spark shuff机制
Posted tangsonghuai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark shuff机制相关的知识,希望对你有一定的参考价值。
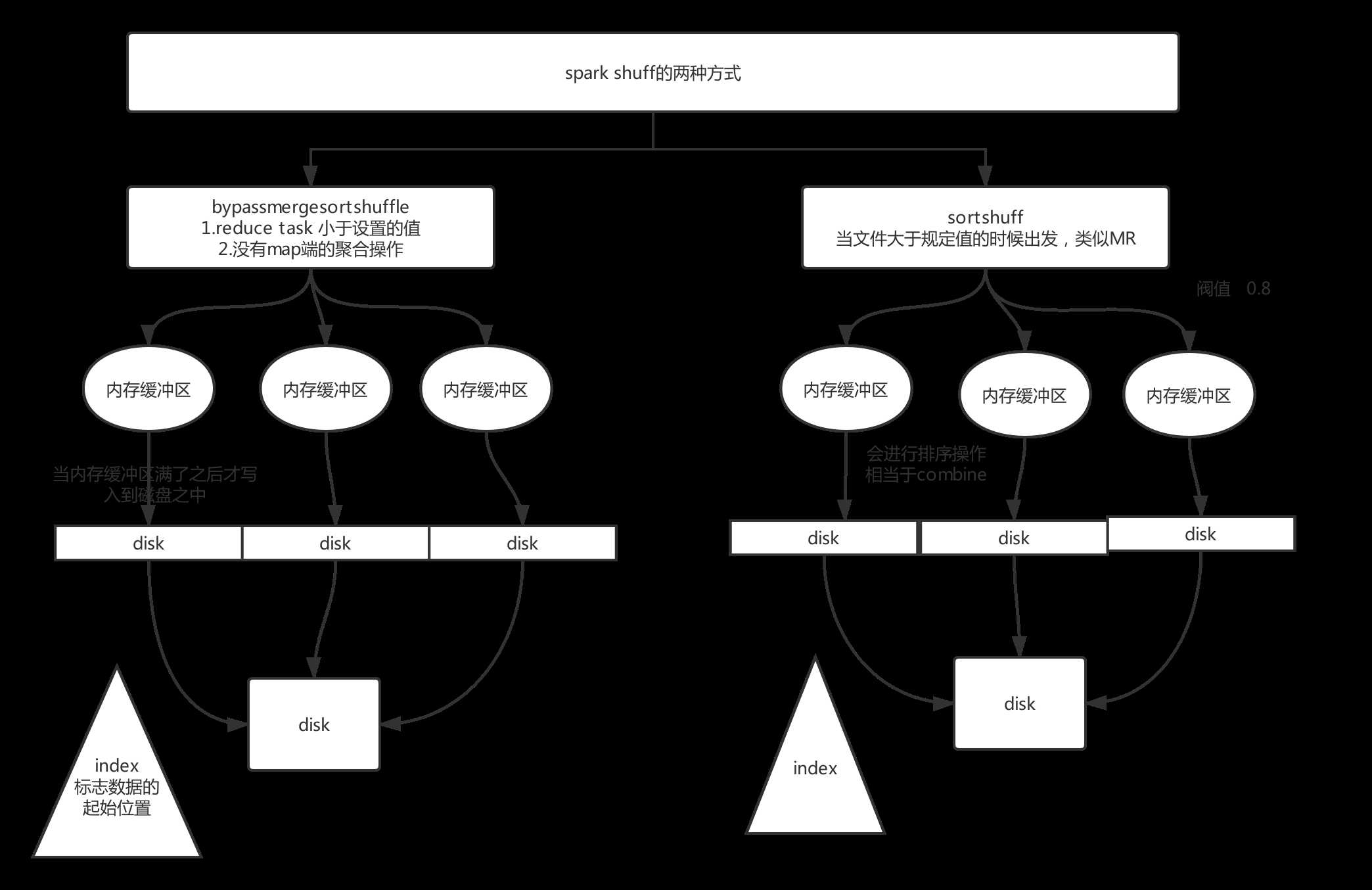
不同点在于,图一是内存缓冲区满了写入到磁盘,还没有进行sort操作
spark 数据倾斜优化:
1. 使用etl预处理数据 (为了防止某些key数据量过大的问题, 对数据进行提前聚合或和其他的表进行join操作)指标不治本,还会出现数据的倾斜问题
2.过滤少数导致倾斜的 key ,临界值,极点的问题
3.提高shuff的并行度 多个task执行一个key的数据,减少每个key面临的压力
4.将reduce join转化为 mapjoin 在join的一方数据比较小的时候使用, 广播变量加map算子实现join操作
以上是关于spark shuff机制的主要内容,如果未能解决你的问题,请参考以下文章