使用 dataset 管理数据(官网)
Posted huchong-bk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用 dataset 管理数据(官网)相关的知识,希望对你有一定的参考价值。
ECharts 4 开始支持了 dataset 组件用于单独的数据集声明,从而数据可以单独管理,被多个组件复用,并且可以基于数据指定数据到视觉的映射。这在不少场景下能带来使用上的方便。
ECharts 4 以前,数据只能声明在各个“系列(series)”中,例如:
option:
xAxis:
type: ‘category‘,
data: [‘Matcha Latte‘, ‘Milk Tea‘, ‘Cheese Cocoa‘, ‘Walnut Brownie‘]
,
yAxis:
series: [
type: ‘bar‘,
name: ‘2015‘,
data: [89.3, 92.1, 94.4, 85.4]
,
type: ‘bar‘,
name: ‘2016‘,
data: [95.8, 89.4, 91.2, 76.9]
,
type: ‘bar‘,
name: ‘2017‘,
data: [97.7, 83.1, 92.5, 78.1]
]
这种方式的优点是,直观易理解,以及适于对一些特殊图表类型进行一定的数据类型定制。但是缺点是,为匹配这种数据输入形式,常需要有数据处理的过程,把数据分割设置到各个系列(和类目轴)中。此外,不利于多个系列共享一份数据,也不利于基于原始数据进行图表类型、系列的映射安排。
于是,ECharts 4 提供了 数据集(dataset)组件来单独声明数据,它带来了这些效果:
- 能够贴近这样的数据可视化常见思维方式:基于数据(
dataset组件来提供数据),指定数据到视觉的映射(由 encode 属性来指定映射),形成图表。 - 数据和其他配置可以被分离开来,使用者相对便于进行单独管理,也省去了一些数据处理的步骤。
- 数据可以被多个系列或者组件复用,对于大数据,不必为每个系列创建一份。
- 支持更多的数据的常用格式,例如二维数组、对象数组等,一定程度上避免使用者为了数据格式而进行转换。
入门例子
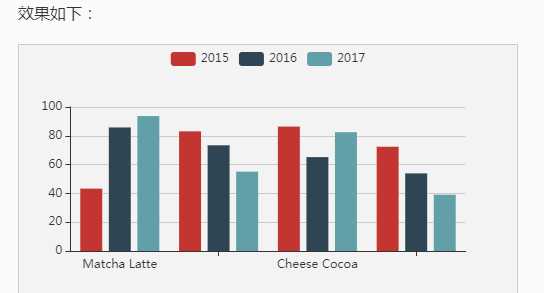
下面是一个最简单的 dataset 的例子:
option =
legend: ,
tooltip: ,
dataset:
// 提供一份数据。
source: [
[‘product‘, ‘2015‘, ‘2016‘, ‘2017‘],
[‘Matcha Latte‘, 43.3, 85.8, 93.7],
[‘Milk Tea‘, 83.1, 73.4, 55.1],
[‘Cheese Cocoa‘, 86.4, 65.2, 82.5],
[‘Walnut Brownie‘, 72.4, 53.9, 39.1]
]
,
// 声明一个 X 轴,类目轴(category)。默认情况下,类目轴对应到 dataset 第一列。
xAxis: type: ‘category‘,
// 声明一个 Y 轴,数值轴。
yAxis: ,
// 声明多个 bar 系列,默认情况下,每个系列会自动对应到 dataset 的每一列。
series: [
type: ‘bar‘,
type: ‘bar‘,
type: ‘bar‘
]
或者也可以使用常见的对象数组的格式:
option = legend: , tooltip: , dataset: // 这里指定了维度名的顺序,从而可以利用默认的维度到坐标轴的映射。 // 如果不指定 dimensions,也可以通过指定 series.encode 完成映射,参见后文。 dimensions: [‘product‘, ‘2015‘, ‘2016‘, ‘2017‘], source: [ product: ‘Matcha Latte‘, ‘2015‘: 43.3, ‘2016‘: 85.8, ‘2017‘: 93.7, product: ‘Milk Tea‘, ‘2015‘: 83.1, ‘2016‘: 73.4, ‘2017‘: 55.1, product: ‘Cheese Cocoa‘, ‘2015‘: 86.4, ‘2016‘: 65.2, ‘2017‘: 82.5, product: ‘Walnut Brownie‘, ‘2015‘: 72.4, ‘2016‘: 53.9, ‘2017‘: 39.1 ] , xAxis: type: ‘category‘, yAxis: , series: [ type: ‘bar‘, type: ‘bar‘, type: ‘bar‘ ] ;
数据到图形的映射
本篇里,我们制作数据可视化图表的逻辑是这样的:基于数据,在配置项中指定如何映射到图形。
- 指定 dataset 的列(column)还是行(row)映射为图形系列(series)。这件事可以使用 series.seriesLayoutBy 属性来配置。默认是按照列(column)来映射。
- 指定维度映射的规则:如何从 dataset 的维度(一个“维度”的意思是一行/列)映射到坐标轴(如 X、Y 轴)、提示框(tooltip)、标签(label)、图形元素大小颜色等(visualMap)。这件事可以使用 series.encode 属性,以及 visualMap 组件(如果有需要映射颜色大小等视觉维度的话)来配置。上面的例子中,没有给出这种映射配置,那么 ECharts 就按最常见的理解进行默认映射:X 坐标轴声明为类目轴,默认情况下会自动对应到 dataset.source 中的第一列;三个柱图系列,一一对应到 dataset.source 中后面每一列。
下面详细解释。
按行还是按列做映射
有了数据表之后,使用者可以灵活得配置:数据如何对应到轴和图形系列。
用户可以使用 seriesLayoutBy 配置项,改变图表对于行列的理解。seriesLayoutBy 可取值:
- ‘column‘: 默认值。系列被安放到
dataset的列上面。 - ‘row‘: 系列被安放到
dataset的行上面。
看这个例子:
option =
legend: ,
tooltip: ,
dataset:
source: [
[‘product‘, ‘2012‘, ‘2013‘, ‘2014‘, ‘2015‘],
[‘Matcha Latte‘, 41.1, 30.4, 65.1, 53.3],
[‘Milk Tea‘, 86.5, 92.1, 85.7, 83.1],
[‘Cheese Cocoa‘, 24.1, 67.2, 79.5, 86.4]
]
,
xAxis: [
type: ‘category‘, gridIndex: 0,
type: ‘category‘, gridIndex: 1
],
yAxis: [
gridIndex: 0,
gridIndex: 1
],
grid: [
bottom: ‘55%‘,
top: ‘55%‘
],
series: [
// 这几个系列会在第一个直角坐标系中,每个系列对应到 dataset 的每一行。
type: ‘bar‘, seriesLayoutBy: ‘row‘,
type: ‘bar‘, seriesLayoutBy: ‘row‘,
type: ‘bar‘, seriesLayoutBy: ‘row‘,
// 这几个系列会在第二个直角坐标系中,每个系列对应到 dataset 的每一列。
type: ‘bar‘, xAxisIndex: 1, yAxisIndex: 1,
type: ‘bar‘, xAxisIndex: 1, yAxisIndex: 1,
type: ‘bar‘, xAxisIndex: 1