sklearn数据获取与预处理
Posted draven123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sklearn数据获取与预处理相关的知识,希望对你有一定的参考价值。
sklearn
Key_Word
sklearn, datasets, DataFrame, load_*
preprocessing, MinMaxScaler, scaler, fit, transform, data, target
sklearn数据获取
# In[1]: import sklearn # In[2]: sklearn.__version__ # In[6]: import numpy as np import pandas as pd import matplotlib.pyplot as plt get_ipython().run_line_magic(‘matplotlib‘, ‘inline‘) #在jupyter中可视化的展示图形 from sklearn import datasets #从sklearn导入数据集 iris = datasets.load_iris() # In[10]: iris iris.data iris[‘target‘] # In[17]: # 利用dataframe做简单的可视化分析 df = pd.DataFrame(iris.data, columns = iris.feature_names) # 是一个表格 df[‘target‘] = iris.target # 表头字段就是key df.plot(figsize = (12, 8))
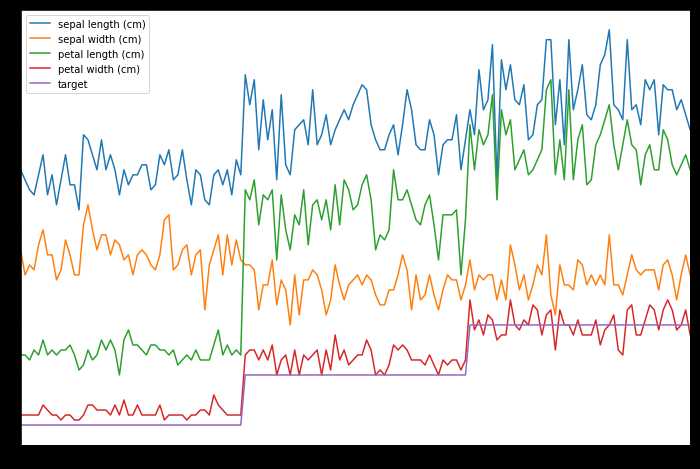
数据的预处理
数据的标准化: 将每一个数值调整到某一个数量级下
from sklearn import preprocessing # sklearn的数据标准化都在preprocessing下
数据的归一化
数据的二值化
非线性转换
数据特征编码
处理缺失值
数据标准化
Key_Word
preprocessing, MinMaxScaler, scaler, fit, transform, data, target
from sklearn import preprocessing scaler = preprocessing.MinMaxScaler() # scaler: 定标器 # MinMaxScaler将样本特征值线性缩放到0,1之间 scaler.fit(iris.data) # 先fit data = scaler.transform(iris.data) # 再transform 也可以二合一写成fit_transform target = iris.target
以上是关于sklearn数据获取与预处理的主要内容,如果未能解决你的问题,请参考以下文章