我是如何学习写一个操作系统:内存管理和段页机制
Posted secoding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我是如何学习写一个操作系统:内存管理和段页机制相关的知识,希望对你有一定的参考价值。
前言
多进程和内存管理是紧密相连的两个模块,因为运行进程也就是从内存中取指执行,创建进程首先要将程序和数据装入内存。将用户原程序变成可在内存中执行的程序,而这就涉及到了内存管理。
内存的装入
绝对装入。
在编译时,如果知道程序将驻留在内存的某个位置,编译程序将产生绝对地址的目标代码。绝对装入程序按照装入模块的地址,将程序和数据装入内存。装入模块被装入内存后,由于程序中的逻辑地址与实际地址完全相同,故不需对程序和数据的地址进行修改。
可重定位装入。
在多道程序环境下,多个目标模块的起始地址通常都是从0开始,程序中的其他地址都是相对于起始地址的,此时应采用可重定位装入方式。根据内存的当前情况,将装入模块装入到内存的适当位置。装入时对目标程序中指令和数据的修改过程称为重定位,地址变换通常是装入时一次完成,所以成为静态重定位。
其特点是在一个作业装入内存时,必须分配器要求的全部内存空间,如果没有足够的内存,就不能装入,此外一旦作业进入内存后,在整个运行期间,不能在内存中移动,也不能再申请内存空间。动态运行时装入
也成为动态重定位,程序在内存中如果发生移动,就需要采用动态的装入方式。
动态运行时的装入程序在把装入模块装入内存后,并不立即把装入模块中的相对地址转换为绝对地址,而是把这种地址转换推迟到程序真正要执行时才进行。因此,装入内存后的所有地址均为相对地址,这种方式需要一个重定位寄存器的支持。
其特点是可以将程序分配到不连续的存储区中;在程序运行之前可以只装入它的部分代码即可运行,然后在程序运行期间,根据需要动态申请分配内存;便于程序段的共享,可以向用户提供一个比存储空间大得多的地址空间。
所以装入内存的最好方法应该就是动态运行时的装入,但是这种方法需要一个方法来进行重定位。这个重定位的信息就保存在每个进程的PCB中,也就是保存这块内存的基地址,所以最后在运行时的地址就是逻辑地址 + 基地址,而硬件也提供了相应计算的支持,也就是MMU
分段机制
但是在程序员眼里:程序由若干部分(段)组成,每个段有各自的特点、用途:代码段只读,代码/数据段不会动态增长...。这样就引出了对内存进行分段
分段
假如用户进程由主程序、两个字程序、栈和一段数据组成,于是可以把这个用户进程划分为5个段,每段从0开始编址,并采用一段连续的地址空间(段内要求连续,段间不要求连续),其逻辑地址由两部分组成:段号与段内偏移量,分别记为S、W。
段号为16位,段内偏移量为16位,则一个作业最多可有2的16次方16=65536个段,最大段长64KB。
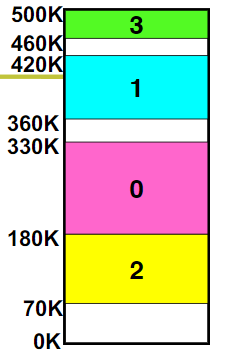
GDT和LDT
每个进程都有一张逻辑空间与主存空间映射的段表,其中每一段表项对应进程的一个段,段表项纪录路该段在内存中的起始地址和段的长度。在配置了段表后,执行中的进程可通过查找段表,找到每个段所对应的内存区。段表用于实现从逻辑端段到物理内存区的映射。
而这个段表就是之前在保护模式提到的GDT和LDT
一个处理器只有一个GDT。LDT(局部描述表),一个进程一个LDT,实际上是GTD的一个“子表”。
LDT和GDT从本质上说是相同的,只是LDT嵌套在GDT之中。
有一个专门的寄存器LDTR来记录局部描述符表的起始位置,记录的是在GDT中的一个段选择子。所以本质上LDT是一个段描述符,这个描述符就存储在GDT中,对应这个表述符也会有一个选择子。

内存分区和分页
在用了分段机制后,那么就需要对内存进行分区,让各个段载入到相应的内存分区中
内存分配算法
在进程装入或换入主存时。如果内存中有多个足够大的空闲块,操作系统必须确定分配那个内存块给进程使用,通常有这几种算法
首次适应算法:空闲分区以地址递增的次序链接。分配内存时顺序查找,找到大小能满足要求的第一个空闲分区。
- 最佳适应算法:空闲分区按容量递增形成分区链,找到第一个能满足要求的空闲分区。
- 最坏适应算法:有称最大适应算法,空闲分区以容量递减次序链接。找到第一个能满足要求的空闲分区,也就是挑选最大的分区。
临近适应算法:又称循环首次适应算法,由首次适应算法演变而成。不同之处是分配内存时从此查找结束的位置开始继续查找。
内存分页
引入内存分页就是为了解决在进行内存分区时导致的内存效率问题
分页就是把真正的内存空间划分为大小相等且固定的块,块相对较小,作为内存的基本单位。每个进程也以块为单位进行划分,进程在执行时,以块为单位逐个申请主存中的块空间。所以这时候对真正的物理内存地址的映射就不能再用分段机制的那套了
就引入了页表概念:系统为每个进程建立一张页表,记录页面在内存中对应的物理块号,所以对地址的转换变成了对页表的转换
在系统中通常设置一个页表寄存器PTR,存放页表在内存的初值和页表长度。
地址分为页号和页内偏移量两部分,再用页号去检索页表。。
将页表始址与页号和页表项长度的乘积相加,便得到该表项在页表中的位置,于是可从中得到该页的物理块号。
但是页表还是有两个问题:
- 页表占用的内存大
- 页表需要频繁的进行地址访问,所以访存速度必须非常快
多级页表
为了解决页表占用的内存太大,就引入了多级页表
页目录有2的十次方个4字节的表项,这些表项指向对应的二级表,线性地址的最高10位作为页目录用来寻找二级表的索引
二级页表里的表项含有相关页面的20位物理基地址,二级页表使用线性地址中间10位来作为寻找表项的索引
- 进程访问某个逻辑地址
- 由线性地址中的页号,以及外层页表寄存器(CR3)中的外层页表始址,找到二级页表的始址
- 由二级页表的始址,加上线性地址中的外层页内地址,找到对应的二级页表中的页表项
- 由页表项中的物理块号,加上线性地址中的页内地址,找到对物理地址
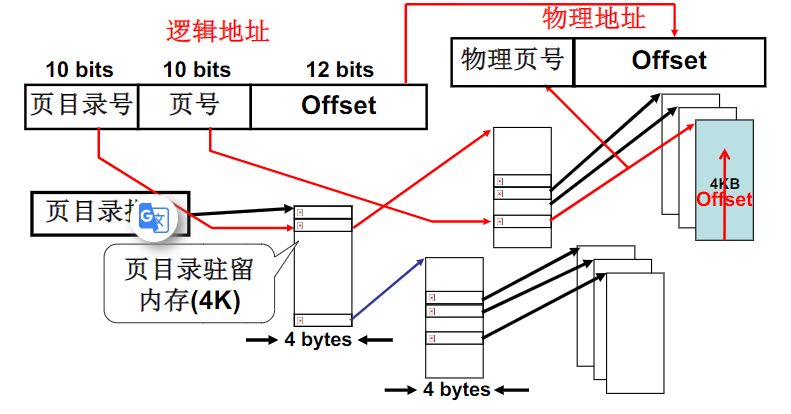
快表
为了解决访存速度,就有了快表
在系统中通常设置一个页表寄存器PTR,存放页表在内存的初值和页表长度。
CPU给出有效地址后,由硬件进行地址转换,并将页号送入高速缓存寄存器,并将此页号与快表中的所有页号同时进行比较。
如果有找到匹配的页号,说明索要访问的页表项在快表中,则可以直接从中读出该页对应的页框号。
如果没有找到,则需要访问主存中的页表,在读出页表项后,应同时将其存入快表中,以供后面可能的再次访问。但是如果快表已满,就必须按照一定的算法对其中旧的页表项进行替换。
段页结合(虚拟内存)
既然有了段和页,程序员希望能用段,计算机设计希望用页,那么就需要将二者结合
所以逻辑地址和物理地址的转换:
首先将给定一个逻辑地址,
利用其段式内存管理单元,也就是GDT中的断描述符,先将为个逻辑地址转换成一个线性地址,
再利用页式内存管理单元查表,转换为物理地址。
虚拟内存的管理
在实际的操作上,很有可能当前可用的物理内存远小于分配的虚拟内存(4G),这时候就需要请求掉页功能和页面置换功能,也就是在进行地址转换的时候找不到对应页,就启动页错误处理程序来完成调页
这样在页表项中增加了四个段:
状态位P:用于指示该页是否已调入内存,共程序访问时参考。
访问字段A:用于记录本页在一段时间内被访问的次数,或记录本页最近已有多长时间未被访问,供置换算法换出页面时参考。
修改位M:表示该页在调入内存后是否被修改过。
外存地址:用于指出该也在外存上的地址,通常是物理块号,供调入该页时参考。
所以现在在查找物理地址的时候就变成了:
先检索快表
若找到要访问的页,边修改页表中的访问位,然后利用页表项中给出的物理块号和页内地址形成物理地址。
若为找到该页的页表项,应到内存中去查找页表,在对比页表项中的状态位P,看该页是否已调入内存,未调入则产生缺页中断,请求从外存把该页调入内存。
页面置换算法
既然有页面的换入换出,那自然就会有相应的不同的算法
最佳置换算法所选择的被淘汰页面将是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若干页面中那个是未来最长时间内不再被访问的,但是这种算法无法实现。
LRU算法
选择最近最长时间未访问过的页面予以淘汰,他认为过去一段时间内未访问过的页面,在最近的将来可能也不会被访问。该算法为每个页面设置一个访问字段,来记录页面自上次被访问以来所经历的时间,淘汰页面时选择现有页面中值最大的予以淘汰。
LRU算法一般有两种实现:
每次地址访问都修改时间戳,淘汰页的时候只需要选择次数最少的即可
但是需维护一个全局时钟,需找到最小值,实现代价较大
- 页码栈
在每次地址访问的时候都修改栈,这样在淘汰的时候,只需要将栈底换出
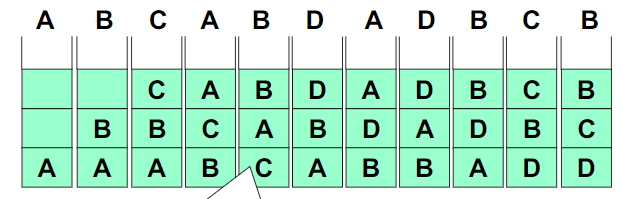
但是和上面用时间戳的方法一样,实现的代价都非常大
CLOCK算法
给每个页帧关联一个使用位。当该页第一次装入内存或者被重新访问到时,将使用位置为1。每次需要替换时,查找使用位被置为0的第一个帧进行替换。在扫描过程中,如果碰到使用位为1的帧,将使用位置为0,在继续扫描。如果所谓帧的使用位都为0,则替换第一个帧
CLOCK算法的性能比较接近LRU,而通过增加使用的位数目,可是使得CLOCK算法更加高效。在使用位的基础上再增加一个修改位,则得到改进型的CLOCK置换算法。这样,每一帧都出于以下四种情况之一。
- 最近未被访问,也未被修改(u=0,m=0)。
- 最近被访问,但未被修改(u=1,m=0)。
- 最近未被访问,但被修改(u=0,m=1)。
- 最近被访问,被修改(u=1,m=1)。
算法执行如下操作步骤:
- 从指针的当前位置开始,扫描帧缓冲区。在这次扫描过程中,对使用位不作任何修改,选择遇到的第一个帧(u=0,m=0)用于替换。
- 如果第1步失败,则重新扫描,查找(u=0,m=1)的帧。选额遇到的第一个这样的帧用于替换。在这个扫面过程中,对每个跳过的帧,把它的使用位设置成0.
- 如果第2步失败,指针将回到它的最初位置,并且集合中所有帧的使用位均为0.重复第一步,并且如果有必要重复第2步。这样将可以找到供替换的帧。
改进型的CLOCK算法优于简单的CLOCK算法之处在于替换时首选没有变化的页。由于修改过的页在被替换之前必须写回,因而这样做会节省时间。
Linux 0.11的故事
所有有关管理内存都是为了服务进程而诞生的,所以先来看一下Linux 0.11里从创建进程开始的故事
fork
- 首先通过系统调用的中断来创建进程,fork()->sys_fork->copy_process
- copy_process的主要作用就是为子进程创建TSS描述符、分配内存和文件设定等等
- copy_mem这里仅为新进程设置自己的页目录表项和页表项,而没有实际为新进程分配物理内存页面。此时新进程与其父进程共享所有内存页面。
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,
long ebx,long ecx,long edx,
long fs,long es,long ds,
long eip,long cs,long eflags,long esp,long ss)
struct task_struct *p;
int i;
struct file *f;
p = (struct task_struct *) get_free_page();
if (!p)
return -EAGAIN;
task[nr] = p;
*p = *current; /* NOTE! this doesn't copy the supervisor stack */
p->state = TASK_UNINTERRUPTIBLE;
p->pid = last_pid;
p->father = current->pid;
p->counter = p->priority;
p->signal = 0;
p->alarm = 0;
p->leader = 0; /* process leadership doesn't inherit */
p->utime = p->stime = 0;
p->cutime = p->cstime = 0;
p->start_time = jiffies;
p->tss.back_link = 0;
p->tss.esp0 = PAGE_SIZE + (long) p;
p->tss.ss0 = 0x10;
p->tss.eip = eip;
p->tss.eflags = eflags;
p->tss.eax = 0;
p->tss.ecx = ecx;
p->tss.edx = edx;
p->tss.ebx = ebx;
p->tss.esp = esp;
p->tss.ebp = ebp;
p->tss.esi = esi;
p->tss.edi = edi;
p->tss.es = es & 0xffff;
p->tss.cs = cs & 0xffff;
p->tss.ss = ss & 0xffff;
p->tss.ds = ds & 0xffff;
p->tss.fs = fs & 0xffff;
p->tss.gs = gs & 0xffff;
p->tss.ldt = _LDT(nr);
p->tss.trace_bitmap = 0x80000000;
if (last_task_used_math == current)
__asm__("clts ; fnsave %0"::"m" (p->tss.i387));
if (copy_mem(nr,p))
task[nr] = NULL;
free_page((long) p);
return -EAGAIN;
for (i=0; i<NR_OPEN;i++)
if ((f=p->filp[i]))
f->f_count++;
if (current->pwd)
current->pwd->i_count++;
if (current->root)
current->root->i_count++;
if (current->executable)
current->executable->i_count++;
set_tss_desc(gdt+(nr<<1)+FIRST_TSS_ENTRY,&(p->tss));
set_ldt_desc(gdt+(nr<<1)+FIRST_LDT_ENTRY,&(p->ldt));
p->state = TASK_RUNNING; /* do this last, just in case */
return last_pid;
int copy_mem(int nr,struct task_struct * p)
unsigned long old_data_base,new_data_base,data_limit;
unsigned long old_code_base,new_code_base,code_limit;
code_limit=get_limit(0x0f);
data_limit=get_limit(0x17);
old_code_base = get_base(current->ldt[1]);
old_data_base = get_base(current->ldt[2]);
if (old_data_base != old_code_base)
panic("We don't support separate I&D");
if (data_limit < code_limit)
panic("Bad data_limit");
new_data_base = new_code_base = nr * 0x4000000;
p->start_code = new_code_base;
set_base(p->ldt[1],new_code_base);
set_base(p->ldt[2],new_data_base);
if (copy_page_tables(old_data_base,new_data_base,data_limit))
printk("free_page_tables: from copy_mem\n");
free_page_tables(new_data_base,data_limit);
return -ENOMEM;
return 0;
page
- copy_page_tables就是复制页目录表项和页表项,从而被复制的页目录和页表对应的原物理内存页面区被两套页表映射而共享使用。复制时,需申请新页面来存放新页表,原物理内存区将被共享。此后两个进程(父进程和其子进程)将共享内存区,直到有一个进程执行操作时,内核才会为写操作进程分配新的内存页(写时复制机制)。
int copy_page_tables(unsigned long from,unsigned long to,long size)
unsigned long * from_page_table;
unsigned long * to_page_table;
unsigned long this_page;
unsigned long * from_dir, * to_dir;
unsigned long nr;
if ((from&0x3fffff) || (to&0x3fffff))
panic("copy_page_tables called with wrong alignment");
from_dir = (unsigned long *) ((from>>20) & 0xffc); /* _pg_dir = 0 */
to_dir = (unsigned long *) ((to>>20) & 0xffc);
size = ((unsigned) (size+0x3fffff)) >> 22;
for( ; size-->0 ; from_dir++,to_dir++)
if (1 & *to_dir)
panic("copy_page_tables: already exist");
if (!(1 & *from_dir))
continue;
from_page_table = (unsigned long *) (0xfffff000 & *from_dir);
if (!(to_page_table = (unsigned long *) get_free_page()))
return -1; /* Out of memory, see freeing */
*to_dir = ((unsigned long) to_page_table) | 7;
nr = (from==0)?0xA0:1024;
for ( ; nr-- > 0 ; from_page_table++,to_page_table++)
this_page = *from_page_table;
if (!(1 & this_page))
continue;
this_page &= ~2;
*to_page_table = this_page;
if (this_page > LOW_MEM)
*from_page_table = this_page;
this_page -= LOW_MEM;
this_page >>= 12;
mem_map[this_page]++;
invalidate();
return 0;
no_page
如果找不到相应的页,也就是要执行换入和换出了,在此之前CPU会先触发缺页异常
- 缺页异常中断的处理,会调用do_no_page
page_fault:
xchgl %eax,(%esp) # 取出错码到eax
pushl %ecx
pushl %edx
push %ds
push %es
push %fs
movl $0x10,%edx # 置内核数据段选择符
mov %dx,%ds
mov %dx,%es
mov %dx,%fs
movl %cr2,%edx # 取引起页面异常的线性地址
pushl %edx # 将该线性地址和出错码压入栈中,作为将调用函数的参数
pushl %eax
testl $1,%eax # 测试页存在标志P(为0),如果不是缺页引起的异常则跳转
jne 1f
call do_no_page # 调用缺页处理函数
jmp 2f
1: call do_wp_page # 调用写保护处理函数
2: addl $8,%esp # 丢弃压入栈的两个参数,弹出栈中寄存器并退出中断。
pop %fs
pop %es
pop %ds
popl %edx
popl %ecx
popl %eax
iret- 该函数首先尝试与已加载的相同文件进行页面共享,或者只是由于进程动态申请内存页面而只需映射一页物理内存即可。若共享操作不成功,那么只能从相应文件中读入所缺的数据页面到指定线性地址处。
void do_no_page(unsigned long error_code,unsigned long address)
int nr[4];
unsigned long tmp;
unsigned long page;
int block,i;
address &= 0xfffff000;
tmp = address - current->start_code;
if (!current->executable || tmp >= current->end_data)
get_empty_page(address);
return;
if (share_page(tmp))
return;
if (!(page = get_free_page()))
oom();
/* remember that 1 block is used for header */
block = 1 + tmp/BLOCK_SIZE;
for (i=0 ; i<4 ; block++,i++)
nr[i] = bmap(current->executable,block);
bread_page(page,current->executable->i_dev,nr);
i = tmp + 4096 - current->end_data;
tmp = page + 4096;
while (i-- > 0)
tmp--;
*(char *)tmp = 0;
if (put_page(page,address))
return;
free_page(page);
oom();
小结
这一篇的篇幅很长,因为把有关内存管理的东西都写在一起了,主要有三个关键点:
分段
对内存的分段引申的GDT和IDT来进行物理地址的寻址
分页
再由于分段引出的内存分区,为了提高效率而引入的分页机制,重点就是用页式内存管理单元查表
- 段页结合
所以为了将段和页结合就需要一个机制来转化逻辑地址和物理地址,也就分为两步走利用其段式内存管理单元,也就是GDT中的断描述符,先将为个逻辑地址转换成一个线性地址,
再利用页式内存管理单元查表,转换为物理地址。
以上是关于我是如何学习写一个操作系统:内存管理和段页机制的主要内容,如果未能解决你的问题,请参考以下文章