二分类模型评估指标
Posted yspxizhen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二分类模型评估指标相关的知识,希望对你有一定的参考价值。
分类结果混淆矩阵(confusion matrix):
| 真实\\预测 | 正例 | 反例 |
| 正例 | TP | FN |
| 反例 | FP | TN |
1.准确率--accuracy
定义:对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。
计算方法: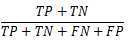
2.精确率--precision(P)
定义:被判定为正例(反例)的样本中,真正的正例样本(反例样本)的比例。
计算方法: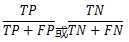
3.召回率--recall(R)
定义:被正确分类的正例(反例)样本,占所有正例(反例)样本的比例。
计算方法: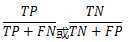
4.F1_score
定义:基于精确率和召回率的调和平均。
计算方法: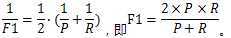
5.macro 度量
定义:对于n个二分类混淆矩阵,在各混淆矩阵上分别计算精确率和召回率,记(P1,R1),(P2,R2)...(Pn,Rn),再计算平均值,得到宏精确率(macro-P)、宏召回率(macro-R),继而得到宏F1(macro-F1)。
6.micro度量
定义:对于n个二分类混淆矩阵,先对TP、FN、FP、TN求平均值,再用均值计算得到微精确率(micro-P)、微召回率(micro-P),继而得到微F1(micro-F1)。
# -*-coding: utf-8 -*- import numpy #true = [真实组1,真实组2...真实组N],predict = [预测组1,预测组2...预测组N] def evaluation(true,predict): num = len(true)#确定有几组 (TP, FP, FN, TN) = ([0] * num for i in range(4))#赋初值 for m in range(0,len(true)): if(len(true[m]) != len(predict[m])):#样本数都不等,显然是有错误的 print "真实结果与预测结果样本数不一致。" else: for i in range(0,len(true[m])):#对每一组数据分别计数 if (predict[m][i] == 1) and ((true[m][i] == 1)): TP[m] += 1.0 elif (predict[m][i] == 1) and ((true[m][i] == 0)): FP[m] += 1.0 elif (predict[m][i] == 0) and ((true[m][i] == 1)): FN[m] += 1.0 elif (predict[m][i] == 0) and ((true[m][i] == 0)): TN[m] += 1.0 # macro度量,先求每一组的评价指标,再求均值 (accuracy_macro, precision1_macro, precision0_macro, recall1_macro, recall0_macro, F1_score1_macro,F1_score0_macro) = ([0] * num for i in range(7)) for m in range(0,num): accuracy_macro[m] = (TP[m] + TN[m]) / (TP[m] + FP[m] + FN[m] +TN[m]) if (TP[m] + FP[m] == 0) : precision1_macro[m] = 0#预防一些分母为0的情况 else :precision1_macro[m] = TP[m] / (TP[m] + FP[m]) if (TN[m] + FN[m] == 0) : precision0_macro[m] = 0 else :precision0_macro[m] = TN[m] / (TN[m] + FN[m]) if (TP[m] + FN[m] == 0) : recall1_macro[m] = 0 else :recall1_macro[m] = TP[m] / (TP[m] + FN[m]) if (TN[m] + FP[m] == 0) : recall0_macro[m] = 0 recall0_macro[m] = TN[m] / (TN[m] + FP[m]) macro_accuracy = numpy.mean(accuracy_macro) macro_precision1 = numpy.mean(precision1_macro) macro_precision0 = numpy.mean(precision0_macro) macro_recall1 = numpy.mean(recall1_macro) macro_recall0 = numpy.mean(recall0_macro) #F1_score还是按这个公式来算,用macro-P和macro-R if (macro_precision1 + macro_recall1 == 0): macro_F1_score1 = 0 else: macro_F1_score1 = 2 * macro_precision1 * macro_recall1 / (macro_precision1 + macro_recall1) if (macro_precision0 + macro_recall0 == 0): macro_F1_score0 = 0 else: macro_F1_score0 = 2 * macro_precision0 * macro_recall0 / (macro_precision0 + macro_recall0) #micro度量,是用TP、TN、FP、FN的均值来计算评价指标 TPM = numpy.mean(TP) TNM = numpy.mean(TN) FPM = numpy.mean(FP) FNM = numpy.mean(FN) micro_accuracy = (TPM + TNM) / (TPM + FPM + FNM + TNM) if(TPM + FPM ==0): micro_precision1 = 0#预防一些分母为0的情况 else: micro_precision1 = TPM / (TPM + FPM) if(TNM + FNM ==0): micro_precision0 = 0 else: micro_precision0 = TNM / (TNM + FNM) if (TPM + FNM == 0):micro_recall1 = 0 else: micro_recall1 = TPM / (TPM + FNM) if (TNM + FPM == 0):micro_recall0 = 0 else: micro_recall0 = TNM / (TNM + FPM) # F1_score仍然按这个公式来算,用micro-P和micro-R if (micro_precision1 + micro_recall1 == 0): micro_F1_score1 = 0 else :micro_F1_score1 = 2 * micro_precision1 * micro_recall1 / (micro_precision1 + micro_recall1) if (micro_precision0 + micro_recall0 == 0): micro_F1_score0 = 0 else :micro_F1_score0 = 2 * micro_precision0 * micro_recall0 / (micro_precision0 + micro_recall0) print "*****************************macro*****************************" print "accuracy",":%.3f" % macro_accuracy print "%20s"%‘precision‘,"%12s"%‘recall‘,"%12s"%‘F1_score‘ print "%5s" % "0", "%14.3f" % macro_precision0, "%12.3f" % macro_recall0, "%12.3f" %macro_F1_score0 print "%5s" % "1", "%14.3f" % macro_precision1, "%12.3f" % macro_recall1, "%12.3f" %macro_F1_score1 print "%5s" % "avg","%14.3f" % ((macro_precision0+macro_precision1)/2), "%12.3f" % ((macro_recall0+macro_recall1)/2), "%12.3f" %((macro_F1_score1+macro_F1_score0)/2) print "*****************************micro*****************************" print "accuracy",":%.3f" % micro_accuracy print "%20s"%‘precision‘,"%12s"%‘recall‘,"%12s"%‘F1_score‘ print "%5s" % "0", "%14.3f" % micro_precision0, "%12.3f" % micro_recall0, "%12.3f" %micro_F1_score0 print "%5s" % "1", "%14.3f" % micro_precision1, "%12.3f" % micro_recall1, "%12.3f" %micro_F1_score1 print "%5s" % "avg", "%14.3f" % ((micro_precision0 + micro_precision1) / 2), "%12.3f" % ((micro_recall0 + micro_recall1) / 2), "%12.3f" % ((micro_F1_score0 + micro_F1_score1) / 2) if __name__ == "__main__": #简单举例 - 当未采用交叉验证方法时,显然True和Predict都只有一组,Macro和Micro会输出一样的值 true = [[0, 1, 0, 1, 0], [0, 1, 1, 0]] predict = [[0, 1, 1, 1, 0], [0, 1, 0, 1]] evaluation(true,predict)
*****************************macro***************************** accuracy :0.650 precision recall F1_score 0 0.750 0.583 0.656 1 0.583 0.750 0.656 avg 0.667 0.667 0.656 *****************************micro***************************** accuracy :0.667 precision recall F1_score 0 0.750 0.600 0.667 1 0.600 0.750 0.667 avg 0.675 0.675 0.667
以上是关于二分类模型评估指标的主要内容,如果未能解决你的问题,请参考以下文章