.NET轻松写博客园爬虫
Posted sdflysha
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了.NET轻松写博客园爬虫相关的知识,希望对你有一定的参考价值。
.NET轻松写博客园爬虫
爬虫,是一种按照一定的规则,自动地抓取网站的程序或者脚本。.NET写爬虫非常简单,并能轻松优化性能。今天我将分享一段简短的代码,爬出博客园前200页精华内容,然后通过微小的改动,将代码升级为多线程爬虫,让爬虫速度提升数倍;最后将对爬到了内容进行一些有趣的分析。
本文演示的代码,可以从这里下载:https://github.com/sdcb/blog-data/tree/master/2019/20190826-cnblogs-crawler-home
?我的演示代码通过LINQPad运行,可以在这里找到最新的LINQPad下载链接:https://www.linqpad.net/Download.aspx
这些代码同样可以运行在Visual Studio中。其中.Dump()方法可以在Visual Studio中搜索并安装NuGet包即可兼容:
Install-Package LINQPad爬虫的三要素
经过我“多年”的爬虫骚操作的经验,我认为爬虫无非就是:
- 下载网站数据;
- 解析/保存网站数据;
- 分析数据与下个页面之间的关系,以便继续下载下个页面数据;
下面我将通过代码演示这三点。
下载网站数据
换作以前,有WebRequest/WebClient/RestSharp之类的选择,但如今已经都被HttpClient取代了,HttpClient同时内置于.NET Framework 4.5/netstandard 1.1及以后的版本,不用安装第三方包。
代码使用也非常简单:
var client = new HttpClient();
string response = await client.DownloadStringAsync("https://www.cnblogs.com");其中response就是从博客园下载的html字符串。
解析网站数据
.NET解析html有多个包可供选择,如HtmlAgilityPack、CsQuery等。但AngleSharp由于其简单好用、功能强大,已经也成为解析html的不错之选。
AngleSharp是开源项目,Github地址是:https://github.com/AngleSharp/AngleSharp。
近期还加入了.NET Foundation(.NET基金会),官网地址是:https://anglesharp.github.io 。
使用AngleSharp解析html示例代码(在LINQPad中,按Ctrl+Shift+P快速安装NuGet包):
Install-Package AngleSharp
Install-Package Newtonsoft.Json使用代码如下:
var parser = new HtmlParser();
IHtmlDocument dom = parser.ParseDocument(@"<ul>
<li>
<a href=""cnblogs.com"">博客园</a>
<a href=""baidu.com"">百度</a>
<a href=""google.com"">谷歌</a>
</li>
<ul>");
var data = dom.QuerySelectorAll("ul li a").Select(x => new
Link = x.GetAttribute("href"),
Title = x.TextContent
).Dump();运行效果:
| Link | Title |
|---|---|
| cnblogs.com | 博客园 |
| baidu.com | 百度 |
| google.com | 谷歌 |
然后这些数据可以通过JSON序列化,保存到桌面上:
File.WriteAllText(@"C:\\Users\\sdfly\\Desktop\\cnblogs.json", JsonConvert.SerializeObject(data));在解析网页数据时,可能还需要灵活运用正则表达式,来抓取没那么直观的信息。
页面与页面之间的关系
我们找到博客园的分页器,打开F12开发者工具,用鼠标定位到分页器:
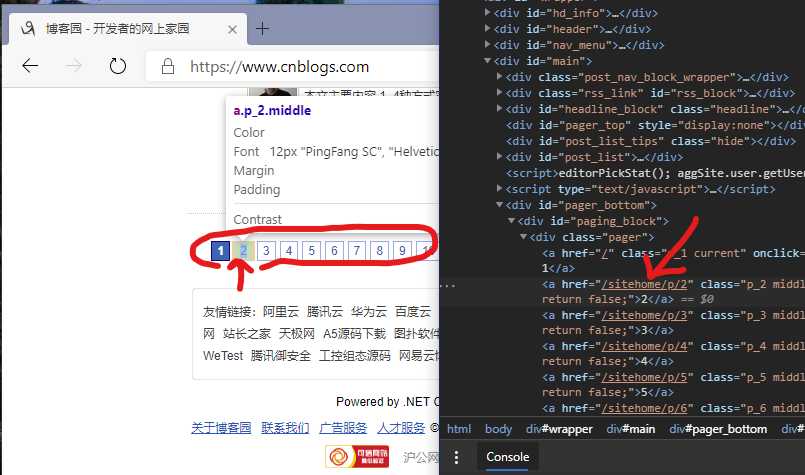
如图,注意到,每一个页面按钮,都对应了一个不同的链接地址,如第2页,对应的的链接是:/sitehome/p/2,第3页,对应的是:/sitehome/p/3。
博客园首页内容一共有200页,因此只需将在每一页拼接一个$"/sitehome/p/页面数码"即可。
代码与优化
根据上面的知识,可以轻松将博客园首页200页数据爬出来:
var http = new HttpClient();
var parser = new HtmlParser();
for (var page = 1; page <= 200; ++page)
string pageData = await http.GetStringAsync($"https://www.cnblogs.com/sitehome/p/page");
IHtmlDocument doc = await parser.ParseDocumentAsync(pageData);
doc.QuerySelectorAll(".post_item").Select(tag => new
Title = tag.QuerySelector(".titlelnk").TextContent,
Page = page,
UserName = tag.QuerySelector(".post_item_foot .lightblue").TextContent,
PublishTime = DateTime.Parse(Regex.Match(tag.QuerySelector(".post_item_foot").ChildNodes[2].TextContent, @"(\\d4\\-\\d2\\-\\d2\\s\\d2:\\d2)", RegexOptions.None).Value),
CommentCount = int.Parse(tag.QuerySelector(".post_item_foot .article_comment").TextContent.Trim()[3..^1]),
ViewCount = int.Parse(tag.QuerySelector(".post_item_foot .article_view").TextContent[3..^1]),
BriefContent = tag.QuerySelector(".post_item_summary").TextContent.Trim(),
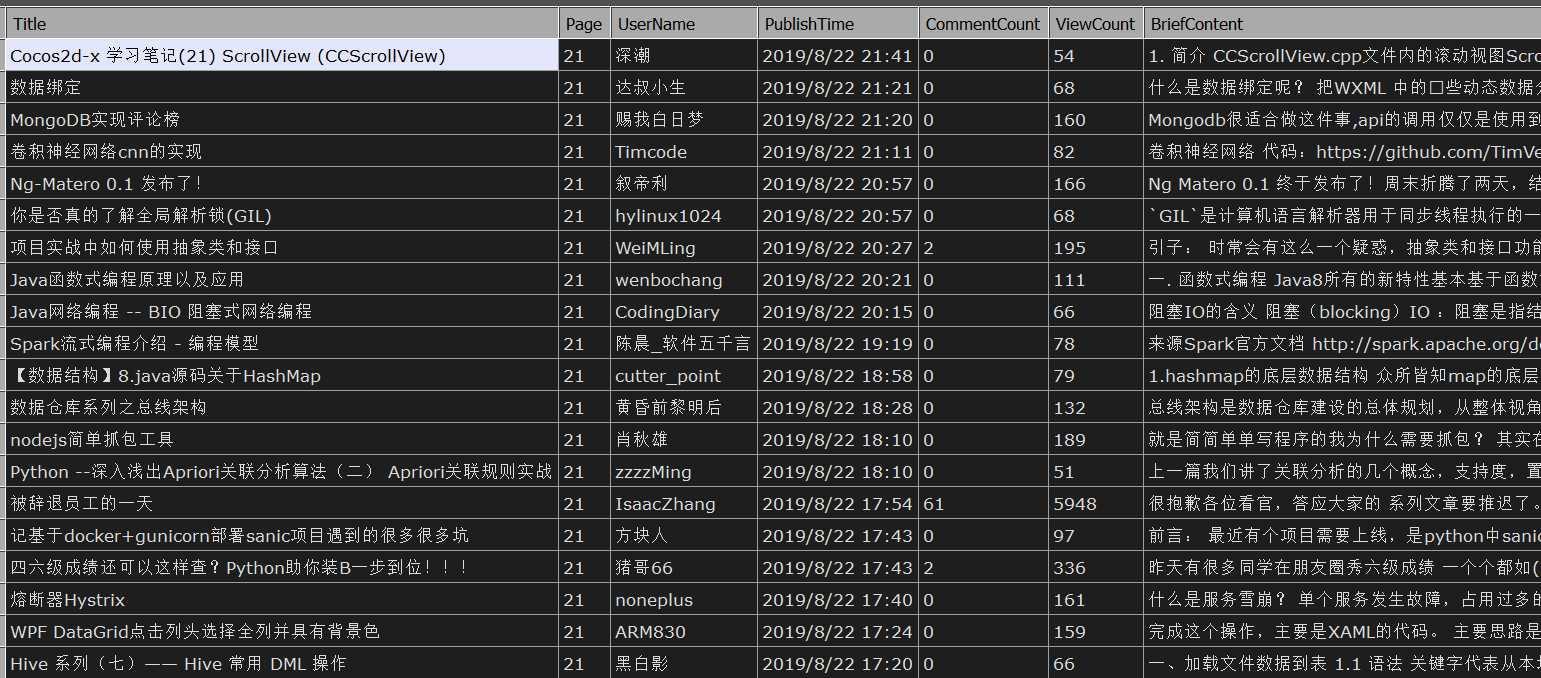
).Dump(page);
运行结果如下:
多线程优化
这个爬虫将200页数据全部爬完,根据我的网速,需要76秒,任务管理器显示如下(下载速度只有每秒1.7 Mbps)

在.NET/C#中,只需对此代码的for循环修改为LINQ,然后而加以使用Parallel LINQ,即可将代码并行化:
Enumerable.Range(1, 200) // for循环转换为LINQ
.AsParallel() // 将LINQ并行化
.AsOrdered() // 按顺序保存结果(注意并非按顺序执行)
.SelectMany(page =>
return Task.Run(async() => // 非异步代码使用async/await,需要包一层Task
string pageData = await http.GetStringAsync($"https://www.cnblogs.com/sitehome/p/page".Dump());
IHtmlDocument doc = await parser.ParseDocumentAsync(pageData);
return doc.QuerySelectorAll(".post_item").Select(tag => new
Title = tag.QuerySelector(".titlelnk").TextContent,
Page = page,
UserName = tag.QuerySelector(".post_item_foot .lightblue").TextContent,
PublishTime = DateTime.Parse(Regex.Match(tag.QuerySelector(".post_item_foot").ChildNodes[2].TextContent, @"(\\d4\\-\\d2\\-\\d2\\s\\d2:\\d2)", RegexOptions.None).Value),
CommentCount = int.Parse(tag.QuerySelector(".post_item_foot .article_comment").TextContent.Trim()[3..^1]),
ViewCount = int.Parse(tag.QuerySelector(".post_item_foot .article_view").TextContent[3..^1]),
BriefContent = tag.QuerySelector(".post_item_summary").TextContent.Trim(),
);
).GetAwaiter().GetResult(); // 等待Task执行完毕
)通过这个非常简单的优化,在我的电脑上,即可将运行时间降低为14.915秒,速度快了5倍!同时任务管理器显示网络下载流量为:

数据简单分析
现在我们得到了博客园首页博客简要数据,我将其保存到桌面的一个json文件中(大家也可以试着保存为其它格式,如数据库中)。当然少不了分析一番。使用LINQPad,可以很轻松地分析这些数据,并生成图表。
分析基础
void Main()
var data = JsonConvert.DeserializeObject<List<CnblogsItem>>(
File.ReadAllText(@"C:\\Users\\sdfly\\Desktop\\cnblogs.json"));
class CnblogsItem
public string TItle get; set;
public int Page get; set;
public string UserName get; set;
public DateTime PublishTime get; set;
public int CommentCount get; set;
public int ViewCount get; set;
public string BriefContent get; set;
我创建了一个CnblogsItem的类,用来反序列号桌面上json文件的数据。返序列化完成后,这些数据保存在data变量中。
什么时间发文章浏览量最高?
Util.Chart(data
.GroupBy(x => x.PublishTime.Hour)
.Select(x => new Hour = x.Key, ViewCount = 1.0 * x.Sum(v => v.ViewCount) )
.OrderByDescending(x => x.Hour),
x => x.Hour,
y => y.ViewCount).Dump();结果:
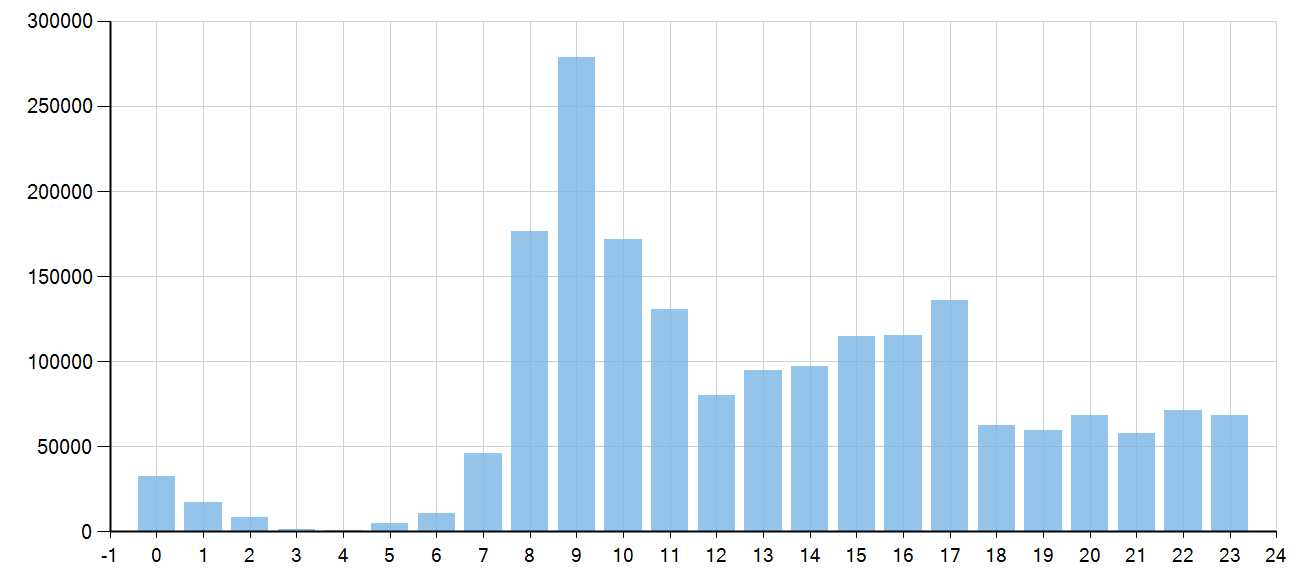
可见,每天上午9点发文章浏览量最高,凌晨3-4点发文章浏览量最低(谁会在晚上3-4点爬起来看东西呢?)
星期几发的文章多?
Util.Chart(data
.GroupBy(x => x.PublishTime.DayOfWeek)
.Select(x => new WeekDay = x.Key, ArticleCount = x.Count() )
.OrderBy(x => x.WeekDay),
x => x.WeekDay.ToString(),
y => y.ArticleCount).Dump();结果:
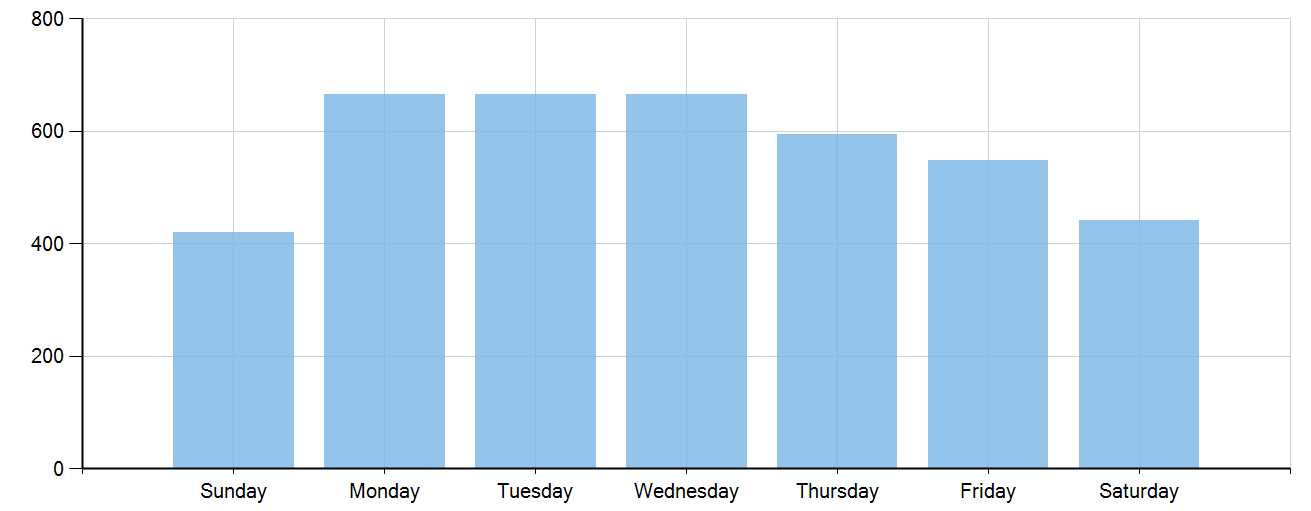
可见:星期一、二、三的文章最多,星期四、五逐渐冷淡,星期六、星期日最少。——但星期六比星期日又多一点。(是因为996造成的吗?)
哪位大佬发文最多(取前9名)?
Util.Chart(data
.GroupBy(x => x.UserName)
.Select(x => new UserName = x.Key, ArticleCount = x.Count() )
.OrderByDescending(x => x.ArticleCount)
.Take(9),
x => x.UserName,
y => y.ArticleCount).Dump();结果:
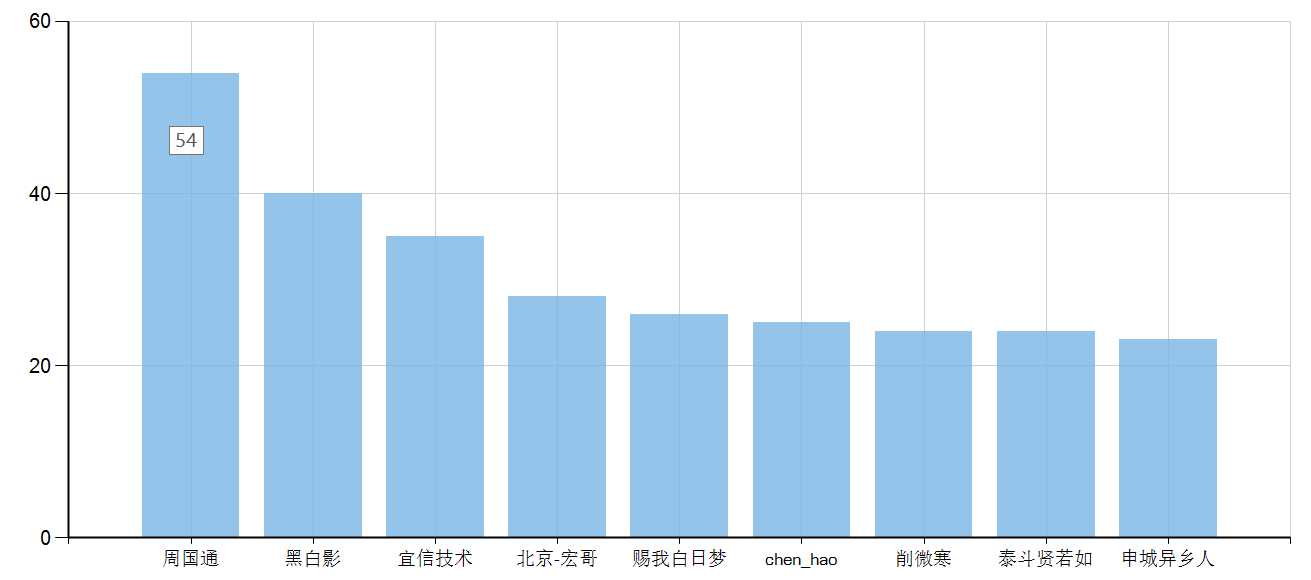
可见,大佬周国通竟然在前200页博客中,独占54篇,我点开了他的博客(https://www.cnblogs.com/tylerzhou/)看了一下,竟然都有相当的质量——绝无放水可言,深入讲了许多.NET的测试系列教程,确实是大佬!
结语
实际应用的爬虫可能不像博客园这么简单,爬虫如果深入,可以遇到很多很多非常有意思的情况。
今天谨希望通过这个简单的博客园爬虫,让大家多多享受写.NET/C#代码的乐趣??。
请关注我的微信公众号:【DotNet骚操作】,

以上是关于.NET轻松写博客园爬虫的主要内容,如果未能解决你的问题,请参考以下文章