = 1;
/** Node is fulfilling another unfulfilled DATA or REQUEST */
static final int FULFILLING = 2;
/** The head (top) of the stack */
volatile SNode head;
...
static final class TransferQueue<E> extends Transferer<E>
/** Head of queue */
transient volatile QNode head;
/** Tail of queue */
transient volatile QNode tail;
...
使用:
// true说明是公平策略
SynchronousQueue<Integer> queue = new SynchronousQueue<Integer>(true);Deque
双端队列(全名double-ended queue)是一种具有队列和栈的性质的数据结构。
双端队列中的元素可以从两端弹出,其限定插入和删除操作在表的两端进行。
interface Deque<E> extends Queue<E>ArrayDeque
不允许null
非线程安全
// 数组,循环数组,容量大小必须是2的幂
transient Object[] elements;
// 判断是否已满的条件是head == tail
transient int head;
transient int tail;
// 默认容量16
public ArrayDeque()
elements = new Object[16];
下面是并发包里的~
ConcurrentLinkedDeque
LinkedBlockingDeque
Map
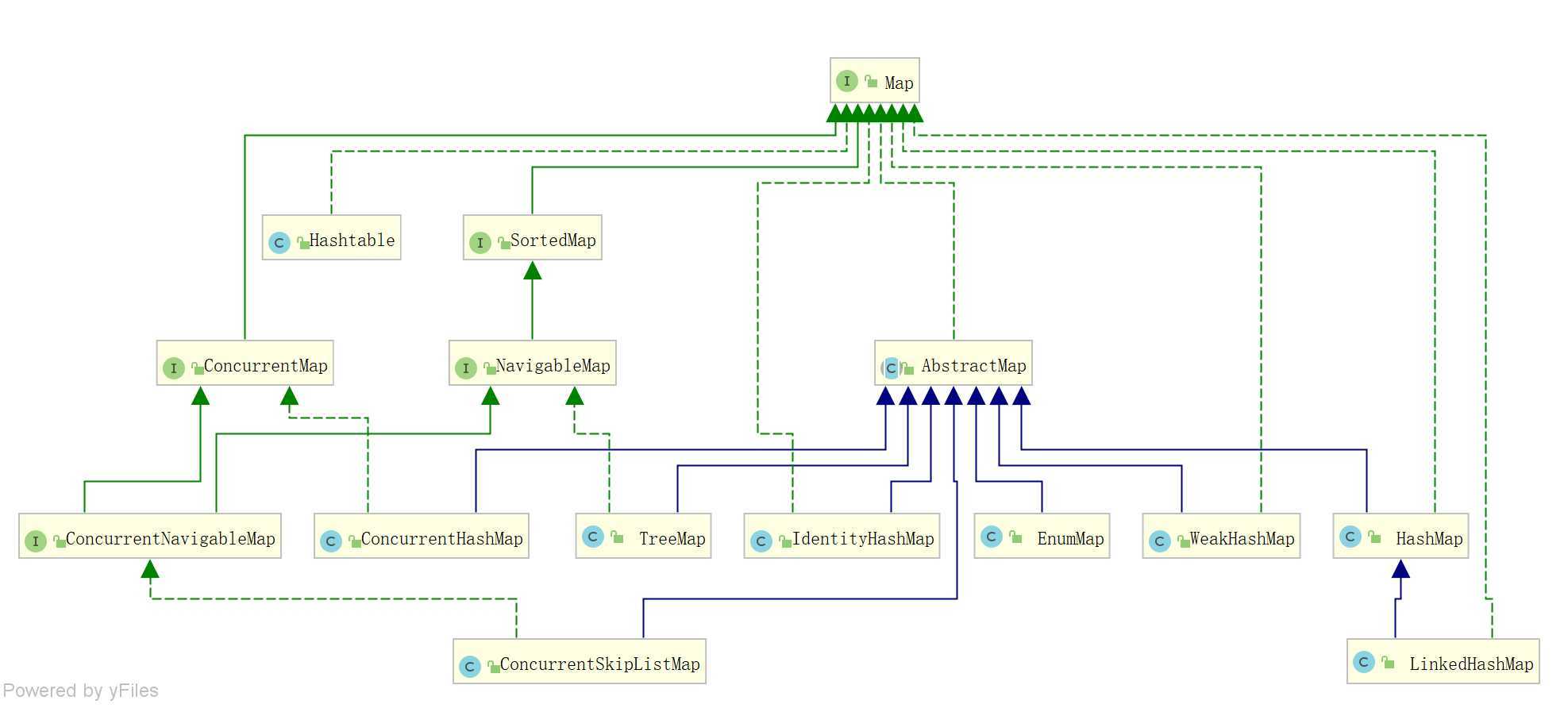
EnumMap
key不允许null,value允许null(NULL实例对象)
非线程安全 ------> 实现同步Collections.synchronizedMap
// 保存了所有值
private transient Object[] vals;
public V put(K key, V value)
typeCheck(key);
int index = key.ordinal();
Object oldValue = vals[index];
vals[index] = maskNull(value);
if (oldValue == null)
size++;
return unmaskNull(oldValue);
private static final Object NULL = new Object()
public int hashCode()
return 0;
public String toString()
return "java.util.EnumMap.NULL";
;Hashtable
线程安全
不允许key或者value为null
不建议使用
class Hashtable<K,V> extends Dictionary<K,V>
// 链表+数组,每个链表被称为bucket
private transient Entry<?,?>[] table;
public Hashtable()
this(initialCapacity: 11, loadFactor: 0.75f);
// 为每个对象计算一个散列码,根据散列码保存对象
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
// 若散列码相同,则冲突
// 如果数组容量超过阈值,则rehash:int newCapacity = (oldCapacity << 1) + 1;
tab[index] = new Entry<>(hash, key, value, e); // e是原表头,添加是在表头添加的解决hash冲突的方法:
- 开放地址法(线性探测、二次探测、伪随机探测):即发生冲突时,去寻找下一个空的哈希地址。只要哈希表足够大,总能找到空的哈希地址。
- 再散列:即发生冲突时,由其他的函数再计算一次哈希值。
- 链地址法(HashMap采用这种方法):将哈希表的每个单元作为链表的头结点,所有哈希地址为 i 的元素构成一个同义词链表。即发生冲突时就把该关键字链在以该单元为头结点的链表的尾部。
- 建立一个公共溢出区:将哈希表分为基本表和溢出表,发生冲突时,将冲突的元素放入溢出表。
HashMap
数组+链表+红黑树 // 红黑树是1.8引入
允许null
非线程安全 ------> 实现同步Collections.synchronizedMap
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 数组+链表
transient Node<K,V>[] table;
// 内部类
static class Node<K,V> implements Map.Entry<K,V> ...
static final int hash(Object key)
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
// 阈值是2的幂 > 容量为什么是2的幂次?无论如何,我们希望元素存放的更均匀。tab[i=(n-1)&hash]中n-1的二进制是全1的,这样做与运算就避免了因为该值产生的多余的碰撞。所以相比别的值而言,采用2的幂次能有效提高插入查询等的效率。
threshold = tableSizeFor(t);
// 如果容量大于阈值,就扩容;随着容量增大,负载因子减小,对遍历更加不友好,扩容次数增多。
resize(); final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict)
Node<K,V>[] tab; Node<K,V> p; int n, i;
...
if ((p = tab[i = (n - 1) & hash]) == null) // 不存在hash碰撞
tab[i] = newNode(hash, key, value, null);
else // 存在hash碰撞,这里是采用链地址法
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) // hash和key都相同,就是更新,不管它是啥类型的节点,反正它是第一个节点
e = p;
else if (p instanceof TreeNode) // 是红黑树节点,调用putTreeVal()
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else // 是普通节点,遍历就行
for (int binCount = 0; ; ++binCount)
if ((e = p.next) == null)
p.next = newNode(hash, key, value, null);
// 链表长度大于某个值时,调用treeifyBin()将链表转红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
// hash和key都相同,就是更新
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
...
...
上面这段代码还是很值得一看的~流程图如下
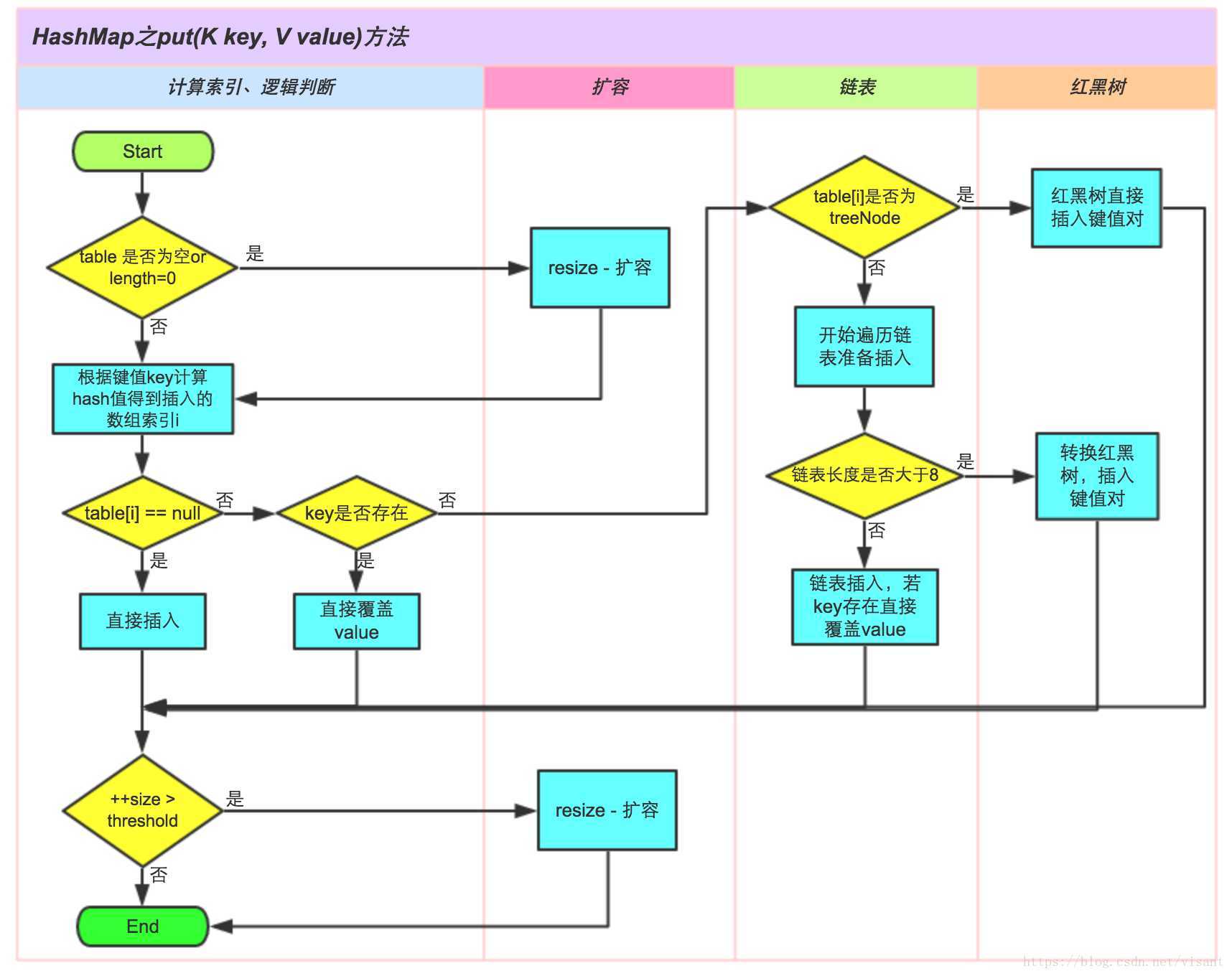
- 计算hash值
- 通过tab[i = (n - 1) & hash]找到bucket位置,存储Map.Entry对象(包含键和值)。其实就是取hash的后\\(log_2n\\)位。也就是取低位哦!
为什么不直接用hash值,而是采用与运算/取低位?
hash值可是32位呢,这么大,tab内存不够的呀~
那为何是按位与而不是取模?取模也可以很好地分散啊~int index =hash%Entry[].length;
按位与比取模效率更高。位运算直接对内存数据进行操作,不需要转成十进制。
插入null如何处理?
hash()会为0,所以值会存在tab[0]的位置上。
static final int hash(Object key)
int h; // 是一个32位的int值
// 如果key的高位变化大,低位变化小,直接&容易碰撞
// 将高位与地位异或,增加随机性
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
将哈希值h无符号右移16位,再与原来的哈希值h做异或^运算。也就是说,现在的低位16是原来的高位16与低位16的异或结果!结合我们找bucket位置的时候是取低位,这样就保证了取的低位里面有更多hash的信息!也就保证了冲突变少。
红黑树的部分还是不想看...
LinkedHashMap
在原先HashMap的基础上再加一个双向链表,维护数据的顺序而已。
LinkedHashMap中的大部分方法就是为了维护这个顺序。
默认是插入顺序,若为访问顺序,会产生结构性修改(afterNodeAccess)
最常用的将其放在链表的最后。
遍历的是内部维护的双向链表,初始容量对遍历影响不大。
允许null(同HashMap)
非线程安全 ------> 实现同步Collections.synchronizedMap(同HashMap)
class LinkedHashMap<K,V> extends HashMap<K,V>
// 双向链表(有序)
transient LinkedHashMap.Entry<K,V> head;
transient LinkedHashMap.Entry<K,V> tail;
final boolean accessOrder;IdentityHashMap
比较键(和值)时使用引用相等性代替对象相等性,也就是说使用 == 而不是使用 equals。比较的是内存地址。
允许key和value都为null
非线程安全 ------> 实现同步Collections.synchronizedMap
// 实现不同于HashMap,是数组
transient Object[] table;
// key所对应的index全是偶数
tab[i] = k;
tab[i + 1] = value;
// 数组初始化的时候,数组的长度被定义为默认容量的2倍
int newLength = newCapacity * 2;
Object[] newTable = new Object[newLength];
table = newTable;
// 扩容条件:存放的数组达到数组长度的1/3的时候
if (s + (s << 1) > len && resize(len))
// 解决冲突的方式是计算下一个有效索引
for (Object item; (item = tab[i]) != null; i = nextKeyIndex(i, len))
...
private static int nextKeyIndex(int i, int len)
return (i + 2 < len ? i + 2 : 0);
private static int hash(Object x, int length)
// 没有使用Object的hashCode方法
// 此处是根据对象在内存中的地址算出来的一个数值,不同的地址算出来的结果是不一样的。
int h = System.identityHashCode(x);
// Multiply by -127, and left-shift to use least bit as part of hash
return ((h << 1) - (h << 8)) & (length - 1);
WeakHashMap
基于Java的弱引用的哈希表实现。
主要是用于优化JVM,使JVM在进行垃圾回收的时候能智能的回收那些无用的对象。在垃圾回收的时候,不管内存是否充足,如果一个对象的所有引用都是弱引用,那么该对象就会被回收。
private static class Entry<K,V> extends WeakReference<Object>
// 键为弱键,当Map中的键不再使用,键对应的键值也将自动在WeakHashMap中删除。
Entry<K,V>[] table;
// 弱键的引用队列,用于存放虚拟机回收的Entry的引用
// 一旦GC之后有key被清除,那key对应的引用就会被放入引用队列中。
private final ReferenceQueue<Object> queue = new ReferenceQueue<>();
private void expungeStaleEntries()
// 遍历队列,通过队列的poll方法从队头获取数据,如果存在被GC的对象,就需要移除map中对应的数据
for (Object x; (x = queue.poll()) != null; )
synchronized (queue)
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) x;
// 获取当前节点的索引位置
int i = indexFor(e.hash, table.length);
// 获取索引位置的节点
Entry<K,V> prev = table[i];
Entry<K,V> p = prev;
// 遍历链表
while (p != null)
Entry<K,V> next = p.next;
if (p == e)
if (prev == e)
table[i] = next;
else
prev.next = next;
// Must not null out e.next;
// stale entries may be in use by a HashIterator
e.value = null; // Help GC
size--;
break;
prev = p;
p = next;
- 创建WeakHashMap,添加对应的键值对信息,而底层是使用一个数组来保存对应的键值对信息Entry,而Entry生成的时候就与引用队列ReferenceQueue进行了关联;
- 当某弱键key不再被其他对象使用,并被JVM回收时,这个弱键对应的Entry会被同时添加到引用队列中去。
- 当下一次我们操作WeakHashMap时(比如调用get方法),会先处理引用队列中的这部分数据,这样这些弱键值对就自动在WeakHashMap中被自动删除了。
被GC清除后的引用是什么时候进入引用队列的呢?
Reference对象是与垃圾回收器有直接的关联的。而这种直接的关联是通过ReferenceHandler 这个线程来实现的。ReferenceHandler线程是JVM创建main线程后创建的线程,其优先级最高,是10,它就是用来处理引用对象的垃圾回收问题的。
使用场景:tomcat的ConcurrentCache
TreeMap
不允许null
非线程安全
class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>
interface NavigableMap<K,V> extends SortedMap<K,V>
// 默认情况下根据key的自然顺序进行排序
private final Comparator<? super K> comparator;
// 红黑树(有序)
private transient Entry<K,V> root;比较~
put(K key, V value):
- comparator != null
- comparator == null,使用key作为比较器,key须实现Comparable
get(Object key):------> getEntry(key)
- comparator != null,------> getEntryUsingComparator(key)
- comparator == null,------> compareTo()
遍历:EntryIterator
ConcurrentHashMap
数组+链表+红黑树 1.8
segments+HashEntry<K, V> 1.7 (segments extends ReentrantLock 每个片段有一个锁,锁分段)
不允许null
线程安全:对每一个桶单独进行锁操作,不同的桶之间的操作不会相互影响,可以并发执行。部分加锁,利用CAS算法实现同步
CAS:Compare And Swap 比较与交换,无锁算法;基于CPU原语CAS指令实现
JNI:Java Native Interface,比如public final native boolean compareAndSwapInt(...);
putVal():只让一个线程对表进行初始化;如果可以直接存,则直接插入,不用加锁(cas),否则加锁(synchronized)
get():非阻塞;不加锁
Node<K, V> implements Map.Entry<K, V> 内部类重写:通过volatile修饰next来实现每次获取都是最新设置的值,保证线程间的数据共享
很多内部类...
- Node类:用于存储具体键值对,其子类有ForwardingNode、ReservationNode、TreeNode和TreeBin。
2. Traverser类:用于遍历操作,其子类有BaseIterator、KeySpliterator、ValueSpliterator、EntrySpliterator,BaseIterator用于遍历操作。KeySplitertor、ValueSpliterator、EntrySpliterator则用于键、值、键值对的划分。
3. CollectionView类:定义了视图操作,其子类KeySetView、ValueSetView、EntrySetView分别表示键视图、值视图、键值对视图。
4. Segment类:在JDK1.8下,其在普通的ConcurrentHashMap操作中已经没有失效,其在序列化与反序列化的时候会发挥作用。
Segment类在JDK1.8中与之前的版本的JDK作用存在很大的差别,JDK1.8下,其在普通的ConcurrentHashMap操作中已经没有失效,其在序列化与反序列化的时候会发挥作用。
5. CounterCell:主要用于对baseCount的计数。
太困难了,6k+行代码,我选择以后再看...
CounterCell类主要用于对baseCount的计数。
ConcurrentSkipListMap
跳表
实现有序链表的二分查找。
跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。每个索引节点包含两个指针,一个向下,一个向右。(空间换时间)
跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
使用场景:Redis选择使用跳表来实现有序集合。
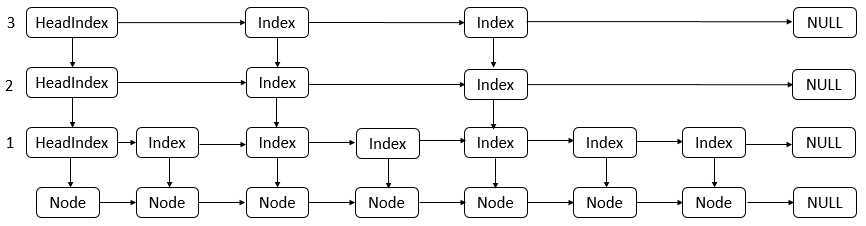
private transient volatile HeadIndex<K,V> head;
final Comparator<? super K> comparator;
static class Index<K,V>
final Node<K,V> node;
final Index<K,V> down;
volatile Index<K,V> right;
...
// 插入一个Index结点
final boolean link(Index<K,V> succ, Index<K,V> newSucc)
Node<K,V> n = node;
newSucc.right = succ;
return n.value != null && casRight(succ, newSucc);
// 删除当前Index结点的right结点
final boolean unlink(Index<K,V> succ)
return node.value != null && casRight(succ, succ.right);
static final class HeadIndex<K,V> extends Index<K,V>
final int level;
...
doPut的大体流程如下:
- 根据给定的key从跳表的左上方往右或者往下查找到Node链表的前驱Node结点,这个查找过程会删除一些已经标记为删除的结点。
- 找到前驱结点后,开始往后插入查找插入的位置(因为找到前驱结点后,可能有另外一个线程在此前驱结点后插入了一个结点,所以步骤①得到的前驱现在可能不是要插入的结点的前驱,所以需要往后查找)。
- 随机生成一个种子,判断是否需要增加层级,并且在各层级中插入对应的Index结点。
doRemove函数的处理流程如下。
根据key值找到前驱结点,查找的过程会删除一个标记为删除的结点。
从前驱结点往后查找该结点。
在该结点后面添加一个marker结点,若添加成功,则将该结点的前驱的后继设置为该结点之前的后继。
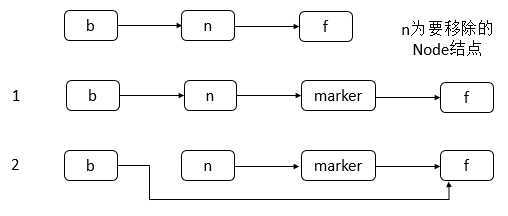
- 头结点的next域是否为空,若为空,则减少层级tryReduceLevel。
参考:
https://blog.csdn.net/visant/article/details/80045154
https://www.jianshu.com/p/bfdb5ffa0ae2
https://www.cnblogs.com/leesf456/p/5550043.html
以上是关于java 容器的主要内容,如果未能解决你的问题,请参考以下文章