基于Hadoop生态圈的数据仓库实践 —— 概述
Posted wzy0623
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Hadoop生态圈的数据仓库实践 —— 概述相关的知识,希望对你有一定的参考价值。
二、在Hadoop上实现数据仓库(大部分翻译自《Big Data Warehousing》)
数据仓库技术出现很长时间了,现在为什么要从传统数据库工具转为使用Hadoop呢?答案就是最引人关注的流行词汇 —— 大数据。对许多组织来说,传统关系数据库已经不能够经济地处理他们所面临的数据量。而Hadoop生态圈就是为了能够廉价处理大量数据的目的应运而生的。下面看看大数据是怎么定义的。
1. 大数据的定义
虽然数据仓库技术自诞生之日起的二十多年里一直被用来处理大数据,但“大数据”这个词却是近年来随着以Hadoop为代表的一系列分布式计算框架的产生发展才流行起来。现在一个较为通用的大数据定义是4Vs:Volume、Velocity、Variety、Veracity,用中文简单描述就是大、快、多、真。
Volume —— 数据量大
随着技术的发展,人们收集信息的能力越来越强,随之获取的数据量也呈爆炸式增长。例如百度每日处理的数据量达上百PB,总的数据量规模已经到达EP级。
Velocity —— 处理速度快
指的是销售、交易、计量等等人们关心的事件发生的频率。2015年双11,支付宝的峰值交易数为每秒8.59万笔。
Variety —— 数据源多样
现在要处理的数据源包括各种各样的关系数据库、NoSQL、平面文件、XML文件、机器日志、图片、音视频等等,而且每天都会产生新的数据格式和数据源。
Veracity —— 真实性
诸如软硬件异常、应用系统bug、人为错误等都会使数据不正确。大数据处理中应该分析并过滤掉这些有偏差的、伪造的、异常的部分,防止脏数据损害到数据准确性。
2. 为什么需要分布式计算
传统数据仓库一般建立在Oracle、mysql这样的关系数据库之上。关系数据库主要的问题是不好扩展,或者说扩展的成本非常高,因此面对当前4Vs的数据问题时显得能力不足,而这正是Hadoop的用武之地。Hadoop生态圈最大的吸引力是它有能力处理非常大的数据量。在大多数情况下,Hadoop生态圈的工具能够比关系数据库处理更多的数据,因为数据和计算都是分布式的。那么为什么分布式计算是处理大数据的关键所在呢?
想象这样一个问题,在一个10TB大小的web日志文件中,找出单词‘ERROR’的个数。解决这个问题最直接的方法就是查找日志文件中的每个单词,并对单词‘ERROR’的出现进行计数。做这样的计算会将整个数据集读入内存。作为讨论的基础,我们假设现代系统从磁盘到内存的数据传输速率为每秒100MB,这意味着在单一计算机上要将10TB数据读入内存需要27.7个小时。如果我们把数据分到10台计算机上,每台计算机只需要处理1TB的数据。它们彼此独立,可以对自己的数据分片中出现的‘ERROR’计数,最后再将每台计算机的计数相加。在此场景下,每台计算机需要2.7个小时读取1TB数据。因为所有计算机并行工作,所以总的时间也近似是2.7个小时。这种方式即为线性扩展 —— 可以通过简单地增加所使用的计算机数量来减少处理数据花费的时间:以此类推,如果我们使用100台计算机,做这个任务只需0.27个小时。Hadoop背后的核心观点是:如果一个计算可以被分成小的部分,每一部分工作在独立的数据子集上,并且计算的全局结果是独立部分结果的联合,那么此计算就可以分布在多台计算机中并行执行。
3. Hadoop基本组件
如下图所示,Hadoop实际是由三个不同的组件构成:HDFS —— Hadoop分布式文件系统;YARN —— 一个资源调度框架;MapReduce —— 一个分布式处理框架。程序员可以联合使用这三个组件构建分布式系统。
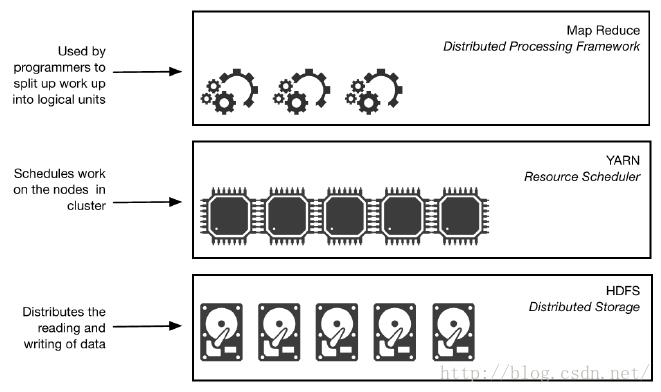
Hadoop分布式文件系统负责在集群中的节点或计算机中分散存放数据。如下图所示,把数据上传到HDFS上时,系统会自动做三件事情:
- 把文件分成数据块。
- 把数据块分散到HDFS集群中的多台计算机中。
- 每个数据块被复制成多个块拷贝,块拷贝存在于不同的机器上。

如上图所示,如果有一个256MB的文件,集群中有4个节点,那么缺省情况下,当把文件上传到集群时:
- HDFS会将此文件分成64MB的数据块。
- 每个块有三个拷贝。
- 数据块被分散到集群节点中,确保对于任意数据块,没有两个块拷贝在相同的节点上。
(2)MapReduce
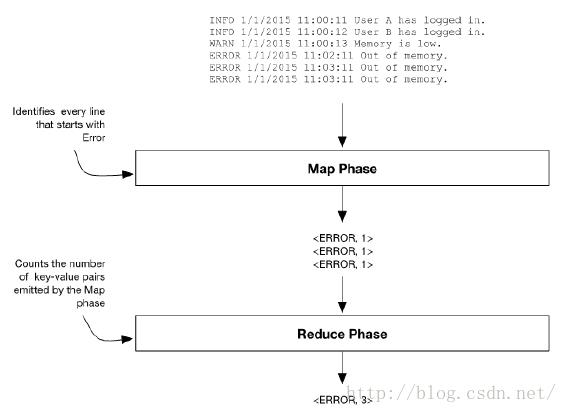
MapReduce是一个分布式编程模式。它的主要思想是,将数据Map为一个键值对的集合,然后对所有键值对按照相同键值进行Reduce。为了直观地理解这种编程模式,再次考虑在10TB的web日志中计算‘ERROR’的个数。假设web日志输出到一系列文本文件中。文件中的每一行代表一个事件,以ERROR、WARN或INFO之一开头。一行的其它部分由事件的时间戳及其描述组成,如下图所示:

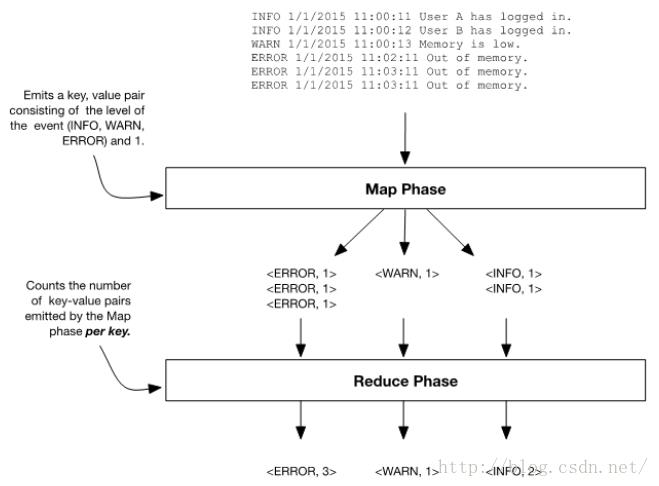
对这个例子稍微做一点扩展,现在想知道日志中ERROR、WARN、INFO分别的个数。如下图所示,在map阶段检查每一行并标识键值对,如果行以‘INFO’开头,键值对为<INFO, 1>,如果以‘WARN’开头,键值对为<WARN, 1>,如果以‘ERROR’开头,键值对为<ERROR, 1>。在reduce阶段,对每个map阶段生成的唯一键值‘INFO’、‘WARN’和‘ERROR’进行计数。
通过上面简单的示例我们已经初步理解了MapReduce编程模式是如何工作的,现在看一下Hadoop MapReduce是怎么实现的。如下图所示,Hadoop MapReduce的实现分为split、map、shuffle和reduce四步。开发者只需要在Mappers和Reducers的Java类中编码map和reduce阶段的逻辑,框架完成其余的工作:
- HDFS分布数据。
- 向YARN请求资源以建立mapper实例。
- 在可用的节点上建立mapper实例。
- 对mappers的输出进行混洗,确保一个键对应的所有值都分配给相同的reducer。
- 向YARN请求资源以建立reducer实例。
- 在可用的节点上建立reducer实例。

乍一看,似乎MapReduce能处理的情况真的很有限,但实际结果却是,大多数SQL操作都可以被表达成一连串的MapReduce操作,并且Hadoop生态圈的工具可以自动把SQL转化成MapReduce程序处理,所以对于熟悉SQL的人来说,不必自己实现Mapper或者Reducer。
(3)YARNYARN是Hadoop最新的资源管理系统。除了Hadoop MapReduce外,Hadoop生态圈现在有很多应用操作HDFS中存储的数据。资源管理系统负责多个应用程序的多个作业可以同时运行。例如,在一个集群中一些用户可能提交MapReduce作业查询,另一些用户可能提交Spark 作业查询。资源管理的角色就是要保证两种计算框架都能获得所需的资源,并且如果多人同时提交查询,保证这些查询以合理的方式获得服务。
4. Hadoop生态圈的其它组件
Hadoop生态圈最初只有HDFS和MapReduce,以后有了非常快速的发展。如下图所示,除MapReduce外,目前已经存在大量的分布式处理引擎。生态圈中还有一系列迁移数据、管理集群的辅助工具。

这些产品貌似各不相同,但是三种共同的特征把它们紧密联系起来。首先,它们都依赖于Hadoop的某些组件 —— YARN、HDFS或MapReduce。其次,它们都把处理大量的数据作为关注点,并提供建立端到端数据流水线所需的各种功能。最后,它们对于应该如何建立分布式系统的理念是共通的。
5. Hadoop生态圈的分布式计算思想
Hadoop生态圈在设计分布式系统时是固执己见的。它认为一个分布式系统应该是这样的:
(1)使用通用硬件。整个Hadoop生态圈都能运行在一个相对廉价的通用硬件上。通用硬件指的是可以从多个厂商购买的标准服务器。这与那些需要运行在单一厂商提供的特殊硬件上的分布式系统不同。
(2)向外扩展而不是向上扩展。基于这个观点,Hadoop生态圈通过增加机器数量进行扩展,而不是增进一台机器的性能。大量关系数据库系统使用相反的方法,当数据量或用户量增加时,它们推荐增加单一机器的内存、CPU核心或者存储。
(3)容错。Hadoop生态圈中的任一组件都假设硬件故障是一个常态,并在硬件失败时提供保护措施,避免丢失数据,并尽可能完成已经激活的查询或任务。
(4)将代码向数据移动。在Hadoop生态圈中,假定每个节点优先使用该节点上的数据进行一部分全局计算。这样做的理论依据是,在节点间移动数据非常慢,因此尽可能将每一部分计算向计算需要的数据移动。
这些理论在Hadoop生态圈中是通用的,可以将其应用到Hadoop的各种组件。
6. 与传统数据仓库架构对应的Hadoop生态圈工具
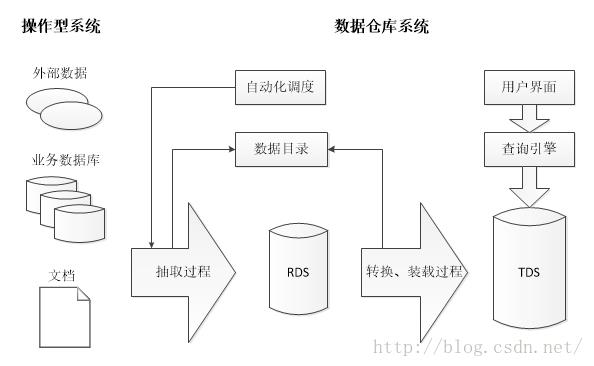
传统的数据仓库并不是一个单一系统,而是由一系列协同工作的组件联合构成,包括ETL过程,RDS,TDS,数据目录,查询引擎,用户界面,自动化调度,如下图所示。
以上是关于基于Hadoop生态圈的数据仓库实践 —— 概述的主要内容,如果未能解决你的问题,请参考以下文章
基于hadoop生态圈的数据仓库实践 —— OLAP与数据可视化