好程序员大数据学习路线分享Hadoop阶段的高可用配置
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了好程序员大数据学习路线分享Hadoop阶段的高可用配置相关的知识,希望对你有一定的参考价值。
大数据学习路线分享Hadoop阶段的高可用配置,什么是Hadoop的HA机制Ha机制即Hadoop的高可用(7*24小时不中断服务)
正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制
hadoop-ha严格来说应该分成各个组件的HA机制——HDFS的HA、YARN的HA
HDFS的HA机制详解
HDFS 的HA主要是通过双namenode协调工作实现
双namenode协调工作的要点:
A、元数据管理方式需要改变:
内存中各自保存一份元数据
Edits日志只能有一份,只有Active状态的namenode节点可以做写操作
两个namenode都可以读取edits
共享的edits放在一个共享存储中管理(qjournal和NFS两个主流实现)
B、需要一个状态管理功能模块
实现了一个zkfailover,常驻在每一个namenode所在的节点
每一个zkfailover负责监控自己所在namenode节点,利用zk进行状态标识
当需要进行状态切换时,由zkfailover来负责切换
切换时需要防止brain split脑裂现象的发生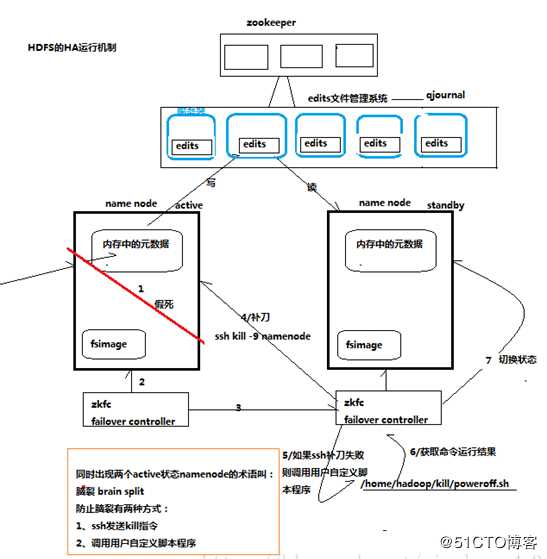
Namenode的运行原理
两台服务器上都存在一个namenode ,其中一台Namenode 处于active状态,一台处于standby状态,两台服务器数据共享,两台服务器各自存有一份元数据,但是edit数据只有一份,两台服务器只有处于active状态的namenode服务器可以对edit进行写操作,另一台服务器只能对edit进行读操作,而共享的edit放到一个共享存储中进行管理。共享存储由文件管理系统qjournal和NFS来实现。
而两台服务器的active standby状态如何管理,则需要一个管理模块:ZKFC (zookeeper failover controller) 来管理。每一个zkfc负责监控自己所在namenode节点,利用zk进行状态标识。当需要进行状态切换时,由zkfailover来负责切换
切换时需要防止brain split脑裂现象的发生。
什么是脑裂现象
脑裂现象就是两台namenode都处于active状态,产生冲突,这就是脑裂。Hadoop的高可用配置要注意解决脑裂状态。
脑裂状态如何产生
当一台active状态的namenode服务器处于假死状态,那么另一台namenode服务器的zkfc收到信息,把属于他的namenode状态改变为active状态,第一台处于假死状态的namdenode又醒过来,就会产生脑裂。
脑裂如何解决
第二台namenode的zkfc此时就会一不做二不休,把第一台处于假死状态的namenode杀掉 运用ssh kill -9 namenode ,直接杀掉第一台服务器的namenode进行补刀,如果补刀不成功的话,zkfc进入第一台服务器,直接调用用户的自定义脚本程序 /home/Hadoop/kill/poweroff.sh 杀-掉假-死的namenode。
以上是关于好程序员大数据学习路线分享Hadoop阶段的高可用配置的主要内容,如果未能解决你的问题,请参考以下文章