ConcurrentHashMap
Posted robertlionlin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ConcurrentHashMap相关的知识,希望对你有一定的参考价值。
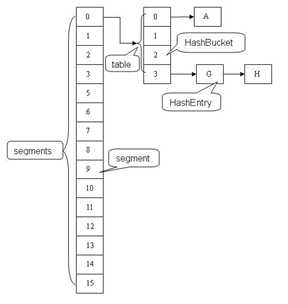
ConcurrentHashMap主要有三大结构:整个Hash表,segment(段),HashEntry(节点)。每个segment就相当于一个HashTable。
Base 1.8 抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。
(1)HashEntry类
每个HashEntry代表Hash表中的一个节点,在其定义的结构中可以看到,除了value值没有定义final,其余的都定义为final类型,我们知道Java中关键词final修饰的域成为最终域。用关键词final修饰的变量一旦赋值,就不能改变,也称为修饰的标识为常量。这就意味着我们删除或者增加一个节点的时候,就必须从头开始重新建立Hash链,因为next引用值需要改变。
(2)segment类
Segment 类继承于 ReentrantLock 类,从而使得 Segment 对象能充当锁的角色。每个 Segment 对象用来守护其(成员对象 table 中)包含的若干个桶。
table 是一个由 HashEntry 对象组成的数组。table 数组的每一个数组成员就是散列映射表的一个桶。
count 变量是一个计数器,它表示每个 Segment 对象管理的 table 数组(若干个 HashEntry 组成的链表)包含的 HashEntry 对象的个数。每一个 Segment 对象都有一个 count 对象来表示本 Segment 中包含的 HashEntry 对象的总数。注意,之所以在每个 Segment 对象中包含一个计数器,而不是在 ConcurrentHashMap 中使用全局的计数器,是为了避免出现“热点域”而影响 ConcurrentHashMap 的并发性。
默认的情况下,每个ConcurrentHashMap 类会创建16个并发的segment
用分离锁实现多个线程间的并发写操作
(1)Put
这里的加锁是针对具体的segment,而不是对整个ConcurrentHashMap。Put方法从源码上可以看出是从链表的头部插入新的数据的。
1.8:
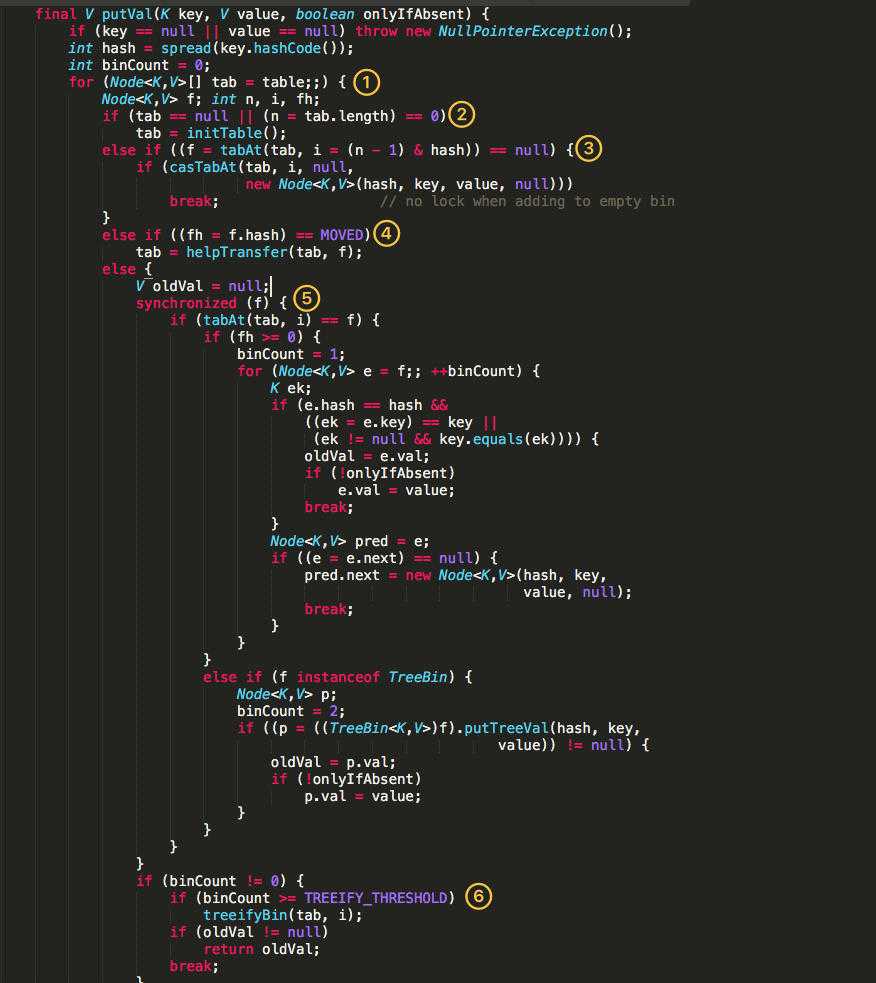
根据 key 计算出 hashcode 。
判断是否需要进行初始化。
f 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
自旋锁:https://blog.csdn.net/qq_34337272/article/details/81252853 自旋锁(spinlock):是指当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁是否能够被成功获取,直到获取到锁才会退出循环。
如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。
如果都不满足,则利用 synchronized 锁写入数据。
如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。
(2)Get
ConcurrentHashMap中的读方法不需要加锁,所有的修改操作在进行结构修改时都会在最后一步写count 变量,通过这种机制保证get操作能够得到几乎最新的结构更新。
1.8 :根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
如果是红黑树那就按照树的方式获取值。
就不满足那就按照链表的方式遍历获取值。
(3)Remove
整个操作是在持有段锁的情况下执行的,空白行之前的行主要是定位到要删除的节点e。接下来,如果不存在这个节点就直接返回null,否则就要将e前面的结点复制一遍,尾结点指向e的下一个结点。e后面的结点不需要复制,它们可以重用。
中间那个for循环是做什么用的呢?从代码来看,就是将定位之后的所有entry克隆并拼回前面去,但有必要吗?每次删除一个元素就要将那之前的元素克隆一遍?这点其实是由entry的不变性来决定的,仔细观察entry定义,发现除了value,其他所有属性都是用final来修饰的,这意味着在第一次设置了next域之后便不能再改变它,取而代之的是将它之前的节点全都克隆一次。至于entry为什么要设置为不变性,这跟不变性的访问不需要同步从而节省时间有关。
以上是关于ConcurrentHashMap的主要内容,如果未能解决你的问题,请参考以下文章