GUID做主键真的合适吗
Posted meteorseed
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GUID做主键真的合适吗相关的知识,希望对你有一定的参考价值。
在一个分布式环境中,我们习惯使用GUID做主键,来保证全局唯一,然后,GUID做主键真的合适吗?
其实GUID做主键本身没有问题,微软的很多项目自带DB都是使用GUID做主键的,显然,这样做是没有问题的。然而,SQL Server默认会将主键设置为聚集索引,使用GUID做聚集索引就有问题了。很多时候程序员容易接受SQL Server这一默认设置,但无序GUID做聚集索引显然是低效的。
那么,我们在项目中如何避免这一问题呢?
主要的思路还是两方面——方案一,选择合适的列作为聚集索引;方案二,使用有序的主键。
1 方案一,选择合适的列做聚集索引
选择原则很简单——字段值尽量唯一,字段占用字节尽量小,字段值很少修改,字段多用于查询范围数据或排序的数据。
之所以是根据以上原则选择,主要还是基于B+树数据索引问题,这部分内容都比较基础,这里就不举例验证了,以上原则还是比较公认的,即便读者不太理解其中原理,也请记住这一选择规则。
常见的备选项——自增列(Id)和时间列(CreateTime)。
聚集索引的最大用处就是帮助范围查询快速定位,从而减小数据库IO的消耗来提升查询效率。对于范围查询我们更多的应用在自增列和时间列上,因为这两列本身反应了数据的创建顺序,符合多数范围查询的场景需要。
大部分时候,我们仍然可以使用GUID做主键,只需要重新设置聚集索引就行。
2 方案二,有序的主键
对于一个分布式环境,保证唯一和有序性,实际上有多种方法,各有利弊。
2.1 分布式数据库
对于分布式数据库,简单使用自增主键即可,比如Tidb。
TiDB 中,自增列只保证自增且唯一,并不保证连续分配。TiDB 目前采用批量分配 ID 的方式,所以如果在多台 TiDB 上同时插入数据,分配的自增 ID 会不连续。TiDB 实现自增 ID 的原理是每个 tidb-server 实例缓存一段 ID 值用于分配(目前会缓存 30000 个 ID),用完这段值再去取下一段。
优点:简单好用
缺点:不能设置ID,需要使用数据库的;ID不保证连续分配,也无法根据ID来判断数据创建的先后;负载不均匀,有数据热点问题
2.2 基于Redis等中间件的
根据数据库分片方式不同,又有两种情形。
方式一,取模分片
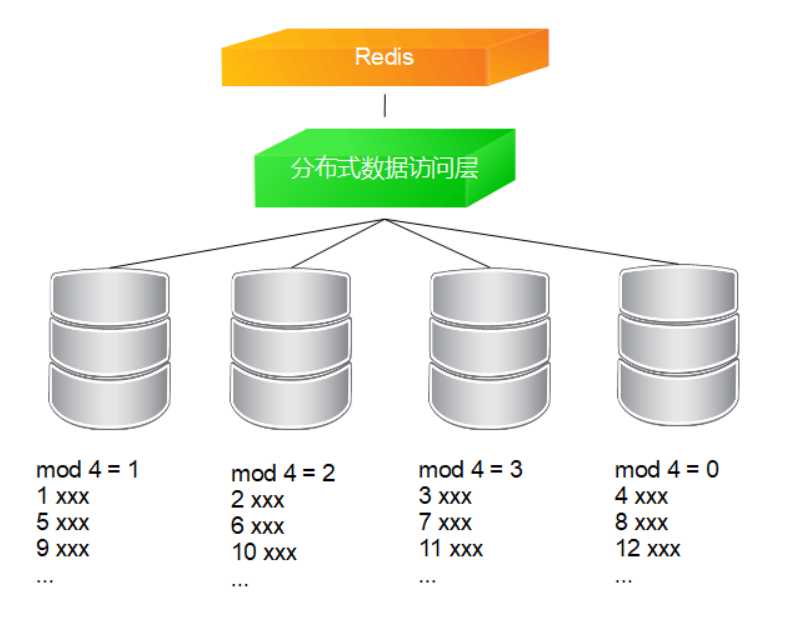

思路:Redis初始化当前最大ID值,之后进行自增,分布式数据访问层根据取模进行路由
优点:数据库负载比较均匀
缺点:需要尽量保证Redis和数据库的一致性;Redis不稳定会影响系统,可能会出现重复ID在插入数据库,主键重复会抛出异常;在增加数据库后,需要大批量移动数据,且需要成倍增加DB
方式二,按范围分片
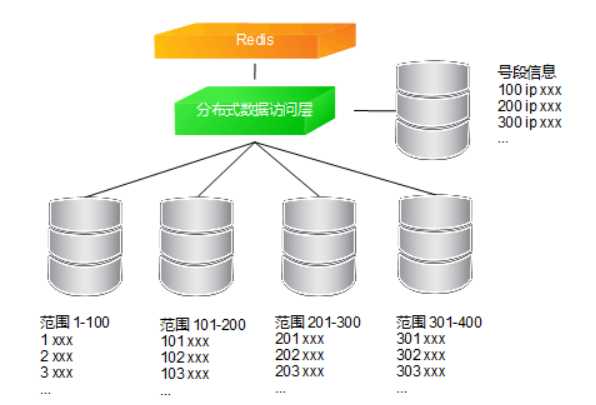

思路:每台服务器负责一个号段,不够用了就增加服务器,Redis初始化当前最大ID值,之后进行自增,分布式数据访问层根据号段进行路由
优点:增加数据库可以不迁移数据,可以一个一个的增加数据库
缺点:需要尽量保证Redis和数据库的一致性;Redis不稳定会影响系统,可能会出现重复ID在插入,主键重复会抛出异常;数据分布严重不均匀,严重的热点问题
2.3 基于算法实现
这里介绍下Twitter的Snowflake算法——snowflake,它把时间戳,工作机器id,序列号组合在一起,以保证在分布式系统中唯一性和自增性。
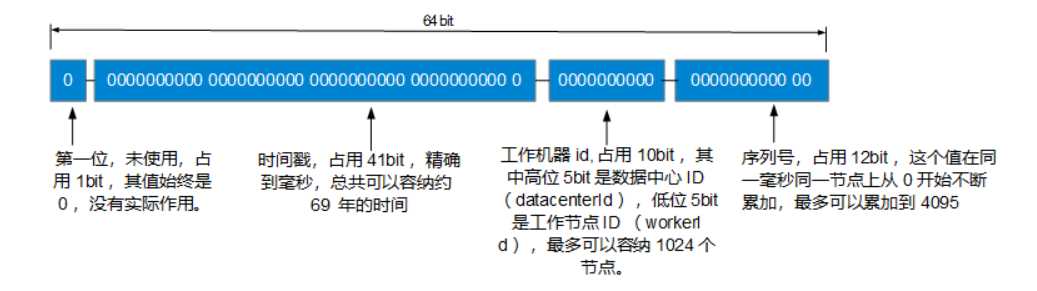

snowflake生成的ID整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞,在同一毫秒内最多可以生成 1024 X 4096 = 4194304个全局唯一ID。
优点:不依赖数据库,完全内存操作速度快
缺点:不同服务器需要保证系统时钟一致
snowflake的C#版本的简单实现:
public class SnowflakeIdWorker /// <summary> /// 开始时间截 /// 1288834974657 是(Thu, 04 Nov 2010 01:42:54 GMT) 这一时刻到1970-01-01 00:00:00时刻所经过的毫秒数。 /// 当前时刻减去1288834974657 的值刚好在2^41 里,因此占41位。 /// 所以这个数是为了让时间戳占41位才特地算出来的。 /// </summary> public const long Twepoch = 1288834974657L; /// <summary> /// 工作节点Id占用5位 /// </summary> const int WorkerIdBits = 5; /// <summary> /// 数据中心Id占用5位 /// </summary> const int DatacenterIdBits = 5; /// <summary> /// 序列号占用12位 /// </summary> const int SequenceBits = 12; /// <summary> /// 支持的最大机器Id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) /// </summary> const long MaxWorkerId = -1L ^ (-1L << WorkerIdBits); /// <summary> /// 支持的最大数据中心Id,结果是31 /// </summary> const long MaxDatacenterId = -1L ^ (-1L << DatacenterIdBits); /// <summary> /// 机器ID向左移12位 /// </summary> private const int WorkerIdShift = SequenceBits; /// <summary> /// 数据标识id向左移17位(12+5) /// </summary> private const int DatacenterIdShift = SequenceBits + WorkerIdBits; /// <summary> /// 时间截向左移22位(5+5+12) /// </summary> public const int TimestampLeftShift = SequenceBits + WorkerIdBits + DatacenterIdBits; /// <summary> /// 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) /// </summary> private const long SequenceMask = -1L ^ (-1L << SequenceBits); /// <summary> /// 毫秒内序列(0~4095) /// </summary> private long _sequence = 0L; /// <summary> /// 上次生成Id的时间截 /// </summary> private long _lastTimestamp = -1L; /// <summary> /// 工作节点Id /// </summary> public long WorkerId get; protected set; /// <summary> /// 数据中心Id /// </summary> public long DatacenterId get; protected set; /// <summary> /// 构造器 /// </summary> /// <param name="workerId">工作ID (0~31)</param> /// <param name="datacenterId">数据中心ID (0~31)</param> public SnowflakeIdWorker(long workerId, long datacenterId) WorkerId = workerId; DatacenterId = datacenterId; if (workerId > MaxWorkerId || workerId < 0) throw new ArgumentException(String.Format("worker Id can‘t be greater than 0 or less than 0", MaxWorkerId)); if (datacenterId > MaxDatacenterId || datacenterId < 0) throw new ArgumentException(String.Format("datacenter Id can‘t be greater than 0 or less than 0", MaxDatacenterId)); private static readonly object _lockObj = new Object(); /// <summary> /// 获得下一个ID (该方法是线程安全的) /// </summary> /// <returns></returns> public virtual long NextId() lock (_lockObj) //获取当前时间戳 var timestamp = TimeGen(); //如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常 if (timestamp < _lastTimestamp) throw new InvalidOperationException(String.Format( "Clock moved backwards. Refusing to generate id for 0 milliseconds", _lastTimestamp - timestamp)); //如果是同一时间生成的,则进行毫秒内序列 if (_lastTimestamp == timestamp) _sequence = (_sequence + 1) & SequenceMask; //毫秒内序列溢出 if (_sequence == 0) //阻塞到下一个毫秒,获得新的时间戳 timestamp = TilNextMillis(_lastTimestamp); //时间戳改变,毫秒内序列重置 else _sequence = 0; //上次生成ID的时间截 _lastTimestamp = timestamp; //移位并通过或运算拼到一起组成64位的ID return ((timestamp - Twepoch) << TimestampLeftShift) | (DatacenterId << DatacenterIdShift) | (WorkerId << WorkerIdShift) | _sequence; /// <summary> /// 生成当前时间戳 /// </summary> /// <returns>毫秒</returns> private static long GetTimestamp() return (long)(DateTime.UtcNow - new DateTime(1970, 1, 1, 0, 0, 0, DateTimeKind.Utc)).TotalMilliseconds; /// <summary> /// 生成当前时间戳 /// </summary> /// <returns>毫秒</returns> protected virtual long TimeGen() return GetTimestamp(); /// <summary> /// 阻塞到下一个毫秒,直到获得新的时间戳 /// </summary> /// <param name="lastTimestamp">上次生成Id的时间截</param> /// <returns></returns> protected virtual long TilNextMillis(long lastTimestamp) var timestamp = TimeGen(); while (timestamp <= lastTimestamp) timestamp = TimeGen(); return timestamp;
测试:
[TestClass] public class SnowflakeTest [TestMethod] public void MainTest() SnowflakeIdWorker idWorker = new SnowflakeIdWorker(0, 0); for (int i = 0; i < 1000; i++) Trace.WriteLine(string.Format("0-1", DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss:ffffff"), idWorker.NextId()));
结果:

总之,GUID能满足大部分需要,但如果想要我们的程序精益求精,也可以考虑使用本文提到的方法,感谢阅读。
以上是关于GUID做主键真的合适吗的主要内容,如果未能解决你的问题,请参考以下文章