Hbase基本原理
Posted jalja
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase基本原理相关的知识,希望对你有一定的参考价值。
一、hbase是什么
HBase 是一种类似于数据库的存储层,也就是说 HBase 适用于结构化的存储。并且 HBase 是一种列式的分布式数据库,是由当年的 Google 公布的 BigTable 的论文而生。HBase 底层依旧依赖 HDFS 来作为其物理存储。
二、hbase的列式存储结构
行式存储:传统的数据库是关系型的,且是按行来存储的
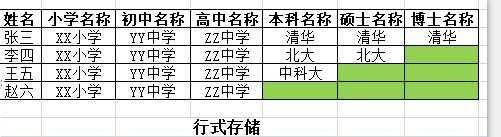
其中只有张三把一行数据填满了,李四王五赵六的行都没有填满。因为这里的行结构是固定的,每一行都一样,即使你不用,也必须空到那里,而不能没有。
列式存储:
HBase是一个面向列的数据库,在表中它由行排序。表模式定义只能列族,也就是键值对。一个表有多个列族以及每一个列族可以有任意数量的列。后续列的值连续地存储在磁盘上。表中的每个单元格值都具有时间戳。总之,在一个HBase:
- 表是行的集合。
- 行是列族的集合。
- 列族是列的集合。
- 列是键值对的集合。

Row key行键 (Row key): 可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes),在Hbase内部,row key保存为字节数组。存储时,数据按照Row key的字典序(byte order)排序存储。设计key时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)。
列族: Hbase表中的每个列,都归属与某个列族。列族是表的chema的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如courses:history,courses:math 都属于courses 这个列族。访问控制、磁盘和内存的使用统计都是在列族层面进行的。实际应用中,列族上的控制权限能帮助我们管理不同类型的应用:我们允许一些应用可以添加新的基本数据、一些应用可以读取基本数据并创建继承的列族、一些应用则只允许浏览数据(甚至可能因为隐私的原因不能浏览所有数据)。
时间戳: Hbase中通过row和columns确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由Hbase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。 为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,Hbase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
Cell: 由row key, column(= + ), version 唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存贮。
三、hbase架构

Zookeeper
Zookeeper 是作为 HBase Master 的 HA 解决方案。也就是说,是 Zookeeper 保证了至少有一个 HBase Master 处于运行状态。并且 Zookeeper 负责 Region 和 Region Server 的注册。
HMaster:
HBase Master 用于协调多个 HRegion Server,侦测各个 HRegion Server 之间的状态,并平衡 HRegion Server 之间的负载。HBase Master 还有一个职责就是负责分配 Region 给 HRegion Server。HBase 允许多个 Master 节点共存,但是这需要 Zookeeper 的帮助。不过当多个 Master 节点共存时,只有一个 Master 是提供服务的,其他的 Master 节点处于待命的状态。当正在工作的 Master 节点宕机时,其他的 Master 则会接管 HBase 的集群。
- 为Region server分配region,负责region server的负载均衡
- 管理用户对Table的增、删、改、查操作
- 发现失效的region server并重新分配其上的region
- GFS上的垃圾文件回收
- 在HRegionServer停机后,负责失效HRegionServer 上的Regions迁移
HDFS:
HDFS是Hbase运行的底层文件系统
HRegionServer
HRegionServer是RegionServer的实现,服务和管理Regions,集群中HRegionServer运行在DataNode上。
对于一个 HRegion Server 而言,其包括了多个 HRegion。HRegion Server 的作用只是管理表格,以及实现读写操作。Client 直接连接 HRegion Server,并通信获取 HBase 中的数据。对于 Region 而言,则是真实存放 HBase 数据的地方,也就说 Region 是 HBase 可用性和分布式的基本单位。如果当一个表格很大,并由多个 CF 组成时,那么表的数据将存放在多个 Region 之间,并且在每个 Region 中会关联多个存储的单元(Store)。
HRegion
Region 是真实存放 HBase 数据的地方,也就说 Region 是 HBase 可用性和分布式的基本单位;每个HRegion对应了Table中的一个Region,随着数据的不断加入,region会不断增大,当region增大一个阀值时,region会等分为两个region。当region分裂越来越多时,都将在Region Server上这时将无法满足负载均衡,所以Hmaster 将会发起协调的作用,将给table的所有region平均分配到所有的region Server上。
HRegion中由多个HStore组成。每个HStore对应了Table中的一个Column Family的存储,可以看出每个Column Family其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个Column Family中,这样最高效。HStore包括内存memstore 和位于磁盘的storeFile;数据写入时先进入memstore,当memstore中的数据到达阀值后,HRegion Server 会启动flashcache 进程将内存的数据写入磁盘storeFile。每次写入都会形成一个单独的storeFile文件。当storeFile文件的数量到达一个阀值时,系统会将storeFile文件合并,在合并时会进行版本的合并和删除文件(合并时会删除低版本的数据),形成一个更大的storeFile。在合并期间无法访问数据。
客服端查找数据时,先在memstroe查找,然后storeFile。
HLOG
以上是关于Hbase基本原理的主要内容,如果未能解决你的问题,请参考以下文章