的简单爬虫
Posted 扬州慢_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了的简单爬虫相关的知识,希望对你有一定的参考价值。
网络上一提到python,总会有一些不知道是黑还是粉的人大喊着:python是世界上最好的语言。最近利用业余时间体验了下python语言,并写了个爬虫爬取我csdn上关注的几个大神的博客,然后利用leancloud一站式后端云服务器存储数据,再写了一个android app展示数据,也算小试了一下这门语言,给我的感觉就是,像python这类弱类型的动态语言相比于java来说,开发者不需要分太多心去考虑编程问题,能够把精力集中于业务上,思考逻辑的实现。下面分享一下我此次写爬虫的一下小经验,抛砖引玉。
开发环境的搭建
登录python官网下载客户端,python现在分为python3和python2,即对应的官网上的版本为3.5和2.7,二者的异同有兴趣可以搜索一下,就我的了解,2和3的语法会有不同,而且有的库支持2不支持3,有的支持3不支持2等等;又比如urllib2库(一个用来获取URLs的模块)在python2上引用要import urllib2,而在python3里就变成import urllib.request。等等。纠结使用哪个版本没有意义,代码是为逻辑服务的,无论2或3很明显都可以满足我们这些初学者的需求。这里推荐一下廖学峰老师的python教程。很高质量的教程,2和3都有,嫌看视频学得慢的朋友可以试试。
但是这里有一个坑要提醒一下:如果你也和我一样想要使用leancloud做后端服务器,那得使用python2,无他,因为人家文档里写着暂不支持python3。╮(╯_╰)╭(6.28 更正:leancloud现已支持python3)
搭建环境的一些小坑:error2502/2503
下载客户端后,如果你点击安装后一切正常,那你可以忽略此步。如果出现安装失败error2502/2503,解决办法如下:
- 打开命令提示符(管理员),如果你是win8:按win键进入桌面模式,左下角右键打开命令提示符(管理员)
- 输入 msiexec /package “你安装程序包的路径”(例如:F:\\python)
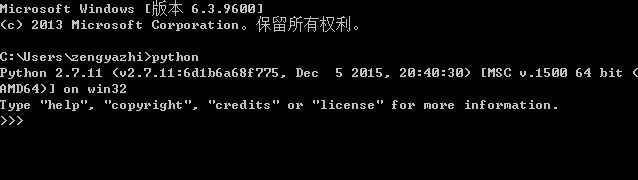
安装成功后配置环境变量(我的电脑-右键 属性-高级系统设置-环境变量)添加安装的目录(C:\\Python27)到path。之后打开命令行输入python,如果出现如下图三个小箭头则说明python解释器已经安装成功了。
安装pip和beautifulsoup:
pip,大家可以理解成相当于android studio的gradle,可以一键配置开源库到项目中(后续配置leancloud服务器也可以很方便的导入他们的模块)。beautifulsoup则是一个html解析器,使用它解析html标签方便又简单。
- 首先下载pip,下载 pip-8.1.2.tar.gz (md5, pgp)
- 解压后,打开cmd命令行,切换盘符,再cd 进入解压的目录,例如: cd D:\\pip-8.1.2
- 命令行里输入 python setup.py install ,看到finished processing等字样即安装成功
- 配置环境变量到path: C:\\Python27\\Scripts;
- cmd 运行 pip install beautifulsoup4 ,看到successfully installed即安装成功
另外再推荐一款编辑器:pycharm,JetBrains出品你懂的,InteliJ系列风格,使用这款编辑器你会感觉像是在使用android studio一样,至少设置个字体大小啥的都不陌生。
万事俱备,Let’s begin!
初识爬虫
因为我也才刚接触python,所以有一些代码可能很无脑且未经过优化,仅仅只为实现需求,so~下面就开始分享我写的一些python代码,以及写爬虫时遇到的一些小坑
伪装浏览器
CSDN禁止爬虫,所以要爬取之前就要把爬虫伪装成浏览器,在访问之前增加一个header:
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
agent = random.choice(user_agents) #每次随机抽取一个伪装的客户端浏览器版本号
req = urllib2.Request(self.url) #将要请求的地址映射成request对象,然后可以对其添加HTTP头
req.add_header('User-Agent', agent)
req.add_header('Host', 'blog.csdn.net')
req.add_header('Accept', '*/*')
req.add_header('Referer', 'http://blog.csdn.net/mangoer_ys?viewmode=list')
req.add_header('GET', url)
html = urllib2.urlopen(req) #将request对象传入urlopen方法,返回一个response对象
page = html.read().decode('utf-8') #调用read方法就可以获得html网页的信息了,主要还要对其转码为utf-8
这里就已经爬取到网页内容了(page),后面只要通过正则来解析你需要的数据,简单的爬虫其实就已经完成了。
现在来整理一下,我们到底需要一些什么数据?我的目的是爬取一个,甚至几个博主的全部博客,然后在手机上展示。那么就需要:
- 先访问给定的网址(博主的博客首页),并获取一篇博客的链接地址,然后让爬虫去访问该地址
- 获得这篇博文的标题,作者,发表时间、文章内容。这些是最基础的,也是必要的展示内容
- 获得这篇博文的id,作者的id,用来做后端存储数据的唯一标识
- 获得这篇博文底部的上一篇/下一篇博文按钮所链接的地址,并让爬虫访问改地址
- 循环往复,直到不存在上一篇/下一篇博文
创建一个类来执行第一个业务:
要注意的是:python的规定方法定义必须有额外的参数self指代其本身,类似java的this。
class Get_First_Url: #用于获取博客首页第一篇博文的地址的类
def __init__(self, url2): #类构造器,这里我们还传入一个url,即博客首页的地址
self.url = url2 #将参数赋值给类,python里可以任意添加成员变量而不用提前声明,要用的时候直接调用self.xxx
'''
伪装浏览器
'''
self.page = page #获取的网页信息
self.beginurl = self.getFirstUrl() #下面我们会定义一个方法来解析网页并保存一篇的地址
解析html标签
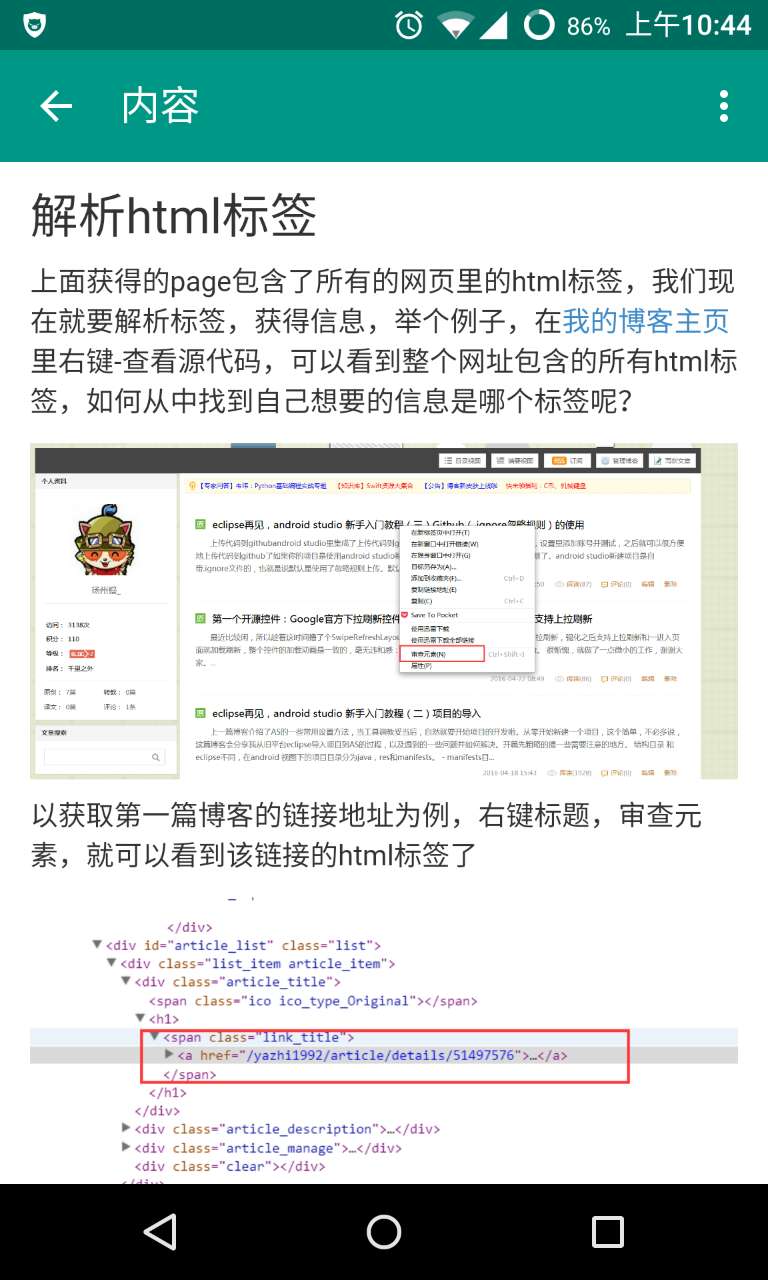
上面获得的page包含了所有的网页里的html标签,我们现在就要解析标签,获得信息,举个例子,在我的博客主页里右键-查看源代码,可以看到整个网址包含的所有html标签,如何从中找到自己想要的信息是哪个标签呢?
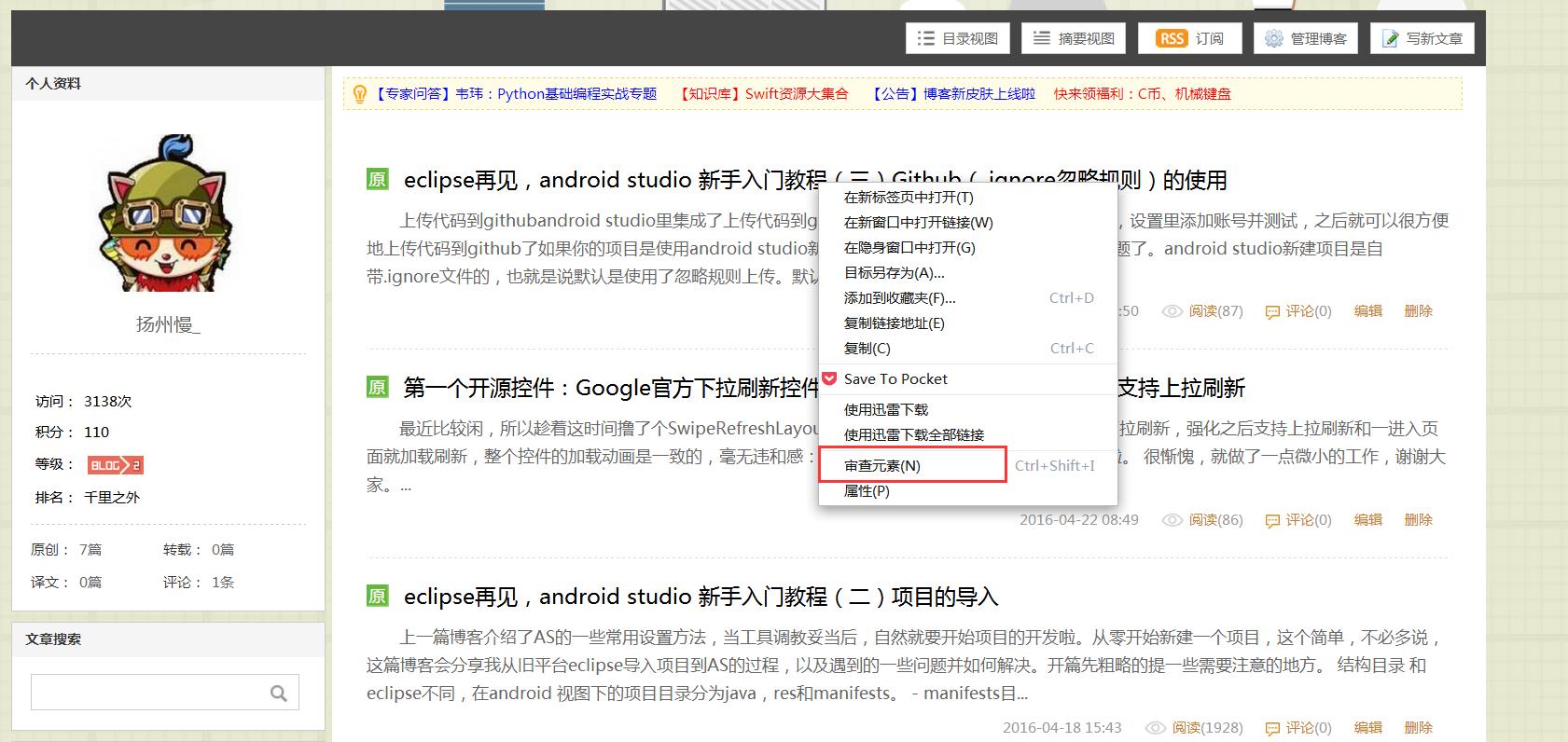
以获取第一篇博客的链接地址为例,右键标题,审查元素,就可以看到该链接的html标签了
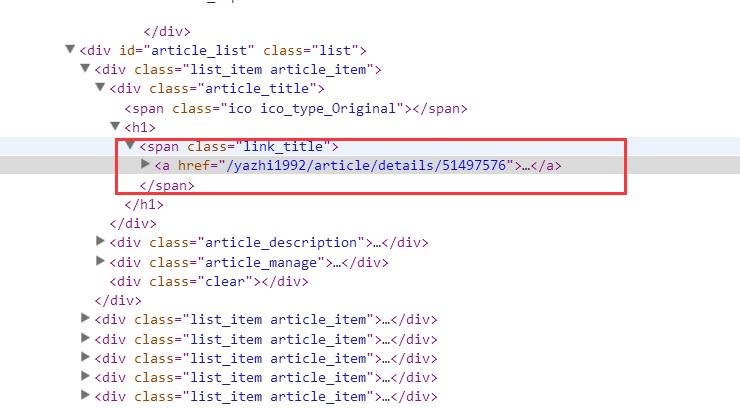
<span class="link_title">
<a href="/yazhi1992/article/details/51497576">
eclipse再见,android studio 新手入门教程(三)Github(.ignore忽略规则)的使用
</a>
</span>
很容易看出,博客地址就是csdn网址拼接span标签内的a标签的key为href对应的value值。为了得到这个值,就要使用breautifulsoup解析,我们定义一个方法:
def getFirstUrl(self):
bs = BeautifulSoup(self.page) #创建breautifulsoup对象
html_content_list = bs.find('span', class_='link_title') #获得key为class,value为link——title的span标签,因为class与python语法的关键字冲突,所以要使用 class_ 代替
if (html_content_list == None): #如果未找到该标签则返回'nourl'
return "no url"
try: #异常捕获
return 'http://blog.csdn.net' + html_content_list.a['href']
except Exception, e:
return "nourl"
所以到这里,我们就已经可以得到我们所需要的第一个数据了:
first_spider = Get_First_Url(now_url)
begin_url = first_spider.beginurl
获取其他数据方法类似,值得一提的是另一种标签的解析,需要的数据是标签内部的文字:
<div class="article_r">
<span class="link_postdate">I want this</span>
</div>
想要获得标签的内容
bs = BeautifulSoup(self.page) #创建breautifulsoup对象
html_content_list = bs.find('span', class_='link_postdate')
print html_content_list.string
我还遇到过想要获取时间2015-10-10 16:24这个值,但是执行上述代码会报错,提说说soup没有string这个值,那就需要对其做个转变为字符串的操作
print str(html_content_list.string)更多breautifulsoup的用法可以参考Python爬虫利器二之Beautiful Soup的用法
编码问题:python Non-ASCII character ‘\\xe5’ in file
如果你运行程序后报这个错,解决办法是在文件头添加:
#coding=utf-8
import sys
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
关于python的一些注意点:
talk is cheap,show you the code
切割字符串
str = 'this is test'
print str[:4] #输出结果 this
print str[3:] #输出结果 s is test
print str[1:4] #输出结果 his
不用多说,冒号“ : ”代表首或尾,和java一样的包左不包右。如果首尾都是数字,中间用冒号分割。
关于数组
list = []
print list[-2] #数组倒数第二个的值
关于全局变量
直接在外部定义全局变量,但是使用时需要用globla关键字表示
TEST = 'this is global variable'
class ...
def...
global TEST #使用关键字标识这个TEST是全局变量
print TEST #使用该变量
关于导包
IDE好像不能自动导包(我也没认真去翻setting)导包的话直接在文件头import相应的包,例如
from bs4 import BeautifulSoup #导breatifulsoup的包
import urllib2
import random
...等等
关于布尔类型True、False
python的布尔类型是首字母大写的(或者IDE可以设置忽略大小写联想,我没有去仔细翻)。(╯‵□′)╯︵┻━┻
其他
if(list==null||list.size == 0) { //java
...
} else {
...
}
if (list == None or len(list) == 0): #python
...
else:
...
因为我是爬取正文的html标签,然后在android端上使用webview展示,但是有个问题是webview里会显示电脑端的效果,字很小。查看手机端网页源代码后,发现在html标签头添加以下代码,就可以适配移动端浏览器:
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no">
<meta name="apple-mobile-web-app-status-bar-style" content="yes">
<script src="http://csdnimg.cn/public/common/libs/jquery/jquery-1.9.1.min.js" type="text/javascript"></script>
<!--link( rel="stylesheet" href="http://c.csdnimg.cn/public/common/toolbar/css/index.css" )-->
<link rel="stylesheet" href="http://csdnimg.cn/public/common/libs/bootstrap/css/bootstrap.css">
<link rel="stylesheet" href="http://csdnimg.cn/public/static/css/avatar.css">
<link rel="stylesheet" href="/static/css/common.css">
<!-- [if IE 7]-->
<!--link( rel="stylesheet" href="assets/css/font-awesome-ie7.min.css" )-->
<!-- [endif]-->
<link rel="stylesheet" href="/static/css/main.css">
<!-- [if lt IE 9]-->
<script src="/static/js/libs/html5shiv.min.js"></script>
<!-- [endif]-->
<title></title>
<script type="text/javascript" src="/static/js/apps/blog_mobile.js"></script>
</head>
另外,关于webview网页里图片自适应,4.4以前只需要:
WebSettings webSettings= contentWeb.getSettings();
webSettings.setLayoutAlgorithm(LayoutAlgorithm.SINGLE_COLUMN);但是在Android 4.4系统上 Google已经将系统默认的Webkit内核替换成自己的开源项目chromium,导致的一个问题就是上述代码失效了,解决方法请参考Android 中 WebView 与 js 简单交互实现图文混排效果,解决图片自适应屏幕与查看大图问题,亲测有效。
python爬虫源码下载,请替换自己的leancloud应用的id和key,具体如何在爬虫里上传数据,以及在app里如何读取数据,请阅读leancloud官方开发文档。
Stay hungry, Stay foolish。下篇博客见。
以上是关于的简单爬虫的主要内容,如果未能解决你的问题,请参考以下文章
爬虫遇到头疼的验证码?Python实战讲解弹窗处理和验证码识别
Python练习册 第 0013 题: 用 Python 写一个爬图片的程序,爬 这个链接里的日本妹子图片 :-),(http://tieba.baidu.com/p/2166231880)(代码片段