软件工程学习进度第八周暨暑期学习进度之第八周汇总
Posted zdm-code
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了软件工程学习进度第八周暨暑期学习进度之第八周汇总相关的知识,希望对你有一定的参考价值。
本周的主要工作是win10+TensorFlow环境下的FCN全卷积神经网络的实现
FCN对图像进行像素级的分类,从而解决了语义级别的图像分割问题。与经典的CNN在卷积层使用全连接层得到固定长度的特征向量进行分类不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷基层的特征图(feature map)进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每一个像素都产生一个预测,同时保留了原始输入图像中的空间信息,最后奇偶在上采样的特征图进行像素的分类。它与卷积神经网络(CNN)的本质区别就是将卷积神经网络的全连层换成卷积层。
本来是打算复现FCN官方代码,后来发现官方使用的是Ubuntu+caffe,本机VMware未装Ubuntu系统所以改写FCN官方代码,并使用win10+TensorFlow实现
在这里使用的是VGG-19的模型和数据集训练
模型下载地址:
http://www.vlfeat.org/matconvnet/models/beta16/imagenet-vgg-verydeep-19.mat
数据集下载地址:
http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip
文件结构:
训练效果图:
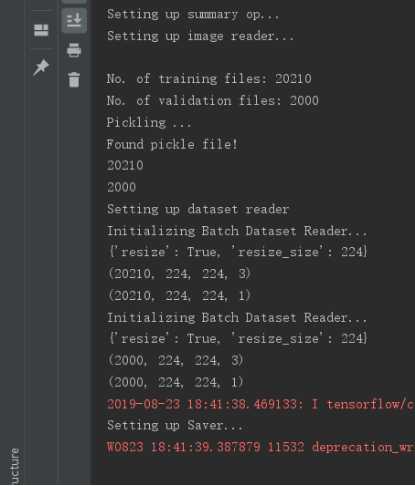
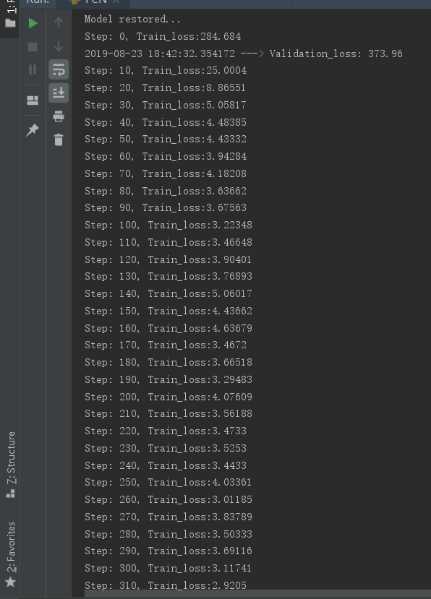
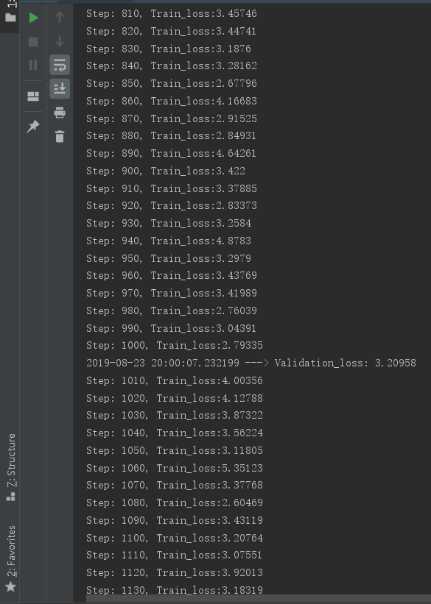
这里看到1000次训练结果loss较低,后续结果大多在3.0左右浮动,选用此次结果得到的模型
测试结果:
由于batch_size设置为2,所以测试图片为两张
结果在logs文件夹显示出来
原图:

语义分割后:

结果不是特别好,应该是学习率大小不适合导致loss值降不下来
代码如下:
FCN.py
1 from __future__ import print_function 2 import tensorflow as tf 3 import numpy as np 4 5 import TensorflowUtils as utils 6 import read_MITSceneParsingData as scene_parsing 7 import datetime 8 import BatchDatsetReader as dataset 9 from six.moves import xrange 10 11 FLAGS = tf.flags.FLAGS 12 #batch大小 13 tf.flags.DEFINE_integer("batch_size", "2", "batch size for training") 14 #存放存放数据集的路径,需要提前下载 15 tf.flags.DEFINE_string("logs_dir", "logs/", "path to logs directory") 16 tf.flags.DEFINE_string("data_dir", "Data_zoo/MIT_SceneParsing/ADEChallengeData2016/", "path to dataset") 17 # 学习率 18 tf.flags.DEFINE_float("learning_rate", "1e-4", "Learning rate for Adam Optimizer") 19 # VGG网络参数文件,需要提前下载 20 tf.flags.DEFINE_string("model_dir", "Model_zoo/", "Path to vgg model mat") 21 tf.flags.DEFINE_bool(‘debug‘, "False", "Debug mode: True/ False") 22 tf.flags.DEFINE_string(‘mode‘, "visualize", "Mode train/ test/ visualize") 23 MODEL_URL = ‘http://www.vlfeat.org/matconvnet/models/beta16/imagenet-vgg-verydeep-19.mat‘ 24 MAX_ITERATION = int(1e5 + 1) 25 # 最大迭代次数 26 NUM_OF_CLASSESS = 151 27 # 类的个数 28 IMAGE_SIZE = 224 29 # 图像尺寸 30 # vggnet函数 31 # 根据载入的权重建立原始的 VGGNet 的网络 32 def vgg_net(weights, image): 33 layers = ( ‘conv1_1‘, ‘relu1_1‘, ‘conv1_2‘, ‘relu1_2‘, ‘pool1‘, 34 ‘conv2_1‘, ‘relu2_1‘, ‘conv2_2‘, ‘relu2_2‘, ‘pool2‘, 35 ‘conv3_1‘, ‘relu3_1‘, ‘conv3_2‘, ‘relu3_2‘, ‘conv3_3‘, 36 ‘relu3_3‘, ‘conv3_4‘, ‘relu3_4‘, ‘pool3‘, 37 ‘conv4_1‘, ‘relu4_1‘, ‘conv4_2‘, ‘relu4_2‘, ‘conv4_3‘, 38 ‘relu4_3‘, ‘conv4_4‘, ‘relu4_4‘, ‘pool4‘, 39 ‘conv5_1‘, ‘relu5_1‘, ‘conv5_2‘, ‘relu5_2‘, ‘conv5_3‘, 40 ‘relu5_3‘, ‘conv5_4‘, ‘relu5_4‘ 41 ) 42 net = 43 current = image 44 for i, name in enumerate(layers): 45 kind = name[:4] 46 if kind == ‘conv‘: 47 kernels, bias = weights[i][0][0][0][0] 48 # matconvnet: weights are [width, height, in_channels, out_channels] 49 # tensorflow: weights are [height, width, in_channels, out_channels] 50 kernels = utils.get_variable(np.transpose(kernels, (1, 0, 2, 3)), name=name + "_w") 51 bias = utils.get_variable(bias.reshape(-1), name=name + "_b") 52 current = utils.conv2d_basic(current, kernels, bias) 53 elif kind == ‘relu‘: 54 current = tf.nn.relu(current, name=name) 55 if FLAGS.debug: 56 utils.add_activation_summary(current) 57 elif kind == ‘pool‘: 58 current = utils.avg_pool_2x2(current) 59 net[name] = current 60 return net 61 # inference函数,FCN的网络结构定义,网络中用到的参数是迁移VGG训练好的参数 62 def inference(image, keep_prob): 63 #输入图像和dropout值 64 """ 65 Semantic segmentation network definition 66 :param image: input image. Should have values in range 0-255 67 :param keep_prob: 68 :return: 69 """ 70 # 加载模型数据,获得标准化均值 71 print("setting up vgg initialized conv layers ...") 72 model_data = utils.get_model_data(FLAGS.model_dir, MODEL_URL) 73 mean = model_data[‘normalization‘][0][0][0] 74 # 通过字典获取mean值,vgg模型参数里有normaliza这个字典,三个0用来去虚维找到mean 75 mean_pixel = np.mean(mean, axis=(0, 1)) 76 weights = np.squeeze(model_data[‘layers‘]) 77 # 从数组的形状中删除单维度条目,获得vgg权重 78 # 图像预处理 79 processed_image = utils.process_image(image, mean_pixel) 80 # 图像减平均值实现标准化 81 print("预处理后的图像:", np.shape(processed_image)) 82 with tf.variable_scope("inference"): 83 # 建立原始的VGGNet-19网络 84 print("开始建立VGG网络:") 85 image_net = vgg_net(weights, processed_image) 86 # 在VGGNet-19之后添加 一个池化层和三个卷积层 87 conv_final_layer = image_net["conv5_3"] 88 print("VGG处理后的图像:", np.shape(conv_final_layer)) 89 pool5 = utils.max_pool_2x2(conv_final_layer) 90 W6 = utils.weight_variable([7, 7, 512, 4096], name="W6") 91 b6 = utils.bias_variable([4096], name="b6") 92 conv6 = utils.conv2d_basic(pool5, W6, b6) 93 relu6 = tf.nn.relu(conv6, name="relu6") 94 if FLAGS.debug: 95 utils.add_activation_summary(relu6) 96 relu_dropout6 = tf.nn.dropout(relu6, keep_prob=keep_prob) 97 W7 = utils.weight_variable([1, 1, 4096, 4096], name="W7") 98 b7 = utils.bias_variable([4096], name="b7") 99 conv7 = utils.conv2d_basic(relu_dropout6, W7, b7) 100 relu7 = tf.nn.relu(conv7, name="relu7") 101 if FLAGS.debug: 102 utils.add_activation_summary(relu7) 103 relu_dropout7 = tf.nn.dropout(relu7, keep_prob=keep_prob) 104 W8 = utils.weight_variable([1, 1, 4096, NUM_OF_CLASSESS], name="W8") 105 b8 = utils.bias_variable([NUM_OF_CLASSESS], name="b8") 106 conv8 = utils.conv2d_basic(relu_dropout7, W8, b8) 107 # 第8层卷积层 分类2类 1*1*2 108 # annotation_pred1 = tf.argmax(conv8, dimension=3, name="prediction1") 109 # now to upscale to actual image size 110 # 对卷积后的结果进行反卷积操作 111 deconv_shape1 = image_net["pool4"].get_shape() 112 # 将pool4 即1/16结果尺寸拿出来 做融合 [b,h,w,c] 113 # 扩大两倍 所以stride = 2 kernel_size = 4 114 W_t1 = utils.weight_variable([4, 4, deconv_shape1[3].value, NUM_OF_CLASSESS], name="W_t1") 115 b_t1 = utils.bias_variable([deconv_shape1[3].value], name="b_t1") 116 conv_t1 = utils.conv2d_transpose_strided(conv8, W_t1, b_t1, output_shape=tf.shape(image_net["pool4"])) 117 fuse_1 = tf.add(conv_t1, image_net["pool4"], name="fuse_1") # 将pool4和conv_t1拼接,逐像素相加 118 119 deconv_shape2 = image_net["pool3"].get_shape() # 获得pool3尺寸 是原图大小的1/8 120 W_t2 = utils.weight_variable([4, 4, deconv_shape2[3].value, deconv_shape1[3].value], name="W_t2") 121 b_t2 = utils.bias_variable([deconv_shape2[3].value], name="b_t2") 122 conv_t2 = utils.conv2d_transpose_strided(fuse_1, W_t2, b_t2, output_shape=tf.shape(image_net["pool3"])) 123 fuse_2 = tf.add(conv_t2, image_net["pool3"], name="fuse_2") 124 shape = tf.shape(image) # 获得原始图像大小 125 deconv_shape3 = tf.stack([shape[0], shape[1], shape[2], NUM_OF_CLASSESS]) # 矩阵拼接 126 127 W_t3 = utils.weight_variable([16, 16, NUM_OF_CLASSESS, deconv_shape2[3].value], name="W_t3") 128 b_t3 = utils.bias_variable([NUM_OF_CLASSESS], name="b_t3") 129 conv_t3 = utils.conv2d_transpose_strided(fuse_2, W_t3, b_t3, output_shape=deconv_shape3, stride=8) 130 annotation_pred = tf.argmax(conv_t3, dimension=3, name="prediction") # (224,224,1)目前理解是每个像素点所有通道取最大值 131 return tf.expand_dims(annotation_pred, dim=3), conv_t3 # 从第三维度扩展形成[b,h,w,c] 其中c=1,即224*224*1*1 132 # 返回优化器 133 def train(loss_val, var_list): 134 optimizer = tf.train.AdamOptimizer(FLAGS.learning_rate) 135 grads = optimizer.compute_gradients(loss_val, var_list=var_list) 136 if FLAGS.debug: 137 # print(len(var_list)) 138 for grad, var in grads: 139 utils.add_gradient_summary(grad, var) 140 return optimizer.apply_gradients(grads) 141 # 主函数,返回优化器的操作步骤 142 def main(argv=None): 143 keep_probability = tf.placeholder(tf.float32, name="keep_probabilty") 144 image = tf.placeholder(tf.float32, shape=[None, IMAGE_SIZE, IMAGE_SIZE, 3], name="input_image") 145 annotation = tf.placeholder(tf.int32, shape=[None, IMAGE_SIZE, IMAGE_SIZE, 1], name="annotation") 146 # 定义好FCN的网络模型 147 pred_annotation, logits = inference(image, keep_probability) 148 # 定义损失函数,这里使用交叉熵的平均值作为损失函数 149 tf.summary.image("input_image", image, max_outputs=2) 150 tf.summary.image("ground_truth", tf.cast(annotation, tf.uint8), max_outputs=2) 151 tf.summary.image("pred_annotation", tf.cast(pred_annotation, tf.uint8), max_outputs=2) 152 loss = tf.reduce_mean((tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, 153 labels=tf.squeeze(annotation, squeeze_dims=[3]), 154 name="entropy"))) 155 loss_summary = tf.summary.scalar("entropy", loss) 156 # 定义优化器, 返回需要训练的变量列表 157 trainable_var = tf.trainable_variables() 158 if FLAGS.debug: 159 for var in trainable_var: 160 utils.add_to_regularization_and_summary(var) 161 train_op = train(loss, trainable_var) 162 print("Setting up summary op...") 163 summary_op = tf.summary.merge_all() 164 # 加载数据集 165 166 print("Setting up image reader...") 167 train_records, valid_records = scene_parsing.read_dataset(FLAGS.data_dir) 168 print(len(train_records)) 169 print(len(valid_records)) 170 print("Setting up dataset reader") 171 image_options = ‘resize‘: True, ‘resize_size‘: IMAGE_SIZE 172 if FLAGS.mode == ‘train‘: 173 train_dataset_reader = dataset.BatchDatset(train_records, image_options) 174 # 读取图片 产生类对象 其中包含所有图片信息 175 validation_dataset_reader = dataset.BatchDatset(valid_records, image_options) 176 # 开始训练模型 177 sess = tf.Session() 178 print("Setting up Saver...") 179 saver = tf.train.Saver() 180 # 保存模型类实例化 181 # create two summary writers to show training loss and validation loss in the same graph 182 # need to create two folders ‘train‘ and ‘validation‘ inside FLAGS.logs_dir 183 train_writer = tf.summary.FileWriter(FLAGS.logs_dir + ‘/train‘, sess.graph) 184 validation_writer = tf.summary.FileWriter(FLAGS.logs_dir + ‘/validation‘) 185 sess.run(tf.global_variables_initializer()) 186 # 变量初始化 187 ckpt = tf.train.get_checkpoint_state(FLAGS.logs_dir) 188 if ckpt and ckpt.model_checkpoint_path: 189 # 如果存在checkpoint文件 则恢复sess 190 saver.restore(sess, ckpt.model_checkpoint_path) 191 print("Model restored...") 192 if FLAGS.mode == "train": 193 for itr in xrange(MAX_ITERATION): 194 train_images, train_annotations = train_dataset_reader.next_batch(FLAGS.batch_size) 195 feed_dict = image: train_images, annotation: train_annotations, keep_probability: 0.85 196 sess.run(train_op, feed_dict=feed_dict) 197 if itr % 10 == 0: 198 train_loss, summary_str = sess.run([loss, loss_summary], feed_dict=feed_dict) 199 print("Step: %d, Train_loss:%g" % (itr, train_loss)) 200 train_writer.add_summary(summary_str, itr) 201 if itr % 500 == 0: 202 valid_images, valid_annotations = validation_dataset_reader.next_batch(FLAGS.batch_size) 203 valid_loss, summary_sva = sess.run([loss, loss_summary], feed_dict=image: valid_images, annotation: valid_annotations, 204 keep_probability: 1.0) 205 print("%s ---> Validation_loss: %g" % (datetime.datetime.now(), valid_loss)) 206 # add validation loss to TensorBoard 207 validation_writer.add_summary(summary_sva, itr) 208 saver.save(sess, FLAGS.logs_dir + "model.ckpt", itr) 209 # 保存模型 210 elif FLAGS.mode == "visualize": 211 valid_images, valid_annotations = validation_dataset_reader.get_random_batch(FLAGS.batch_size) 212 pred = sess.run(pred_annotation, feed_dict=image: valid_images, annotation: valid_annotations, 213 keep_probability: 1.0) 214 # 预测测试结果 215 valid_annotations = np.squeeze(valid_annotations, axis=3) 216 pred = np.squeeze(pred, axis=3) 217 # 从数组的形状中删除单维条目,即把shape中为1的维度去掉 218 for itr in range(FLAGS.batch_size): 219 utils.save_image(valid_images[itr].astype(np.uint8), FLAGS.logs_dir, name="inp_" + str(5+itr)) 220 utils.save_image(valid_annotations[itr].astype(np.uint8), FLAGS.logs_dir, name="gt_" + str(5+itr)) 221 utils.save_image(pred[itr].astype(np.uint8), FLAGS.logs_dir, name="pred_" + str(5+itr)) 222 print("Saved image: %d" % itr) 223 224 if __name__ == "__main__": 225 tf.app.run()
TensorflowUtils.py
1 # Utils used with tensorflow implemetation 2 import tensorflow as tf 3 import numpy as np 4 import scipy.misc as misc 5 import os, sys 6 from six.moves import urllib 7 import tarfile 8 import zipfile 9 import scipy.io 10 from functools import reduce 11 12 # 下载VGG模型的数据 13 def get_model_data(dir_path, model_url): 14 maybe_download_and_extract(dir_path, model_url) 15 filename = model_url.split("/")[-1] 16 filepath = os.path.join(dir_path, filename) 17 if not os.path.exists(filepath): 18 raise IOError("VGG Model not found!") 19 data = scipy.io.loadmat(filepath) 20 return data 21 22 23 def maybe_download_and_extract(dir_path, url_name, is_tarfile=False, is_zipfile=False): 24 if not os.path.exists(dir_path): 25 os.makedirs(dir_path) 26 filename = url_name.split(‘/‘)[-1] 27 filepath = os.path.join(dir_path, filename) 28 if not os.path.exists(filepath): 29 def _progress(count, block_size, total_size): 30 sys.stdout.write( 31 ‘\\r>> Downloading %s %.1f%%‘ % (filename, float(count * block_size) / float(total_size) * 100.0)) 32 sys.stdout.flush() 33 34 filepath, _ = urllib.request.urlretrieve(url_name, filepath, reporthook=_progress) 35 print() 36 statinfo = os.stat(filepath) 37 print(‘Succesfully downloaded‘, filename, statinfo.st_size, ‘bytes.‘) 38 if is_tarfile: 39 tarfile.open(filepath, ‘r:gz‘).extractall(dir_path) 40 elif is_zipfile: 41 with zipfile.ZipFile(filepath) as zf: 42 zip_dir = zf.namelist()[0] 43 zf.extractall(dir_path) 44 45 46 def save_image(image, save_dir, name, mean=None): 47 """ 48 Save image by unprocessing if mean given else just save 49 :param mean: 50 :param image: 51 :param save_dir: 52 :param name: 53 :return: 54 """ 55 if mean: 56 image = unprocess_image(image, mean) 57 misc.imsave(os.path.join(save_dir, name + ".png"), image) 58 59 60 def get_variable(weights, name): 61 init = tf.constant_initializer(weights, dtype=tf.float32) 62 var = tf.get_variable(name=name, initializer=init, shape=weights.shape) 63 return var 64 65 66 def weight_variable(shape, stddev=0.02, name=None): 67 # print(shape) 68 initial = tf.truncated_normal(shape, stddev=stddev) 69 if name is None: 70 return tf.Variable(initial) 71 else: 72 return tf.get_variable(name, initializer=initial) 73 74 75 def bias_variable(shape, name=None): 76 initial = tf.constant(0.0, shape=shape) 77 if name is None: 78 return tf.Variable(initial) 79 else: 80 return tf.get_variable(name, initializer=initial) 81 82 83 def get_tensor_size(tensor): 84 from operator import mul 85 return reduce(mul, (d.value for d in tensor.get_shape()), 1) 86 87 88 def conv2d_basic(x, W, bias): 89 conv = tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding="SAME") 90 return tf.nn.bias_add(conv, bias) 91 92 93 def conv2d_strided(x, W, b): 94 conv = tf.nn.conv2d(x, W, strides=[1, 2, 2, 1], padding="SAME") 95 return tf.nn.bias_add(conv, b) 96 97 98 def conv2d_transpose_strided(x, W, b, output_shape=None, stride = 2): 99 # print x.get_shape() 100 # print W.get_shape() 101 if output_shape is None: 102 output_shape = x.get_shape().as_list() 103 output_shape[1] *= 2 104 output_shape[2] *= 2 105 output_shape[3] = W.get_shape().as_list()[2] 106 # print output_shape 107 conv = tf.nn.conv2d_transpose(x, W, output_shape, strides=[1, stride, stride, 1], padding="SAME") 108 return tf.nn.bias_add(conv, b) 109 110 111 def leaky_relu(x, alpha=0.0, name=""): 112 return tf.maximum(alpha * x, x, name) 113 114 115 def max_pool_2x2(x): 116 return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME") 117 118 119 def avg_pool_2x2(x): 120 return tf.nn.avg_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME") 121 122 123 def local_response_norm(x): 124 return tf.nn.lrn(x, depth_radius=5, bias=2, alpha=1e-4, beta=0.75) 125 126 127 def batch_norm(x, n_out, phase_train, scope=‘bn‘, decay=0.9, eps=1e-5): 128 """ 129 Code taken from http://stackoverflow.com/a/34634291/2267819 130 """ 131 with tf.variable_scope(scope): 132 beta = tf.get_variable(name=‘beta‘, shape=[n_out], initializer=tf.constant_initializer(0.0) 133 , trainable=True) 134 gamma = tf.get_variable(name=‘gamma‘, shape=[n_out], initializer=tf.random_normal_initializer(1.0, 0.02), 135 trainable=True) 136 batch_mean, batch_var = tf.nn.moments(x, [0, 1, 2], name=‘moments‘) 137 ema = tf.train.ExponentialMovingAverage(decay=decay) 138 139 def mean_var_with_update(): 140 ema_apply_op = ema.apply([batch_mean, batch_var]) 141 with tf.control_dependencies([ema_apply_op]): 142 return tf.identity(batch_mean), tf.identity(batch_var) 143 144 mean, var = tf.cond(phase_train, 145 mean_var_with_update, 146 lambda: (ema.average(batch_mean), ema.average(batch_var))) 147 normed = tf.nn.batch_normalization(x, mean, var, beta, gamma, eps) 148 return normed 149 150 151 def process_image(image, mean_pixel): 152 return image - mean_pixel 153 154 155 def unprocess_image(image, mean_pixel): 156 return image + mean_pixel 157 158 159 def bottleneck_unit(x, out_chan1, out_chan2, down_stride=False, up_stride=False, name=None): 160 """ 161 Modified implementation from github ry?! 162 """ 163 164 def conv_transpose(tensor, out_channel, shape, strides, name=None): 165 out_shape = tensor.get_shape().as_list() 166 in_channel = out_shape[-1] 167 kernel = weight_variable([shape, shape, out_channel, in_channel], name=name) 168 shape[-1] = out_channel 169 return tf.nn.conv2d_transpose(x, kernel, output_shape=out_shape, strides=[1, strides, strides, 1], 170 padding=‘SAME‘, name=‘conv_transpose‘) 171 172 def conv(tensor, out_chans, shape, strides, name=None): 173 in_channel = tensor.get_shape().as_list()[-1] 174 kernel = weight_variable([shape, shape, in_channel, out_chans], name=name) 175 return tf.nn.conv2d(x, kernel, strides=[1, strides, strides, 1], padding=‘SAME‘, name=‘conv‘) 176 177 def bn(tensor, name=None): 178 """ 179 :param tensor: 4D tensor input 180 :param name: name of the operation 181 :return: local response normalized tensor - not using batch normalization :( 182 """ 183 return tf.nn.lrn(tensor, depth_radius=5, bias=2, alpha=1e-4, beta=0.75, name=name) 184 185 in_chans = x.get_shape().as_list()[3] 186 187 if down_stride or up_stride: 188 first_stride = 2 189 else: 190 first_stride = 1 191 192 with tf.variable_scope(‘res%s‘ % name): 193 if in_chans == out_chan2: 194 b1 = x 195 else: 196 with tf.variable_scope(‘branch1‘): 197 if up_stride: 198 b1 = conv_transpose(x, out_chans=out_chan2, shape=1, strides=first_stride, 199 name=‘res%s_branch1‘ % name) 200 else: 201 b1 = conv(x, out_chans=out_chan2, shape=1, strides=first_stride, name=‘res%s_branch1‘ % name) 202 b1 = bn(b1, ‘bn%s_branch1‘ % name, ‘scale%s_branch1‘ % name) 203 204 with tf.variable_scope(‘branch2a‘): 205 if up_stride: 206 b2 = conv_transpose(x, out_chans=out_chan1, shape=1, strides=first_stride, name=‘res%s_branch2a‘ % name) 207 else: 208 b2 = conv(x, out_chans=out_chan1, shape=1, strides=first_stride, name=‘res%s_branch2a‘ % name) 209 b2 = bn(b2, ‘bn%s_branch2a‘ % name, ‘scale%s_branch2a‘ % name) 210 b2 = tf.nn.relu(b2, name=‘relu‘) 211 212 with tf.variable_scope(‘branch2b‘): 213 b2 = conv(b2, out_chans=out_chan1, shape=3, strides=1, name=‘res%s_branch2b‘ % name) 214 b2 = bn(b2, ‘bn%s_branch2b‘ % name, ‘scale%s_branch2b‘ % name) 215 b2 = tf.nn.relu(b2, name=‘relu‘) 216 217 with tf.variable_scope(‘branch2c‘): 218 b2 = conv(b2, out_chans=out_chan2, shape=1, strides=1, name=‘res%s_branch2c‘ % name) 219 b2 = bn(b2, ‘bn%s_branch2c‘ % name, ‘scale%s_branch2c‘ % name) 220 221 x = b1 + b2 222 return tf.nn.relu(x, name=‘relu‘) 223 224 225 def add_to_regularization_and_summary(var): 226 if var is not None: 227 tf.summary.histogram(var.op.name, var) 228 tf.add_to_collection("reg_loss", tf.nn.l2_loss(var)) 229 230 231 def add_activation_summary(var): 232 if var is not None: 233 tf.summary.histogram(var.op.name + "/activation", var) 234 tf.summary.scalar(var.op.name + "/sparsity", tf.nn.zero_fraction(var)) 235 236 237 def add_gradient_summary(grad, var): 238 if grad is not None: 239 tf.summary.histogram(var.op.name + "/gradient", grad)
read_MITSceneParsingData.py
1 import numpy as np 2 import os 3 import random 4 from six.moves import cPickle as pickle 5 from tensorflow.python.platform import gfile 6 import glob 7 8 import TensorflowUtils as utils 9 10 # DATA_URL = ‘http://sceneparsing.csail.mit.edu/data/ADEChallengeData2016.zip‘ 11 DATA_URL = ‘http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip‘ 12 13 14 def read_dataset(data_dir): 15 pickle_filename = "MITSceneParsing.pickle" 16 pickle_filepath = os.path.join(data_dir, pickle_filename) 17 # if not os.path.exists(pickle_filepath): 18 # utils.maybe_download_and_extract(data_dir, DATA_URL, is_zipfile=True) # 不存在文件 则下载 19 SceneParsing_folder = os.path.splitext(DATA_URL.split("/")[-1])[0] 20 result = create_image_lists(r"F:\\pyProgram\\FCN_test\\Data_zoo\\MIT_SceneParsing\\ADEChallengeData2016\\ADEChallengeData2016") 21 print ("Pickling ...") 22 with open(pickle_filepath, ‘wb‘) as f: 23 pickle.dump(result, f, pickle.HIGHEST_PROTOCOL) 24 # else: 25 print ("Found pickle file!") 26 27 with open(pickle_filepath, 28 ‘rb‘) as f: 29 # 打开pickle文件 30 result = pickle.load(f) 31 training_records = result[‘training‘] 32 validation_records = result[‘validation‘] 33 del result 34 35 return training_records, validation_records 36 37 38 def create_image_lists(image_dir): 39 if not gfile.Exists(image_dir): 40 print("Image directory ‘" + image_dir + "‘ not found.") 41 return None 42 directories = [‘training‘, ‘validation‘] 43 image_list = 44 45 for directory in directories: # 训练集和验证集 分别制作 46 file_list = [] 47 image_list[directory] = [] 48 49 # 获取images目录下所有的图片名 50 file_glob = os.path.join(image_dir, "images", directory, ‘*.‘ + ‘jpg‘) 51 file_list.extend(glob.glob(file_glob)) # 加入文件列表 包含所有图片文件全路径+文件名字 如 Data_zoo/MIT_SceneParsing/ADEChallengeData2016/images/training/hi.jpg 52 53 if not file_list: 54 print(‘No files found‘) 55 else: 56 for f in file_list: # 扫描文件列表 这里f对应文件全路径 57 filename = os.path.splitext(f.split("\\\\")[-1])[0] 58 annotation_file = os.path.join(image_dir, "annotations", directory, filename + ‘.png‘) 59 if os.path.exists(annotation_file): 60 record = ‘image‘: f, ‘annotation‘: annotation_file, ‘filename‘: filename 61 image_list[directory].append(record) 62 else: 63 print("Annotation file not found for %s - Skipping" % filename) 64 65 random.shuffle(image_list[directory]) # 对图片列表进行洗牌 66 no_of_images = len(image_list[directory]) 67 print(‘No. of %s files: %d‘ % (directory, no_of_images)) 68 69 return image_list
BatchDatsetReader.py
1 """ 2 Code ideas from https://github.com/Newmu/dcgan and tensorflow mnist dataset reader 3 """ 4 import numpy as np 5 import scipy.misc as misc 6 import imageio 7 8 class BatchDatset: 9 files = [] 10 images = [] 11 annotations = [] 12 image_options = 13 batch_offset = 0 14 epochs_completed = 0 15 16 def __init__(self, records_list, image_options=): 17 """ 18 Intialize a generic file reader with batching for list of files 19 :param records_list: list of file records to read - 20 sample record: ‘image‘: f, ‘annotation‘: annotation_file, ‘filename‘: filename 21 :param image_options: A dictionary of options for modifying the output image 22 Available options: 23 resize = True/ False 24 resize_size = #size of output image - does bilinear resize 25 color=True/False 26 """ 27 print("Initializing Batch Dataset Reader...") 28 print(image_options) 29 self.files = records_list 30 self.image_options = image_options 31 self._read_images() 32 33 def _read_images(self): 34 self.__channels = True 35 # 读取训练集图像 36 self.images = np.array([self._transform(filename[‘image‘]) for filename in self.files]) 37 self.__channels = False 38 # 读取label的图像,由于label图像是二维的,这里需要扩展为三维 39 self.annotations = np.array( 40 [np.expand_dims(self._transform(filename[‘annotation‘]), axis=3) for filename in self.files]) 41 print (self.images.shape) 42 print (self.annotations.shape) 43 44 45 def _transform(self, filename): 46 image = imageio.imread(filename) 47 if self.__channels and len(image.shape) < 3: # make sure images are of shape(h,w,3) 48 image = np.array([image for i in range(3)]) 49 50 if self.image_options.get("resize", False) and self.image_options["resize"]: 51 resize_size = int(self.image_options["resize_size"]) 52 resize_image = misc.imresize(image, 53 [resize_size, resize_size], interp=‘nearest‘) 54 else: 55 resize_image = image 56 57 return np.array(resize_image) 58 59 def get_records(self): 60 return self.images, self.annotations 61 62 def reset_batch_offset(self, offset=0): 63 self.batch_offset = offset 64 65 def next_batch(self, batch_size): 66 start = self.batch_offset 67 # 当前第几个batch 68 self.batch_offset += batch_size 69 # 读取下一个batch 所有offset偏移量+batch_size 70 if self.batch_offset > self.images.shape[0]: 71 # 如果下一个batch的偏移量超过了图片总数说明完成了一个epoch 72 self.epochs_completed += 1 # epochs完成总数+1 73 print("****************** Epochs completed: " + str(self.epochs_completed) + "******************") 74 # Shuffle the data 75 perm = np.arange(self.images.shape[0]) 76 # arange生成数组(0 - len-1) 获取图片索引 77 np.random.shuffle(perm) # 对图片索引洗牌 78 self.images = self.images[perm] # 洗牌之后的图片顺序 79 self.annotations = self.annotations[perm] # 下一个epoch从0开始 80 # Start next epoch 81 start = 0 82 self.batch_offset = batch_size # 已完成的batch偏移量 83 end = self.batch_offset # 开始到结束self.batch_offset self.batch_offset+batch_size 84 return self.images[start:end], self.annotations[start:end] # 取出batch 85 def get_random_batch(self, batch_size): 86 # 按照一个batch_size一个块,进行对所有图片总数进行随机操作,相当于洗牌工作 87 indexes = np.random.randint(0, self.images.shape[0], size=[batch_size]).tolist() 88 return self.images[indexes], self.annotations[indexes]
遇到的问题及解决办法:
scipy.misc模块中imread函数以失效,用imageio.imread代替
scipy模块版本与pillow版本不匹配,需将scipy降到1.2.1版本,才能和 pillow6.0.0以上版本相容
(https://www.lfd.uci.edu/~gohlke/pythonlibs/网址中最低版本1.3.0, 所以采用pip install scipy==1.2.1方式安装即可)
读取pickle文件时,判断文件是否存在的函数出现问题,不存在也会自动创建 所以无论存不存在都会判断为存在,此处为找到好的解决办法,只能不做判 断,载入数据集时是不包含pickle文件,所以根据数据集直接生成
Windows操作系统和Linux文件路径表示方式不一样,Windows是‘\\’,Linux是‘/’
本周的进度就是这些。
马上就要开学了,下一周会重点复习UML和java,加油!
以上是关于软件工程学习进度第八周暨暑期学习进度之第八周汇总的主要内容,如果未能解决你的问题,请参考以下文章