Fast R-CNN
Posted pacino12134
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Fast R-CNN相关的知识,希望对你有一定的参考价值。
---恢复内容开始---
与R-CNN的不同:
- 最后一个卷积层后跟一个ROI pooling(也就是pool5变成ROI pooling),再接全连接层;
- 使用多任务损失函数,将边框回归直接加到CNN中训练;
- 放弃SVM,改为softmax;
Fast R-CNN是端到端的,解决了R-CNN的速度慢、空间大的缺点。
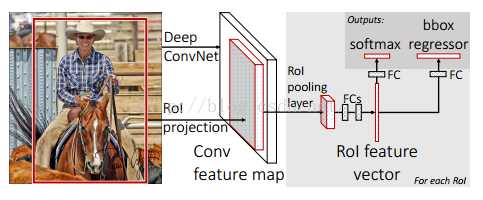
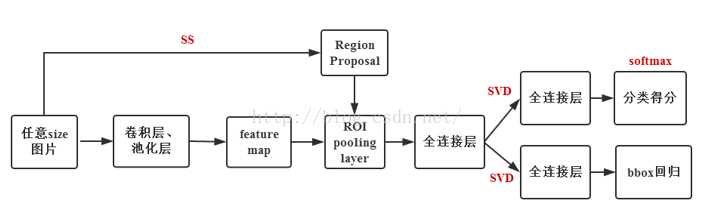
训练:
使用5个最大池化层和5~13个不等的卷积层的三种网络进行预训练:CaffeNet,VGG_CNN_M_1024,VGG-16,使用之前要先做出如下改动:
- 用RoI pooling layer取代网络的最后一个池化层
- 最后一个FC层和softmax被替换成fast R-CNN框架图介绍的两个并列层
- 输入两组数据到网络:一组图片和每一个图片的一组RoIs(分别由两个任务来负责);
对训练集中的图片,SS取出每个图片对应的一些proposal,对于每一个proposal,如果和ground truth中的proposal中的IOU值>=0.5,就把GT的标签信息给这个proposal,否则就标记为背景。
使用mini-batch=128,25%来自非背景标签的proposal,其余来自标记为背景的proposal,进行微调训练CNN,最后一层的结果包含分类信息和位置修正信息,用多任务的loss,一个是分类的损失函数,一个是位置的损失函数。
测试过程:
selective search方法提取图片的2000个proposal,并保存到文件;
将图片输入到已经训好的多层全卷积网络,对每一个proposal,获得对应的RoI Conv featrue map;
对每一个RoI Conv featrue map得到固定大小的feture map,并将其输入到后续的FC层(对全连接层进行了提速方法),最后一层输出类别相关信息和4个boundinf box的修正偏移量;
对bounding box 按照上述得到的位置偏移量进行修正,再根据nms对所有的proposal进行筛选,即可得到对该张图片的bounding box预测值以及每个bounding box对应的类和score。
代价函数:
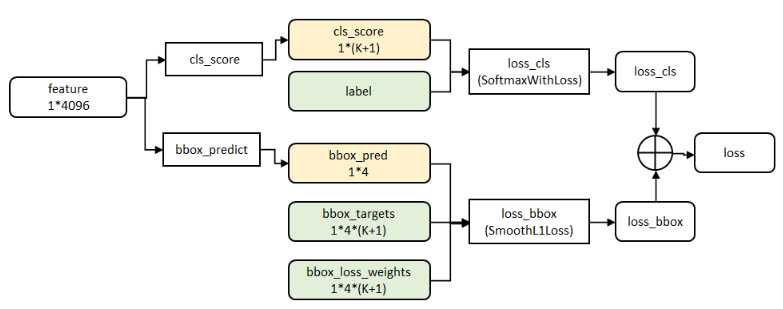
分类:
cls_score层用于分类,输出K+1维数组P,表示属于K类和背景的概率。对每个ROI(region of interesting)输出离散型概率分布(softmax计算出来):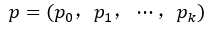
loss_cls层评估分类代价。由真实分类u对应的概率决定(类似于softmax,可以看做是概率):
![]()
回归:
bbox_prdict层用于调整候选区域位置,输出bounding box回归的位移,输出4*K维数组t,分别表示属于K类时,应该平移缩放的参数。
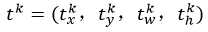
k表示类别的索引,
是指相对于object proposal尺度不变的平移,
是指对数空间中相对于object proposal的高与宽。
loss_bbox评估检测框定位代价。比较真实分类对应的预测参数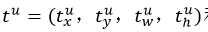 和真实平移缩放参数为
和真实平移缩放参数为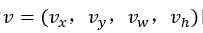 的差别:
的差别:
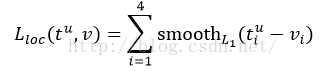
最后总损失为(两者加权和,如果分类为背景则不考虑定位损失):
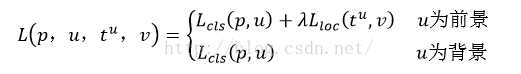
规定u=0为背景类(也就是负标签),那么艾弗森括号指数函数[u≥1]表示背景候选区域即负样本不参与回归损失,不需要对候选区域进行回归操作。
λ控制分类损失和回归损失的平衡。Fast R-CNN论文中,所有实验λ=1。
艾弗森括号指数函数为:
源码中bbox_loss_weights用于标记每一个bbox是否属于某一个类
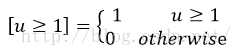
以上是关于Fast R-CNN的主要内容,如果未能解决你的问题,请参考以下文章
Java 集合系列04之 fail-fast总结(通过ArrayList来说明fail-fast的原理解决办法)
Java 集合系列04之 fail-fast总结(通过ArrayList来说明fail-fast的原理解决办法)
Java 集合系列04之 fail-fast总结(通过ArrayList来说明fail-fast的原理解决办法)