Python 爬虫
Posted ch-tnt
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 爬虫相关的知识,希望对你有一定的参考价值。
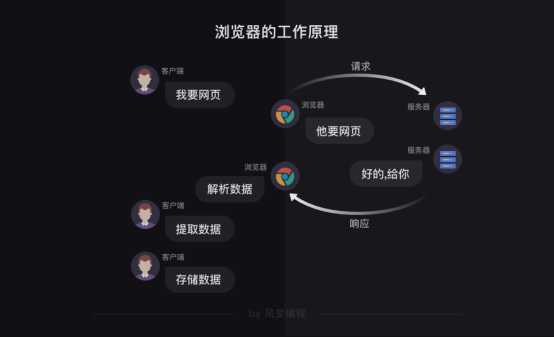
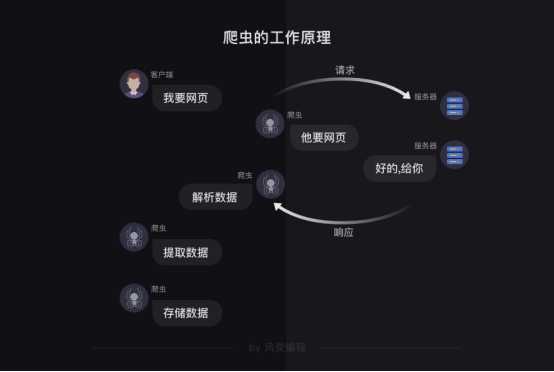
爬虫的工作原理
首先,爬虫可以模拟浏览器去向服务器发出请求;
其次,等服务器响应后,爬虫程序还可以代替浏览器帮我们解析数据;
接着,爬虫可以根据我们设定的规则批量提取相关数据,而不需要我们去手动提取;
最后,爬虫可以批量地把数据存储到本地
爬虫的步骤

第0步:获取数据。爬虫程序会根据我们提供的网址,向服务器发起请求,然后返回数据。
第1步:解析数据。爬虫程序会把服务器返回的数据解析成我们能读懂的格式。
第2步:提取数据。爬虫程序再从中提取出我们需要的数据。
第3步:储存数据。爬虫程序把这些有用的数据保存起来,便于你日后的使用和分析。
#######################################################################
Mac pip3 install requests
Win pip install requests
requests库可以帮我们下载网页源代码、文本、图片,甚至是音频
import requests
#引入requests库
res = requests.get(‘URL‘)
#requests.get是在调用requests库中的get()方法,它向服务器发送了一个请求,括号里的参数是你需要的数据所在的网址,然后服务器对请求作出了响应。
#我们把这个响应返回的结果赋值在变量res上。

##############################################################
Response对象的常用属性

response.status_code
print(变量.status_code)
用来检查请求是否正确响应,如果响应状态码为200,即代表请求成功
response.content
把Response对象的内容以二进制数据的形式返回,适用于图片、音频、视频的下载
import requests
res = requests.get(‘https://res.pandateacher.com/2018-12-18-10-43-07.png‘)
#发出请求,并把返回的结果放在变量res中
pic=res.content
#把Reponse对象的内容以二进制数据的形式返回
photo = open(‘ppt.jpg‘,‘wb‘)
#新建了一个文件ppt.jpg,这里的文件没加路径,它会被保存在程序运行的当前目录下。
#图片内容需要以二进制wb读写。你在学习open()函数时接触过它。
photo.write(pic)
#获取pic的二进制内容
photo.close()
#关闭文件
response.text
把Response对象的内容以字符串的形式返回,适用于文字、网页源代码的下载
import requests
#引用requests库
res = requests.get(‘https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md‘)
#下载《三国演义》第一回,我们得到一个对象,它被命名为res
novel=res.text
#把Response对象的内容以字符串的形式返回
print(novel[:800])
#现在,可以打印小说了,但考虑到整章太长,只输出800字看看就好。在关于列表的知识那里,你学过[:800]的用法。
k = open(‘《三国演义》.txt‘, ‘a+‘)
k.write(novel)
k.close()
response.encoding
#语法:res.encoding=‘‘
import requests
#引用requests库
res = requests.get(‘https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md‘)
#下载《三国演义》第一回,我们得到一个对象,它被命名为res
res.encoding=‘utf-8‘
#定义Reponse对象的编码为utf-8。
novel=res.text
#把Response对象的内容以字符串的形式返回
print(novel[:800])
#打印小说的前800个字。
定义Response对象的编码
遇上文本的乱码问题,才考虑用res.encoding
目标数据本身是什么编码是未知的。
用requests.get()发送请求后,我们会取得一个Response对象,其中,requests库会对数据的编码类型做出自己的判断。
但是!这个判断有可能准确,也可能不准确。
如果它判断准确的话,我们打印出来的response.text的内容就是正常的、没有乱码的,那就用不到res.encoding;
如果判断不准确,就会出现一堆乱码,那我们就可以去查看目标数据的编码,然后再用res.encoding把编码定义成和目标数据一致的类型即可。

####################################################################
Robots协议
“网络爬虫排除标准”(Robots exclusion protocol),这个协议用来告诉爬虫,哪些页面是可以抓取的,哪些不可以。
#查看robots协议 网站的域名后加上/robots.txt
User-agent: Baiduspider #百度爬虫
Allow: /article #允许访问 /article.htm
Allow: /oshtml #允许访问 /oshtml.htm
Allow: /ershou #允许访问 /ershou.htm
Allow: /$ #允许访问根目录,即淘宝主页
Disallow: /product/ #禁止访问/product/
Disallow: / #禁止访问除 Allow 规定页面之外的其他所有页面
?
User-Agent: Googlebot #谷歌爬虫
Allow: /article
Allow: /oshtml
Allow: /product #允许访问/product/
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Allow: /ershou
Allow: /$
Disallow: / #禁止访问除 Allow 规定页面之外的其他所有页面
?
…… # 文件太长,省略了对其它爬虫的规定,想看全文的话,点击上面的链接
?
User-Agent: * #其他爬虫
Disallow: / #禁止访问所有页面
爬取时,先看看网站的Robots协议是否允许你去爬取
限制好爬虫的速度
以上是关于Python 爬虫的主要内容,如果未能解决你的问题,请参考以下文章