数据的查找和提取[1]——正则表达式
Posted hiangxuup
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据的查找和提取[1]——正则表达式相关的知识,希望对你有一定的参考价值。
正则表达式
正则表达式其实没有大家说的那么神秘和困难,它是一种强大的字符串处理工具,有自己的一套书写规则。首先,看一个简答的例子来大致了解一下。
1.1 举例
比如给出一个字符串
Hello my name i1s HiangX
使用下面这个正则式子
^Helld\\s\\w\\w\\s\\w4\\s\\w\\d
就可以匹配到 ‘Hello my name i1‘ 这段字符串了
在学习之前观察这个乱糟糟的表达式或许会觉得很复杂,其实不然,它有着自己的规则:/s 用于匹配空白字符,/w 在这里用于匹配字母,/w4 在这里用于匹配四个字母
它的使用规则还有很多,具体见下方这个表格
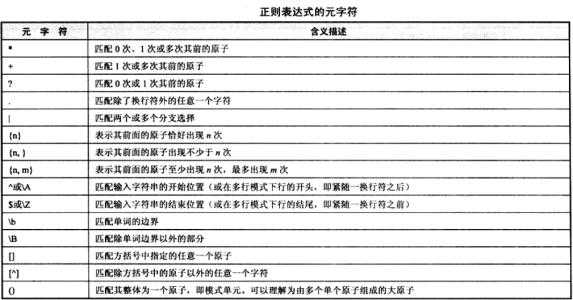
python有很多强大的库,其中re库中有很多函数可以帮助我们运用正则表达式进行匹配,下面就介绍我认为常用的几个
1.2match
这个函数是从字符串的首部开始检索与正则表达式匹配的字符串,具体的用法,还是用上面的例子来介绍一下
import re
content=‘Hello my name i1s HiangX‘
result=re.match(‘^Hello\\s\\w\\w\\s\\w4\\s\\w\\d‘,content)
print(result)
输出的结果和1.1相同,只是用程序进行表达。其中,match函数第一个参数是正则表达式,第二个参数是要匹配的内容
1.2.1对提取的目标再匹配
看完上面的例子,大家有没有疑问,如何选择提取字符串中的特定部分呢?这个问题早就已经解决啦,也就是用group这个函数!
还是上面的例子,如果正则表达式变成
^Hello\\s(\\w)\\w\\s\\w4\\s\\w\\d
在输出的时候使用print(result.group(1))就可以输出加括号部分提取的内容。值得注意的是,通常在比如说数组等数据结构中,下标总是错开一位,但是在这里比较特殊,正常的对齐,一定要注意!
1.2.2贪婪匹配与非贪婪匹配
还是刚才的例子
假如正则表达式变成
^Hello\\s.*\\d
那么匹配到的内容和上访相同,相信大家可以看出来了 .* 这两个的搭配,其实就是省略中间的字符,直到后面的字符。
现在在看另外一种方式:
^Hello.*\\w
这个式子的结果就不再是大家想象中的Hello m 而是整个句子!那是为什么呢?
其实,这种匹配方式叫做贪婪匹配,也就是尽可能多的匹配字符,所以上方那种情况会尽可能多的进行匹配,直到遇到最后一个字母X才结束
那这个问题如何解决呢?出现了非贪婪匹配,和之前的相反,就是尽可能少的匹配字符,用的符号是 .*?
如果将上方的改成
^Hello.*?\\w
那么结果就会变成Hello m
再总结一下!贪婪匹配和非贪婪匹配区别就是:
符号:贪婪匹配用 .* 而非贪婪匹配用.*?
功能:贪婪匹配主要是尽可能多的进行匹配 而非贪婪匹配主要是尽可能少的进行匹配
所以,通常情况下使用非贪婪匹配比较多
1.2.3转义匹配
在使用的过程中,不可避免的遇到一些字符串中含有特殊的字符。
在遇到这种情况时,只用在特殊字符前加上\\即可
注意:在分析html时,也经常会遇到换行符,这里的match不太能识别,所以要另外加上修饰符,常用的如下:
re.S 忽略换行符
re.I 大小写不敏感
re.L
re.M 多行进行匹配
re.U 使用Unicode字符集解析字符
re.X
1.3 search()
上一节中的match函数是从头进行匹配,如果头部不匹配,就直接失败,在使用过程中显然还不是很方便。然而这一节要介绍的search就不一样了,一起来看看吧!这个方法是进行全文的搜索和匹配,并且返回第一个匹配成功的字符串,使用方法和match()相同
1.4findall()
前面介绍过search是返回匹配成功的第一个字符串,那么这个方法是返回匹配到的所有字符串,但是返回的内容其实还是一个数组类型的数据,可以通过下标来选取匹配到的第几个字符串
1.5 sub()
这个方法,在有些时候可以发挥很大的作用。比如说在整理html代码的时候,有很多的标签,如果我想从这些标签中选取一部分数据出来,如果用提取的方法会很繁琐,特别长。
这时候,也可以选择把多余的部分删除掉,使整个html显得更加简洁,这里就是用到sub()函数进行解决
result=re.sub(‘<a.*?>|</a>‘,html,re.S)用这个方法就可以把所有的a标签全部去除,使结果更加简洁一些
1.6 compile()
这个函数主要运用了面向对象的思想,可以将一个正则表达式,compile成一个正则的对象,在后来程序的维护和改变的时候会更加的方便和灵活。
以上就是对于正则表达式的简单介绍,博主也在学习,想通过博客记录成长,有问题欢迎提出,一起讨论!下一篇介绍xpath的使用
以上是关于数据的查找和提取[1]——正则表达式的主要内容,如果未能解决你的问题,请参考以下文章
Java正则表达式介绍和使用规则(Pattern类Matcher类PatternSyntaxException类)