kafka深入研究之路-剖析各原理02
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka深入研究之路-剖析各原理02相关的知识,希望对你有一定的参考价值。
kafka深入研究之路(1)-剖析各原理02接着上一文的内容 继续升入研究
topic如何创建于删除的
topic的创建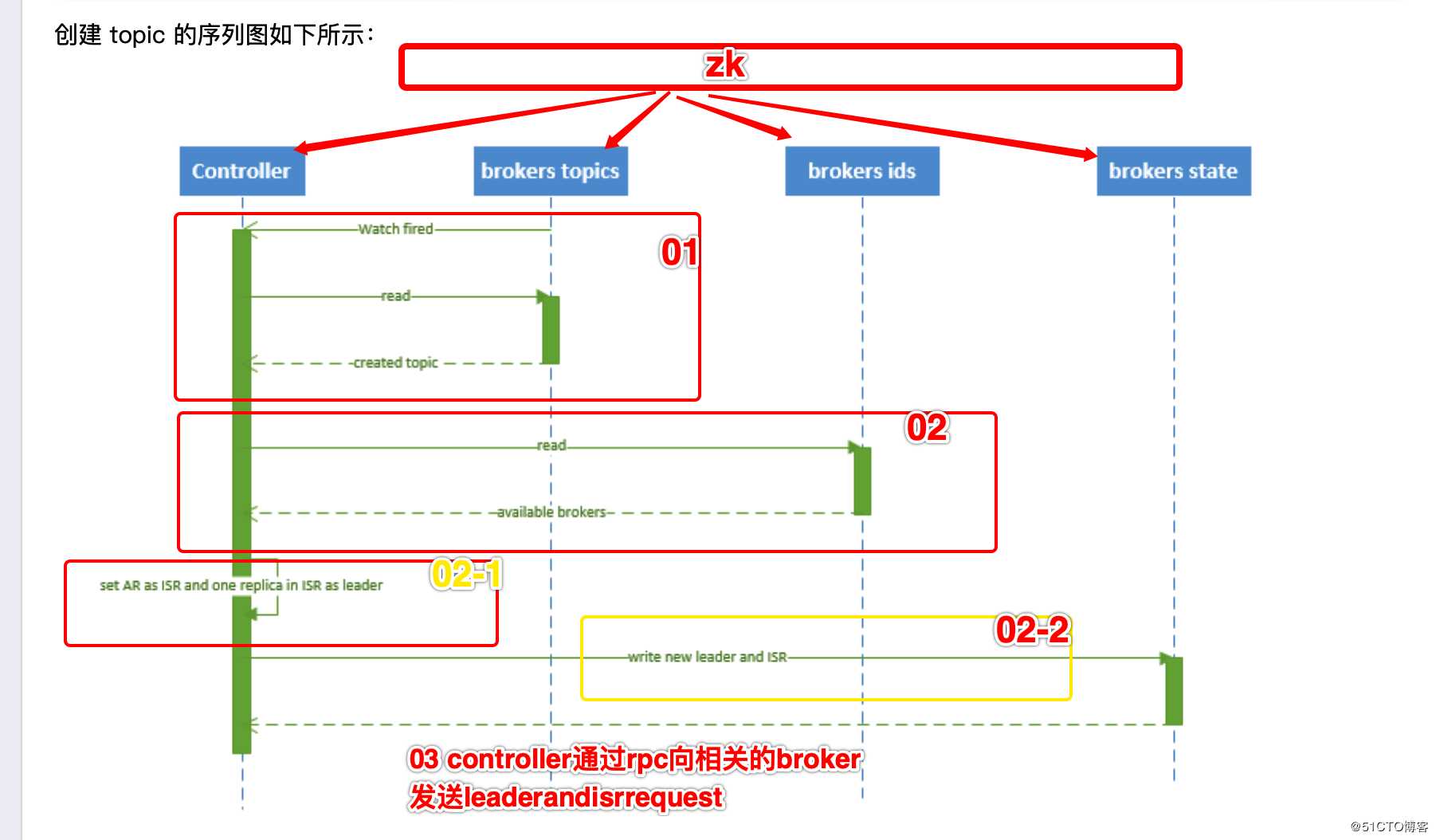
具体流程文字为:
1、 controller 在 ZooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被创建,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。
2、 controller从 /brokers/ids 读取当前所有可用的 broker 列表,对于 set_p 中的每一个 partition:
2.1、 从分配给该 partition 的所有 replica(称为AR)中任选一个可用的 broker 作为新的 leader,并将AR设置为新的 ISR
2.2、 将新的 leader 和 ISR 写入 /brokers/topics/[topic]/partitions/[partition]/state
3、 controller 通过 RPC 向相关的 broker 发送 LeaderAndISRRequest。注意:此部分 和 partition 的leader选举过程很类似 都是需要 zk参与 相关信息都是记录到zk中
controller在这些过程中启到非常重要的作用。
topic的删除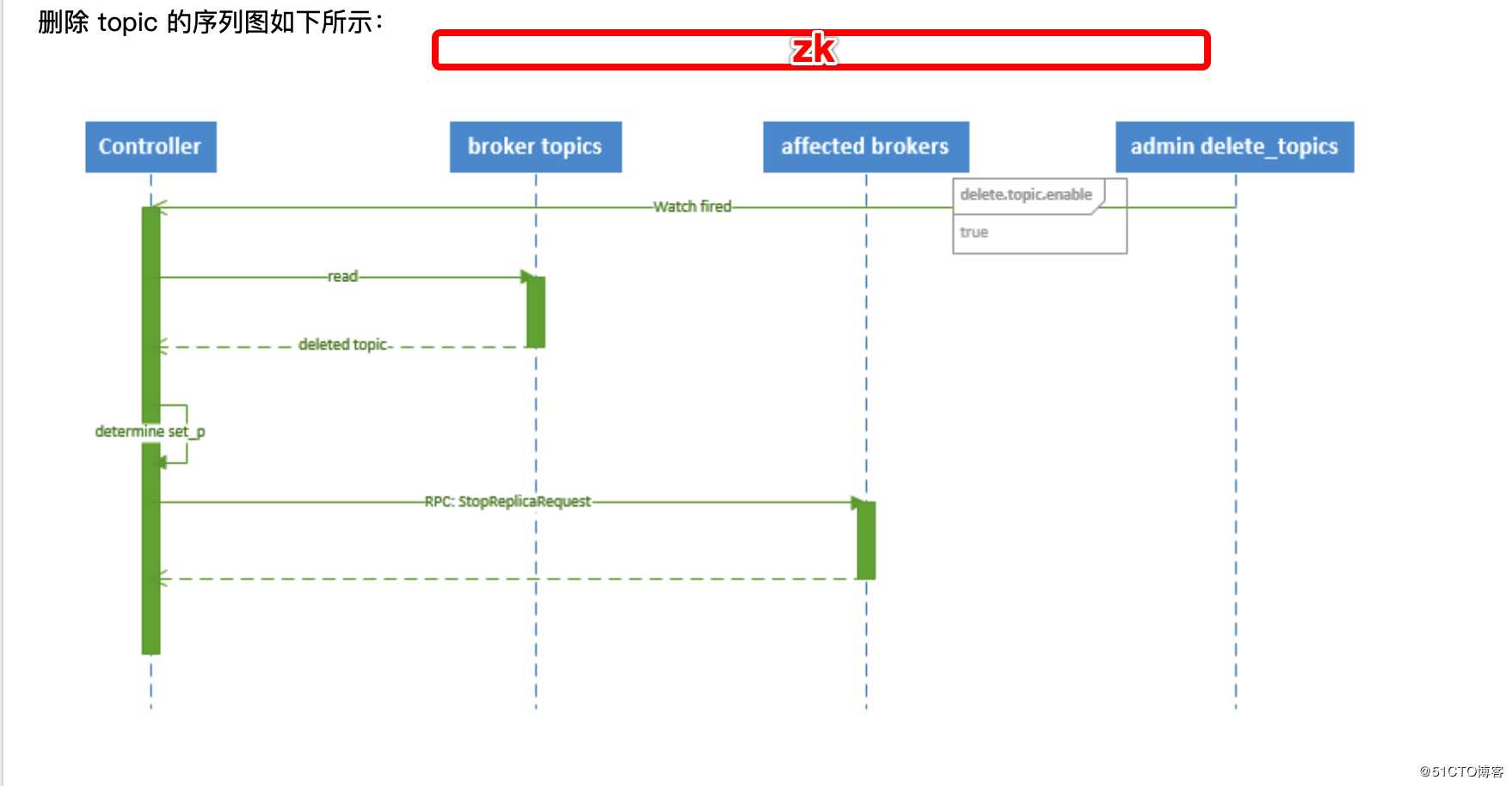
文字过程:
1、 controller 在 zooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被删除,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。
2、 若 delete.topic.enable=false,结束;否则 controller 注册在 /admin/delete_topics 上的 watch 被 fire,controller 通过回调向对应的 broker 发送 StopReplicaRequest。前面我们讲到的很多的处理故障过程 包括 topic创建删除 partition leader的转换 broker发生故障的过程中如何保证高可用 都涉及到了一个组件 controller,关于kafka中出现的相关概念名词,我会专门的写一个博客,这里先简单的提一下。
Controller:Kafka 集群中的其中一个服务器,用来进行 Leader Election 以及各种 Failover。
大家有没有想过一个问题,就是如果controller出现了故障,怎么办,如何failover的呢?我们往下看。
首先我们最一个实验,我们在zk中找到controller在哪个broker上,并查看controller_epoch的次数
[zk: localhost:2181(CONNECTED) 14] ls /kafkagroup/controller
controller_epoch controller
[zk: localhost:2181(CONNECTED) 14] ls /kafkagroup/controller
[]
[zk: localhost:2181(CONNECTED) 15] get /kafkagroup/controller
"version":1,"brokerid":1002,"timestamp":"1566648802297"
[zk: localhost:2181(CONNECTED) 22] get /kafkagroup/controller_epoch
23我们可以看到当前的controller在1002上 在此之前发了23次controller的切换
我们手动到 1002节点上杀死kafka进程
[hadoop@kafka02-55-12$ jps
11665 Jps
10952 Kafka
11068 ZooKeeperMain
10495 QuorumPeerMain
[hadoop@kafka02-55-12$ kill -9 10952
[hadoop@kafka02-55-12$ jps
11068 ZooKeeperMain
11678 Jps
10495 QuorumPeerMain再看zk上的信息,相关信息已经同步到zk中了
[zk: localhost:2181(CONNECTED) 16] get /kafkagroup/controller
"version":1,"brokerid":1003,"timestamp":"1566665835022"
[zk: localhost:2181(CONNECTED) 22] get /kafkagroup/controller_epoch
24
[zk: localhost:2181(CONNECTED) 25] ls /kafkagroup/brokers
[ids, topics, seqid]
[zk: localhost:2181(CONNECTED) 26] ls /kafkagroup/brokers/ids
[1003, 1001]在后台日志中就会看到很多
[hadoop@kafka03-55-13 logs]$ vim state-change.log
[2019-08-25 01:01:07,886] TRACE [Controller id=1003 epoch=24] Received response error_code=0 for request UPDATE_METADATA wit
h correlation id 7 sent to broker 10.211.55.13:9092 (id: 1003 rack: null) (state.change.logger)
[hadoop@kafka03-55-13 logs]$ pwd
/data/kafka/kafka-server-logs/logs
state改变的信息
[hadoop@kafka03-55-13 logs]$ tailf controller.log
[2019-08-25 01:05:42,295] TRACE [Controller id=1003] Leader imbalance ratio for broker 1002 is 1.0 (kafka.controller.KafkaCont
roller)
[2019-08-25 01:05:42,295] INFO [Controller id=1003] Starting preferred replica leader election for partitions (kafka.controll
er.KafkaController)
接下来,我们具体的分析一下,他到底内部发生了什么,如何切换的
当 controller 宕机时会触发 controller failover。每个 broker 都会在 zookeeper 的 "/controller" 节点注册 watcher,当 controller 宕机时 zookeeper 中的临时节点消失,所有存活的 broker 收到 fire 的通知,每个 broker 都尝试创建新的 controller path,只有一个竞选成功并当选为 controller。
当新的 controller 当选时,会触发 KafkaController.onControllerFailover 方法,在该方法中完成如下操作:
1、 读取并增加 Controller Epoch。
2、 在 reassignedPartitions Patch(/admin/reassign_partitions) 上注册 watcher。
3、 在 preferredReplicaElection Path(/admin/preferred_replica_election) 上注册 watcher。
4、 通过 partitionStateMachine 在 broker Topics Patch(/brokers/topics) 上注册 watcher。
5、 若 delete.topic.enable=true(默认值是 false),则 partitionStateMachine 在 Delete Topic Patch(/admin/delete_topics) 上注册 watcher。
6、 通过 replicaStateMachine在 Broker Ids Patch(/brokers/ids)上注册Watch。
7、 初始化 ControllerContext 对象,设置当前所有 topic,“活”着的 broker 列表,所有 partition 的 leader 及 ISR等。
8、 启动 replicaStateMachine 和 partitionStateMachine。
9、 将 brokerState 状态设置为 RunningAsController。
10、 将每个 partition 的 Leadership 信息发送给所有“活”着的 broker。
11、 若 auto.leader.rebalance.enable=true(默认值是true),则启动 partition-rebalance 线程。
12、 若 delete.topic.enable=true 且Delete Topic Patch(/admin/delete_topics)中有值,则删除相应的Topic。
可以看到,都是在zk上进行交互,controller的从新选举会依次通知 zk中相关的位置 并注册watcher ,在此过程中 就会发送 partition的leader的选举,还会发生partition-rebalanced 删除无用的topic等一系列操作(因为我们这里是直接考虑的最糟糕的情况就是broker宕机了一个,然而宕机的这台上就是controller)
consumer是如何消费消息的
重要概念:每个 Consumer 都划归到一个逻辑 Consumer Group 中,一个 Partition 只能被同一个 Consumer Group 中的一个 Consumer 消费,但可以被不同的 Consumer Group 消费。
若 Topic 的 Partition 数量为 p,Consumer Group 中订阅此 Topic 的 Consumer 数量为 c, 则:
p < c: 会有 c - p 个 consumer闲置,造成浪费
p > c: 一个 consumer 对应多个 partition
p = c: 一个 consumer 对应一个 partition
应该合理分配 Consumer 和 Partition 的数量,避免造成资源倾斜,
本人建议最好 Partiton 数目是 Consumer 数目的整数倍。
在consumer消费的过程中如何把partition分配给consumer?
也可以理解为consumer发生rebalance的过程是如何的?
生产过程中 Broker 要分配 Partition,消费过程这里,也要分配 Partition 给消费者。
类似 Broker 中选了一个 Controller 出来,消费也要从 Broker 中选一个 Coordinator,用于分配 Partition。// Coordinator 和 Controller 都是一个概念,协调者 组织者
当 Partition 或 Consumer 数量发生变化时,比如增加 Consumer,减少 Consumer(主动或被动),增加 Partition,都会进行 consumer的Rebalance。//发生rebalance发生在consumer端
见图: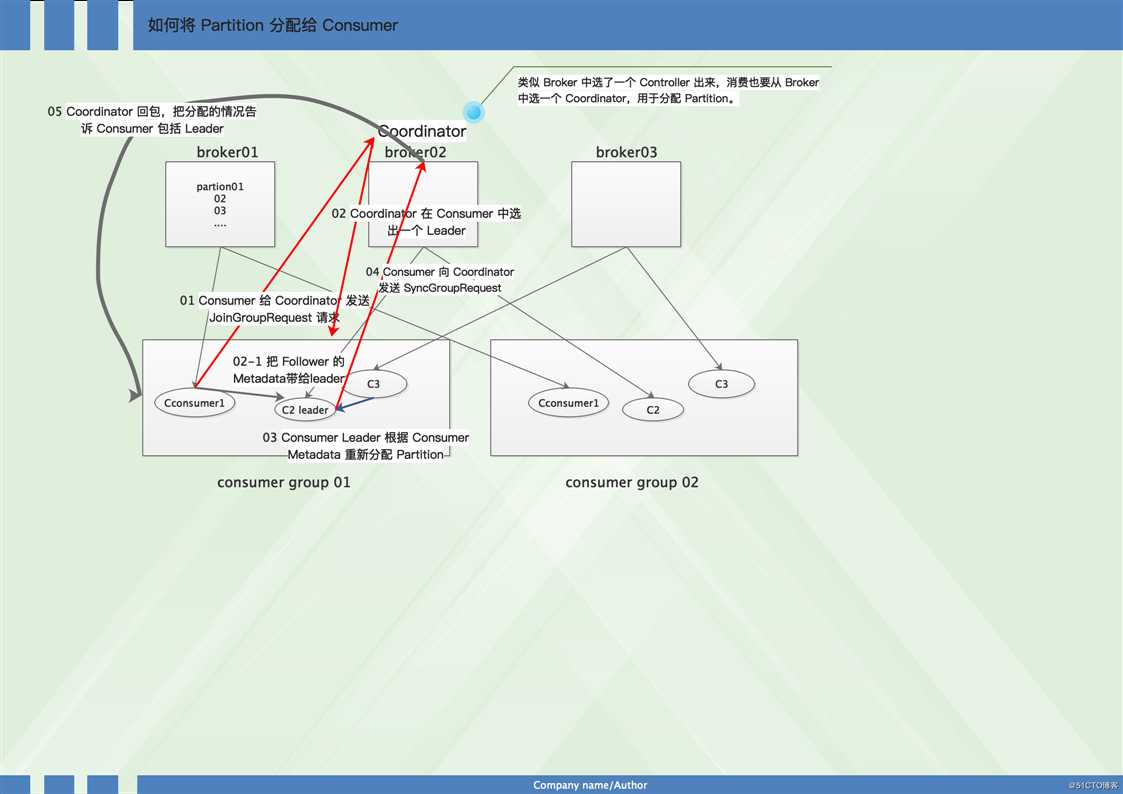
文字信息为:
1、Consumer 给 Coordinator 发送 JoinGroupRequest 请求。这时其他 Consumer 发 Heartbeat 请求过来时,Coordinator 会告诉他们,要 Rebalance了。其他 Consumer 也发送 JoinGroupRequest 请求。
2、Coordinator 在 Consumer 中选出一个 Leader,其他作为 Follower,通知给各个 Consumer,对于 Leader,还会把 Follower 的 Metadata 带给它。
3、Consumer Leader 根据 Consumer Metadata 重新分配 Partition。
4、Consumer 向 Coordinator 发送 SyncGroupRequest,其中 Leader 的 SyncGroupRequest 会包含分配的情况。
5、Coordinator 回包,把分配的情况告诉 Consumer,包括 Leader。
接下来思考一个问题,consumer是如何取消息的 Consumer Fetch Message
Consumer 采用"拉模式"消费消息,这样 Consumer 可以自行决定消费的行为。
Consumer 调用 Poll(duration)从服务器拉取消息。拉取消息的具体行为由下面的配置项决定:
#consumer.properties
#消费者最多 poll 多少个 record
max.poll.records=500
#消费者 poll 时 partition 返回的最大数据量
max.partition.fetch.bytes=1048576
#Consumer 最大 poll 间隔
#超过此值服务器会认为此 consumer failed
#并将此 consumer 踢出对应的 consumer group
max.poll.interval.ms=300000小结:
1、在 Partition 中,每个消息都有一个 Offset。新消息会被写到 Partition 末尾(最新的一个 Segment 文件末尾), 每个 Partition 上的消息是顺序消费的,不同的 Partition 之间消息的消费顺序是不确定的。
2、若一个 Consumer 消费多个 Partition, 则各个 Partition 之前消费顺序是不确定的,但在每个 Partition 上是顺序消费。
3、若来自不同 Consumer Group 的多个 Consumer 消费同一个 Partition,则各个 Consumer 之间的消费互不影响,每个 Consumer 都会有自己的 Offset。
举个官方小栗子: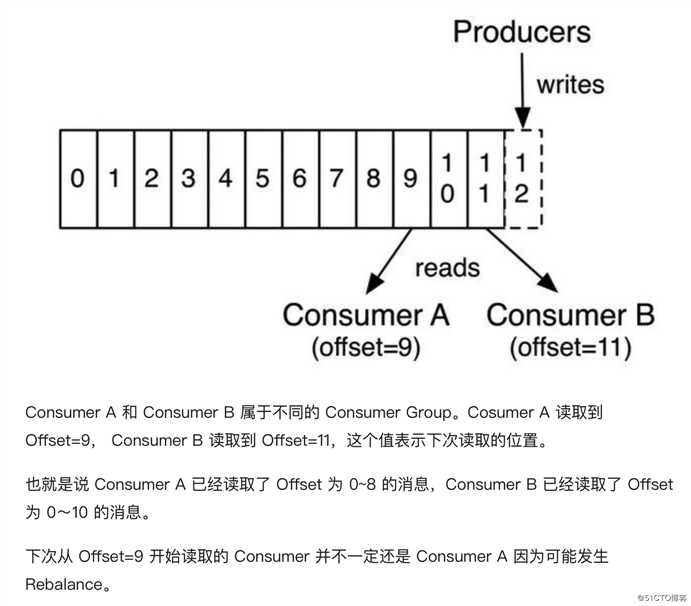
Offset 如何保存?
Consumer 消费 Partition 时,需要保存 Offset 记录当前消费位置。
Offset 可以选择自动提交或调用 Consumer 的 commitSync() 或 commitAsync() 手动提交,相关配置为:
#是否自动提交 offset
enable.auto.commit=true
#自动提交间隔。enable.auto.commit=true 时有效
auto.commit.interval.ms=5000
//enable.auto.commit 的默认值是 true;就是默认采用自动提交的机制。
auto.commit.interval.ms 的默认值是 5000,单位是毫秒。5 秒Offset 保存在名叫 __consumeroffsets 的 Topic 中。写消息的 Key 由 GroupId、Topic、Partition 组成,Value 是 Offset。
一般情况下,每个 Key 的 Offset 都是缓存在内存中,查询的时候不用遍历 Partition,如果没有缓存,第一次就会遍历 Partition 建立缓存,然后查询返回
__consumeroffsets 的 Partition 数量由下面的 Server 配置决定:
offsets.topic.num.partitions=50
默然的consumeroffsets是没有repale副本的 需要我们通过在一开始的参数指定,或者通过后期的增加 consumeroffsets 的副本json的方式动态添加
auto.create.topics.enable=true
default.replication.factor=2
num.partitions=3Offset 保存在哪个分区上,即 __consumeroffsets 的分区机制,可以表示为
groupId.hashCode() mode groupMetadataTopicPartitionCount
groupMetadataTopicPartitionCount 是上面配置的分区数。因为一个 Partition 只能被同一个 Consumer Group 的一个 Consumer 消费,因此可以用 GroupId 表示此 Consumer 消费 Offeset 所在分区。
参考链接Wie:
Kafka学习之路 (三)Kafka的高可用 https://www.cnblogs.com/qingyunzong/p/9004703.html
理解Kafka消费者属性的enable.auto.commit https://blog.csdn.net/chaiyu2002/article/details/89472416
以上是关于kafka深入研究之路-剖析各原理02的主要内容,如果未能解决你的问题,请参考以下文章