hive
Posted starstarstar
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive相关的知识,希望对你有一定的参考价值。
什么是Hive ?
Hive是构建在hadoop HDFS上的一个数据仓库;
Hive的表/数据 就是HDFS中目录/文件
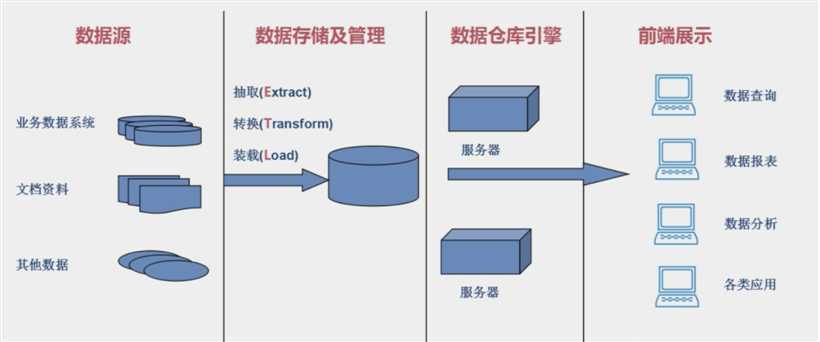
数据仓库:
- 是一个面向主题的、集合的、不可更新的、随时间不变化的数据集合;
- 主要是用于支持企业或组织的决策分析处理
数据仓库的结构和建立过程
抽取E:把数据源的数据按照一定的方式进行读取
转换T:将不同格式的数据按照一定的规则进行转化
装载L:将满足格式的数据存在数据仓库中
OLTP应用和OLAP应用:
- OLTP连接事务处理:(比如银行转账),操作频率高,事务的处理
- OLAP连接分析处理:(比如商品推荐系统) 基于原来的历史数据,提供给别的系统使用,一般不会更新插入数据
数据仓库中的数据模型:
- 星型模型:以主题为核心,进行关联
- 雪花模型: 基于星型模型上发展
什么是Hadoop ?
-
什么是HDFS
-
什么是mapreduce
-
Hadoop中的一些基本操作
Hive的体系结构
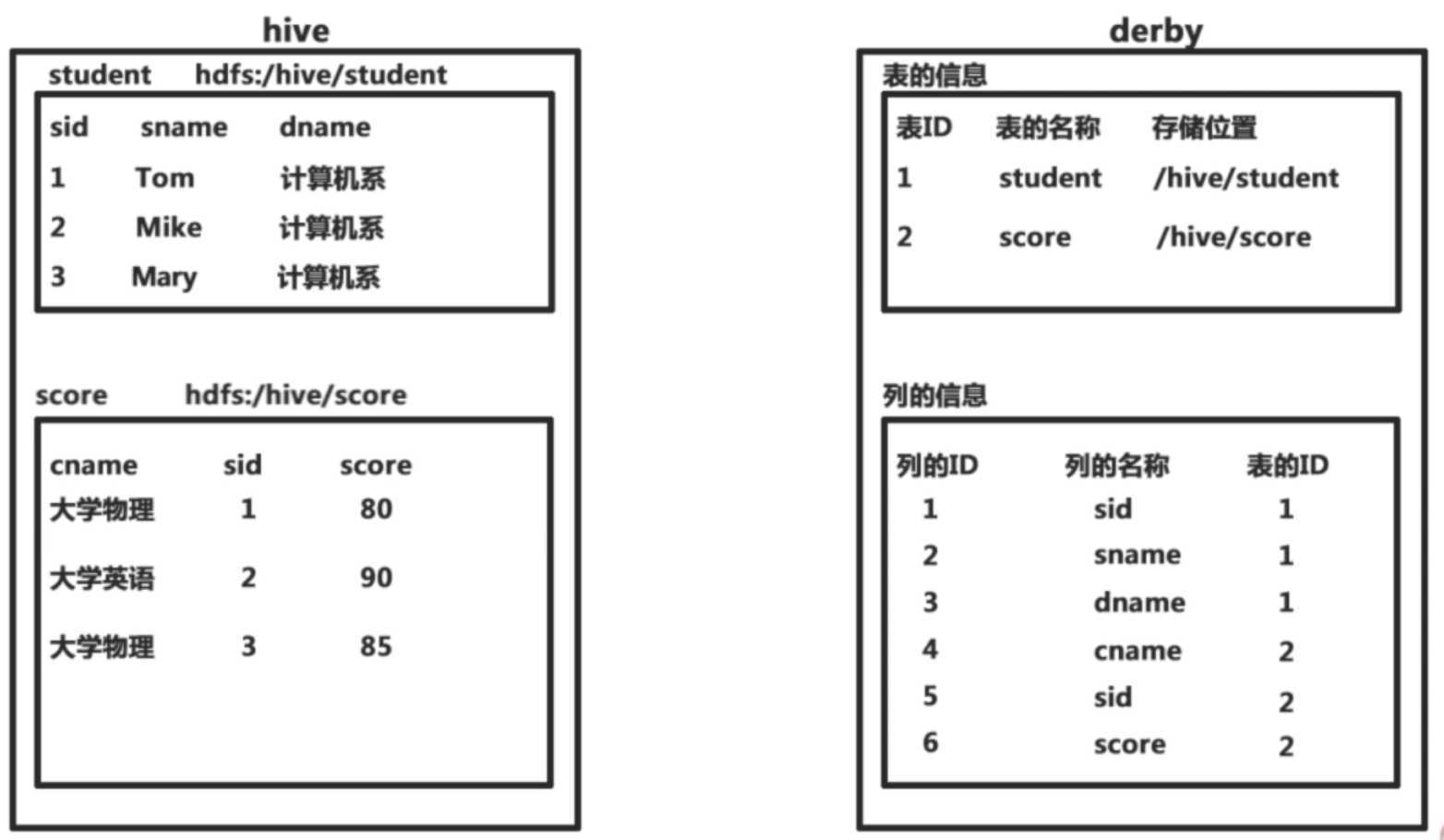
Hive的元数据:
- Hive将元数据存储在数据库中(metastore),支持mysql,Derby等数据库
- Hive中元数据 包括 表的名字,表的列,和 分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
HQL语句的执行过程

Hive的安装
下载地址:http://archive.apache.org/dist/hive/
先安装Hadoop的环境,才能再安装Hive的安装
嵌入模式的安装
- 元数据信息被存储在Hive自带的Derby数据库
- 只允许创建一个连接
- 多用于Demo
本地模式的安装
- 元数据信息被存储在Mysql数据库
- MySQL数据和Hive运行在同一台物理机上
- 可以用于开发和测试
远程模式的安装
- 常用于生成环境
- MySQL和Hive运行在不同的操作系统上
Hive的管理方式
- 命令行CLI方式: 可以进入命令行,然后执行一些命令即可
- 远程服务启动
- web界面方式
常用的HQL语句
查询语句:https://docs.jboss.org/hibernate/orm/3.5/reference/zh-CN/html/queryhql.html
Hive的数据类型
- 基本数据类型:
- 整数类型:tinyint/smallint/int/bigint
- 浮点数类型:float/double
- 布尔类型:boolean
- 字符串类型:string
- 复杂数据类型
- Array
- map:格式是key-value格式,key相同时,value被覆盖
- struct:结构类型,包含不同数据类型的元素,可以通过”点语法“的方式来获取到所需要的元素
- 时间数据类型
- date:日期
- timestamp:偏移量,跟时区无关
示例:
创建表,
create table student (sid int, sname string, grade array<float>, id map<string,int>, info struct<name:string,age:int,sex:string>);
sid和sname是基本数据类型,grade是复杂数据类型Array,info是结构数据,id是map,grade是数组array
查看表结构,
desc student;
Hive数据模型
内部表
- 与数据库中的table在概念上是类似的
- 每一个table在hive中都有一个相对应的目录存储数据
- 所有的table数据(不包括外部表)都保存在这个目录中
- 删除表时,元数据和数据都会被删除
分区表
- partition对应于数据库的partition列的密集索引
- 在hive中,表中的一个partition对应于表下的一个目录,所有的partition的数据都存储在对应的目录中
外部表
- 外部表 是一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个连接。当删除一个外部表,就是删除该连接
桶表
- 桶表是对数据进行哈希取值,然后放在不同文件中进行存储
视图
- 视图是一种虚表,是一个逻辑概念;可以跨越多个表
- 视图简历在已有表的基础上,视图赖以建立的这些表,成为基表
- 视图可以简化复杂的查询
以上是关于hive的主要内容,如果未能解决你的问题,请参考以下文章