树链剖分 入门
Posted asika3912333
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了树链剖分 入门相关的知识,希望对你有一定的参考价值。
什么是树链剖分?
树链剖分说白了就是将树的节点按照某种顺序编号,使其在特殊的链上编号连续(类似区间),方便用数据结构维护。
如何树链剖分?
树链剖分一般分为重链剖分和长链剖分,这里只介绍重链剖分(我也只会重链剖分)。
重链剖分中有几个概念:
- 重儿子:一个节点的所有子节点中,以某个子节点为根的子树中节点数量最多的称为重儿子(如果最多的数量相同随便取一个)。
- 轻儿子:一个节点的所有子节点中,不是重儿子的节点就是轻儿子(这不是废话吗)。
- 重边:父节点与重儿子所连成的边。
- 轻边:父节点与轻儿子所连成的边。
- 重链:重边所连成的链。
- 轻链:轻边所连城的链。
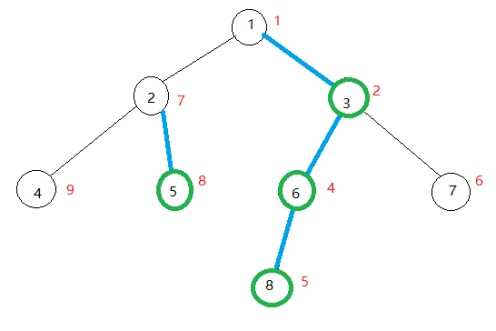
如图所示,蓝色的边为重边,绿色的节点为重儿子。
树链剖分的第一步就是一遍dfs找出所有节点的重儿子,并处理出深度与父子关系(以后有用)。
代码如下:
void dfs(int x) size[x]=1,d[x]=d[fa[x]];//size表示节点数量,d表示深度 for(int i=head[x];i;i=nxt[i]) int y=ver[i]; if(y==fa[x]) continue;//fa表父节点 dfs(y); size[x]+=size[y]; if(size[y]>size[son[x]]) son[x]=y;//son表示重儿子
树链剖分的第二步便是按照重儿子先遍历,轻儿子后遍历的次序再dfs一遍,给节点按照dfs序编号,还是如上面那张图所示,红色数字的代表重新编号后的编号。并处理出每一条重链的首端,轻儿子的首端为它自己。
代码如下:
void dfs(int x,top1)//top1代表重链首端 top[x]=top1;//首端 id[x]=++cnt;//重新编号 if(!son[x]) continue; dfs(son[x],top1);//重儿子所在重链的首端和该节点一样 for(int i=head[x];i;i=nxt[i]) int y=ver[i]; if(y==fa[x] || y==son[x]) continue; dfs(y,y);//轻儿子所在首端为它自己
处理完这两个dfs之后,我们可以发现,重链上的编号都是连续的!,这意味着我们可以像维护区间一样用数据结构(线段树、树状数组)维护每一条重链。我们还可以发现每个节点的儿子的子树编号也是连续的,用线段树描述的话区间[id[x],id[x]+size[x]-1]覆盖了以节点x为根的子树中所有节点。
当我们想要在树链上维护树上两个节点x,y之间的路径的数据时(列如节点权值和)或者求lca时,如果x与y所在重链的首端不同的话,一般都是将节点x与节点y同时向其所在重链的首端的父节点往上跳,因为重链上节点编号是连续的,所以我们可以在跳的过程中对每一条重链用数据结构进行维护。当重链首端相同的时候也就意味着它们在同一条重链,这时候维护节点x~y(或y~x,看节点深度)之间的信息就好了。
下面以“将节点x到节点y的最短路径上的所有节点的权值都加上a”为例给出代码。
int add(int x,int y,int a) while(top[x]!=top[y])//重链所在首端不同的时候 if(d[top[x]]<d[top[y]]) swap(x,y);//比较深度 addtree(1,id[top[x]],id[x],a);//线段树维护链,维护重链首端top[x]到节点x之间的节点权值 x=fa[top[x]];//往上跳至首端的父节点
//此时首端相同 if(d[x]>d[y]) swap(x,y);//看深度 addtree(1,id[x],id[y],a);//维护此时x到y这条重链上的节点权值
两道例题:
[SDOI2011]染色 题解
[NO12015]软件包管理器 题解
对树链剖分的时间复杂度分析
树链剖分的两个性质:
- 若(x,y)是一条轻边,那么 $size[y]<\\frac12 size[x]$
- 从根结点到任意结点的路所经过的轻重链的个数必定都小于logn
第一个性质不难理解,可以用反证法。第二个性质因为如果某一个节点x所在的是重链,那么它可以直接跳到重链链头,所以我们考虑最坏情况,也就是从它到根节点的路上,它都走的是轻边,再考虑对树上每一个节点都只有两个size数量相同的子节点(因为如果不相同那更快),此时就和一棵二叉树差不多,走到根节点所经过节点数差不多是 $log_2n$(我是这么理解的,出了错我可是不负泽任的233)。
以上是关于树链剖分 入门的主要内容,如果未能解决你的问题,请参考以下文章