基于flink的协同过滤
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于flink的协同过滤相关的知识,希望对你有一定的参考价值。
最近flink较火,尝试使用flink做推荐功能试试,说干就干,话说flink-ml确实比较水,包含的算法较少,且只支持scala版本,以至flink1.9已经将flink-ml移除,看来是准备有大动作,但后期的实时推荐,flink能派上大用场。所幸基于物品的协同过滤算法相对简单,实现起来难度不大。先看目前推荐整体的架构。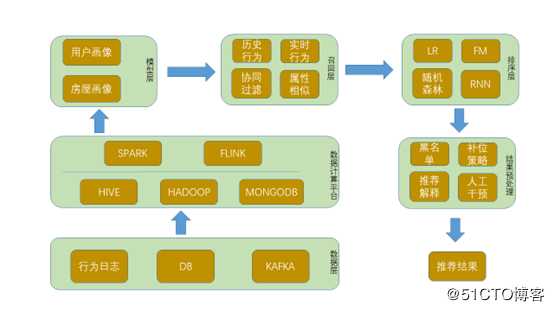
先说一下用到的相似算法:
X=(x1, x2, x3, … xn),Y=(y1, y2, y3, … yn)
那么欧式距离为:
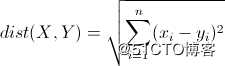
很明显,值越大,相似性越差,如果两者完全相同,那么距离为0。
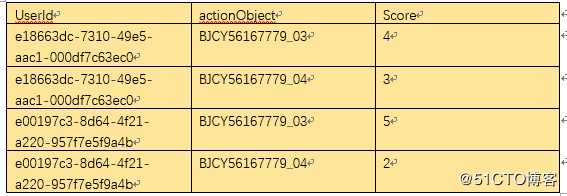
第一步准备数据,数据的格式如下:
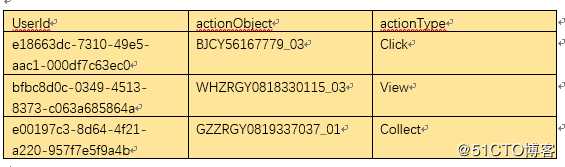
actionObject 是房屋的编号,actionType是用户的行为,包括曝光未点击,点击,收藏等。
下面的代码是从hdfs中获取数据,并将view事件的数据清除,其他的行为转化为分数
public static DataSet<Tuple2<Tuple2<String, String>, Float>> getData(ExecutionEnvironment env, String path)
DataSet<Tuple2<Tuple2<String, String>, Float>> res= env.readTextFile(path).map(new MapFunction<String, Tuple2<Tuple2<String, String>, Float>> ()
@Override
public Tuple2<Tuple2<String, String>, Float> map(String value) throws Exception
JSONObject jj=JSON.parseObject(value);
if(RecommendUtils.getValidAction(jj.getString("actionType")))
return new Tuple2<>(new Tuple2<>(jj.getString("userId"),jj.getString("actionObject")),RecommendUtils.getScore(jj.getString("actionType")));
else
return null;
).filter(new FilterFunction<Tuple2<Tuple2<String, String>, Float>>()
@Override
public boolean filter(Tuple2<Tuple2<String, String>, Float> value) throws Exception
return value!=null;
);
return res;
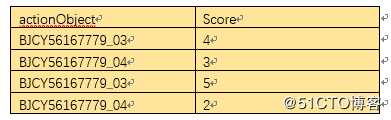
数据经过简单的清洗后变成如下的格式
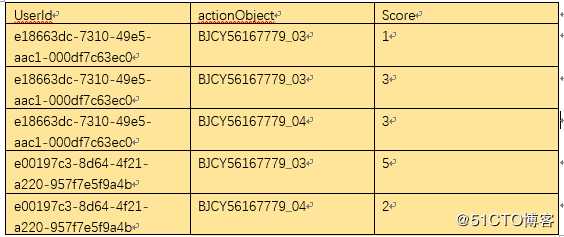
按照前两列聚合,
groupBy(0).reduce(new ReduceFunction<Tuple2<Tuple2<String, String>, Float>>()
@Override
public Tuple2<Tuple2<String, String>, Float> reduce(Tuple2<Tuple2<String, String>, Float> value1,
Tuple2<Tuple2<String, String>, Float> value2) throws Exception
// TODO Auto-generated method stub
return new Tuple2<>(new Tuple2<>(value1.f0.f0, value1.f0.f1),(value1.f1+value2.f1));
)结构变成
此时,理论上BJCY56167779_03,BJCY56167779_04 的相似度为 (4-3) ^2+(5-2) ^2, 再开方,继续前进。
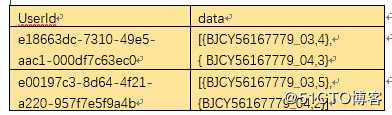
去掉第一列,格式如下
因为:
(x1-y1)^2+(x2-y2)^2=x1^2+y1^2-2x1y1+x2^2+y2^2-2x2y2=x1^2+y1^2+x2^2+y2^2-2(x1y1+x2y2), 所以我们先求x1^2+x2^2的值,并注册为item表
.map(new MapFunction<Tuple2<String, Float>, Tuple2<String, Float>>()
@Override
public Tuple2<String, Float> map(Tuple2<String, Float> value) throws Exception
return new Tuple2<>(value.f0, value.f1*value.f1);
).
groupBy(0).reduce(new ReduceFunction<Tuple2<String, Float>>()
@Override
public Tuple2<String, Float> reduce(Tuple2<String, Float> value1, Tuple2<String, Float> value2)
throws Exception
Tuple2<String, Float> temp= new Tuple2<>(value1.f0, value1.f1 + value2.f1);
return temp;
).map(new MapFunction<Tuple2<String, Float>, ItemDTO> ()
@Override
public ItemDTO map(Tuple2<String, Float> value) throws Exception
ItemDTO nd=new ItemDTO();
nd.setItemId(value.f0);
nd.setScore(value.f1);
return nd;
);
tableEnv.registerDataSet("item", itemdto); // 注册表信息经过上面的转化,前半部分的值已经求出,下面要求出(x1y1+x2y2)的值
将上面的原始table再次转一下,变成下面的格式
代码如下:
.map(new MapFunction<Tuple2<String,List<Tuple2<String,Float>>>, List<Tuple2<Tuple2<String, String>, Float>>>()
@Override
public List<Tuple2<Tuple2<String, String>, Float>> map(Tuple2<String,List<Tuple2<String,Float>>> value) throws Exception
List<Tuple2<String, Float>> ll= value.f1;
List<Tuple2<Tuple2<String, String>, Float>> list = new ArrayList<>();
for (int i = 0; i < ll.size(); i++)
for (int j = 0; j < ll.size(); j++)
list.add(new Tuple2<>(new Tuple2<>(ll.get(i).f0, ll.get(j).f0),
ll.get(i).f1 * ll.get(j).f1));
return list;
)
tableEnv.registerDataSet("item_relation", itemRelation); // 注册表信息下面就是将整个公式连起来,完成最后的计算。
Table similarity=tableEnv.sqlQuery("select ta.firstItem,ta.secondItem,"
+ "(sqrt(tb.score + tc.score - 2 * ta.relationScore)) as similarScore from item tb " +
"inner join item_relation ta on tb.itemId = ta.firstItem and ta.firstItem <> ta.secondItem "+
"inner join item tc on tc.itemId = ta.secondItem "
);
DataSet<ItemSimilarDTO> ds=tableEnv.toDataSet(similarity, ItemSimilarDTO.class);现在结构变成

感觉离终点不远了,上述结构依然不是我们想要的,我们希望结构更加清晰,如下格式
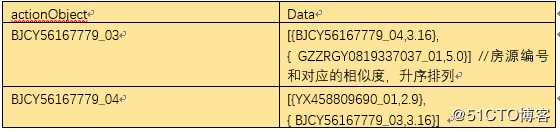
代码如下:
DataSet<RedisDataModel> redisResult= ds.map(new MapFunction<ItemSimilarDTO, Tuple2<String, Tuple2<String, Float>>> ()
@Override
public Tuple2<String, Tuple2<String, Float>> map(ItemSimilarDTO value) throws Exception
return new Tuple2<String, Tuple2<String, Float>>(value.getFirstItem(), new Tuple2<>(value.getSecondItem(), value.getSimilarScore().floatValue()));
).groupBy(0).reduceGroup(new GroupReduceFunction<Tuple2<String, Tuple2<String, Float>> , Tuple2<String, List<RoomModel>>>()
@Override
public void reduce(Iterable<Tuple2<String, Tuple2<String, Float>>> values,
Collector<Tuple2<String, List<RoomModel>>> out) throws Exception
List<RoomModel> list=new ArrayList<>();
String key=null;
for (Tuple2<String, Tuple2<String, Float>> t : values)
key=t.f0;
RoomModel rm=new RoomModel();
rm.setRoomCode(t.f1.f0);
rm.setScore(t.f1.f1);
list.add(rm);
//升序排序
Collections.sort(list,new Comparator<RoomModel>()
@Override
public int compare(RoomModel o1, RoomModel o2)
return o1.getScore().compareTo(o2.getScore());
);
out.collect(new Tuple2<>(key,list));
).map(new MapFunction<Tuple2<String, List<RoomModel>>, RedisDataModel>()
@Override
public RedisDataModel map(Tuple2<String, List<RoomModel>> value) throws Exception
RedisDataModel m=new RedisDataModel();
m.setExpire(-1);
m.setKey(JobConstants.REDIS_FLINK_ITEMCF_KEY_PREFIX+value.f0);
m.setGlobal(true);
m.setValue(JSON.toJSONString(value.f1));
return m;
);最终将这些数据存入redis中,方便查询
RedisOutputFormat redisOutput = RedisOutputFormat.buildRedisOutputFormat()
.setHostMaster(AppConfig.getProperty(JobConstants.REDIS_HOST_MASTER))
.setHostSentinel(AppConfig.getProperty(JobConstants.REDIS_HOST_SENTINELS))
.setMaxIdle(Integer.parseInt(AppConfig.getProperty(JobConstants.REDIS_MAXIDLE)))
.setMaxTotal(Integer.parseInt(AppConfig.getProperty(JobConstants.REDIS_MAXTOTAL)))
.setMaxWaitMillis(Integer.parseInt(AppConfig.getProperty(JobConstants.REDIS_MAXWAITMILLIS)))
.setTestOnBorrow(Boolean.parseBoolean(AppConfig.getProperty(JobConstants.REDIS_TESTONBORROW)))
.finish();
redisResult.output(redisOutput);
env.execute("itemcf");大功告成,其实没有想象中的那么难。当然这里只是一个demo,实际情况还要进行数据过滤,多表join优化等。
以上是关于基于flink的协同过滤的主要内容,如果未能解决你的问题,请参考以下文章