Java LinkedHashMap解析
Posted elinlinlinlog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java LinkedHashMap解析相关的知识,希望对你有一定的参考价值。
LinkedHashMap继承了HashMap
LinkedHashMap是一种记录了键值对的先后顺序的HashMap,因此LinkedHashMap的键值对对象需要记录对前后对象的引用,简言之就是增加了双向链表引用的哈希表
static class Entry<K,V> extends HashMap.Node<K,V>
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next)
super(hash, key, value, next);
构造方法:
LinkedHashMap提供了五种构造方法,基本上是调用父类HashMap的构造方法,并设置accessOrder为false
LinkedHashMap存储数据是有序的,而且分为两种:插入顺序和访问顺序。
这里accessOrder设置为false,表示不是访问顺序而是插入顺序存储的,这也是默认值,表示LinkedHashMap中存储的顺序是按照调用put方法插入的顺序进行排序的。LinkedHashMap也提供了可以设置accessOrder的构造方法。
访问顺序存储的LinkedHashMap会把get方法对应的Entry节点放置在Entry链表表尾
/**
* Constructs an empty @code LinkedHashMap instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - @code true for
* access-order, @code false for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder)
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
根据key获取元素 get()
public V get(Object key)
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
getNode调用HashMap的getNode(),可见获取元素的逻辑是一致的;
当顺序设置为访问顺序时,会修改前后引用(afterNodeAccess()),将该节点置于尾部;
添加元素 put()
LinkedHashMap并没有重写put(),但是重写了newNode()方法,以添加前后引用;
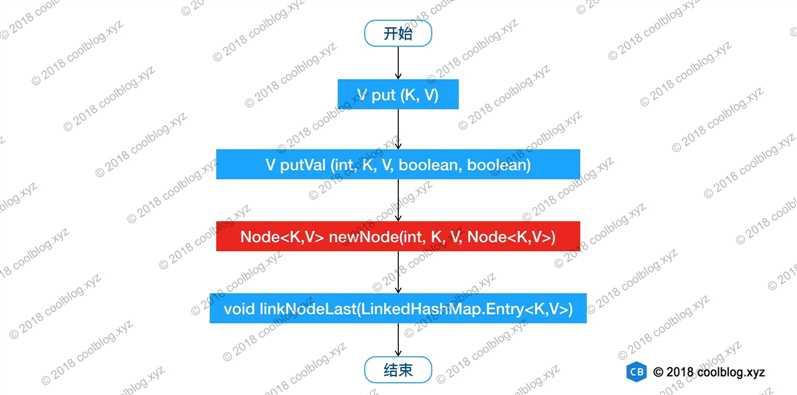
删除元素 remove()
与put()一致,LinkedHashMap重写了afterNodeRemoval()以实现引用的改变;
重写的逻辑如下:
根据 hash 定位到桶位置
遍历链表或调用红黑树相关的删除方法
从 LinkedHashMap 维护的双链表中移除要删除的节点
这部分的逻辑是
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p)
void afterNodeInsertion(boolean evict)
void afterNodeRemoval(Node<K,V> p) 以上是HashMap的方法,实现为空;通过子类的实现以补充访问、添加、删除后应进行的逻辑;LinkedHashMap重写了以上方法。
目前JDK中也只有LinkedHashMap重写了该方法。
LinkedHashMap的改变在于维护双向链表,包括访问、添加、删除对节点引用的改变。实际上链表的结构可能较为复杂,存在在红黑树上设置前后节点;
LinkedHashMap提供一种思路,基于访问顺序的链表;这种特性可以应用于实现LRU缓存;比如可以覆写一部分方法,以实现一个维护了固定长度的、淘汰了访问较少的key的哈希表;
Map的put、get、remove的设计也提供了一种模式,在可能会出现改动、或丰富逻辑之处封装方法或添加空方法,以应对未来的改动、子类的重写。
以上是关于Java LinkedHashMap解析的主要内容,如果未能解决你的问题,请参考以下文章