kafka深入研究之路-剖析各原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka深入研究之路-剖析各原理相关的知识,希望对你有一定的参考价值。
kafka深入研究之路(1)-剖析各原理引言:来到了新公司,需要对kafka组件有很深的研究,本人之前对老版的kafka有过一定的研究,但是谈不上深入,新公司力推kafka,比较kafka作为消息系统在目前的市场上的占有率还是很高的,可以看本人之前kafka的博客中有关kafka的优点和为什么要用kafka。
在众多优点中,我本人认为最重要的2个优点如下:
1、削峰
数据库的处理能力是有限的,在峰值期,过多的请求落到后台,一旦超过系统的处理能力,可能会使系统挂掉。
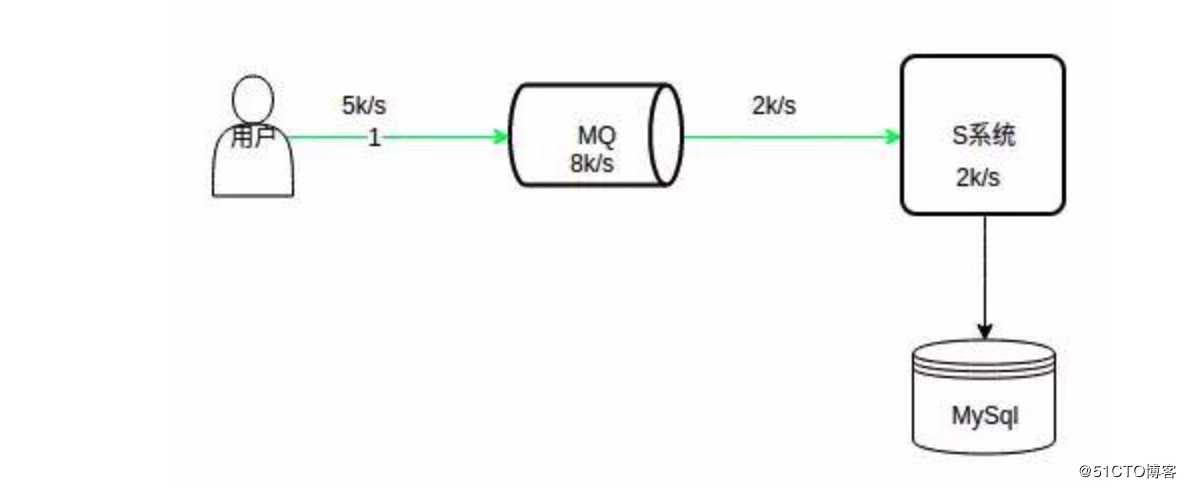
如上图所示,系统的处理能力是 2k/s,MQ 处理能力是 8k/s,峰值请求 5k/s,MQ 的处理能力远远大于数据库,在高峰期,请求可以先积压在 MQ 中,系统可以根据自身的处理能力以 2k/s 的速度消费这些请求。
这样等高峰期一过,请求可能只有 100/s,系统可以很快的消费掉积压在 MQ 中的请求。
注意,上面的请求指的是写请求,查询请求一般通过缓存解决。
2、解耦
如下场景,S 系统与 A、B、C 系统紧密耦合。由于需求变动,A 系统修改了相关代码,S 系统也需要调整 A 相关的代码。
过几天,C 系统需要删除,S 紧跟着删除 C 相关代码;又过了几天,需要新增 D 系统,S 系统又要添加与 D 相关的代码;再过几天,程序猿疯了...
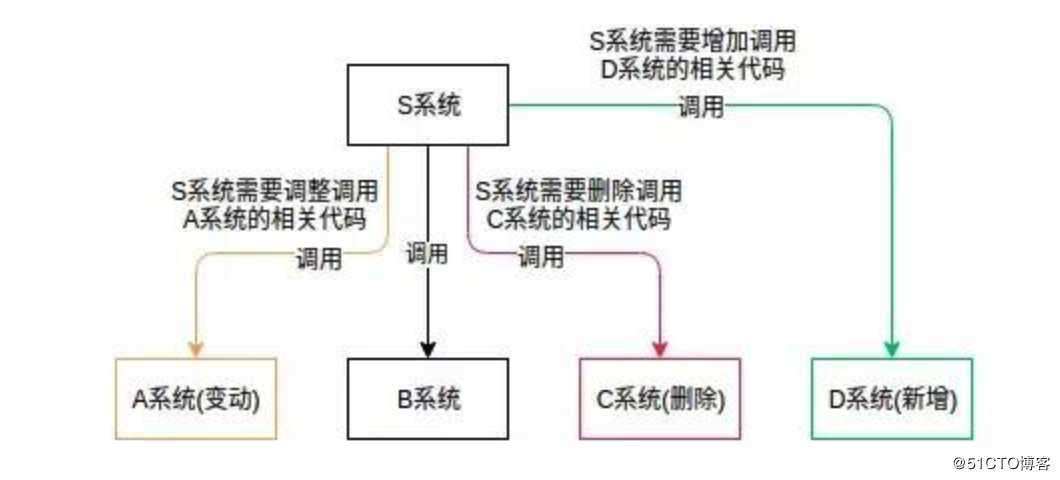
这样各个系统紧密耦合,不利于维护,也不利于扩展。现在引入 MQ,A 系统变动,A 自己修改自己的代码即可;C 系统删除,直接取消订阅;D 系统新增,订阅相关消息即可。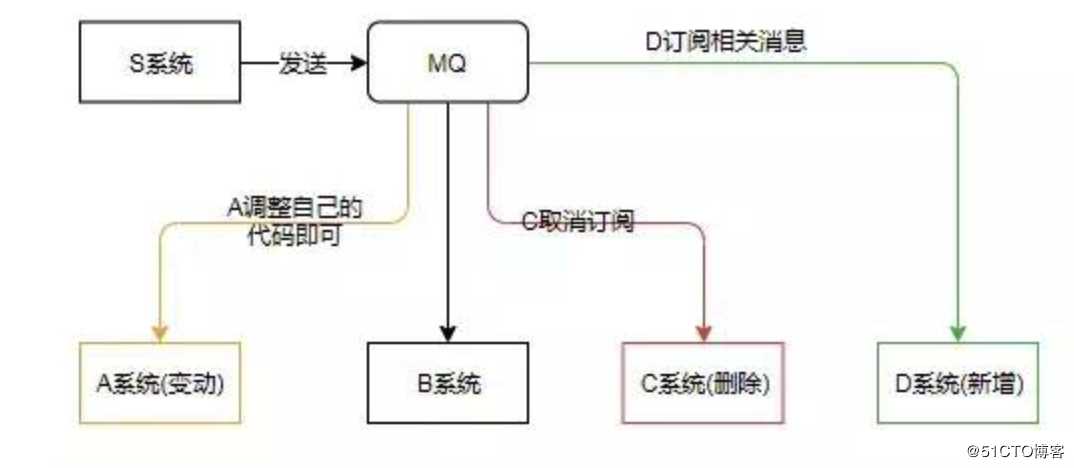
这样通过引入消息中间件,使各个系统都与 MQ 交互,从而避免它们之间的错综复杂的调用关系。
kafka架构原理:
最经典的图也就是官方的图了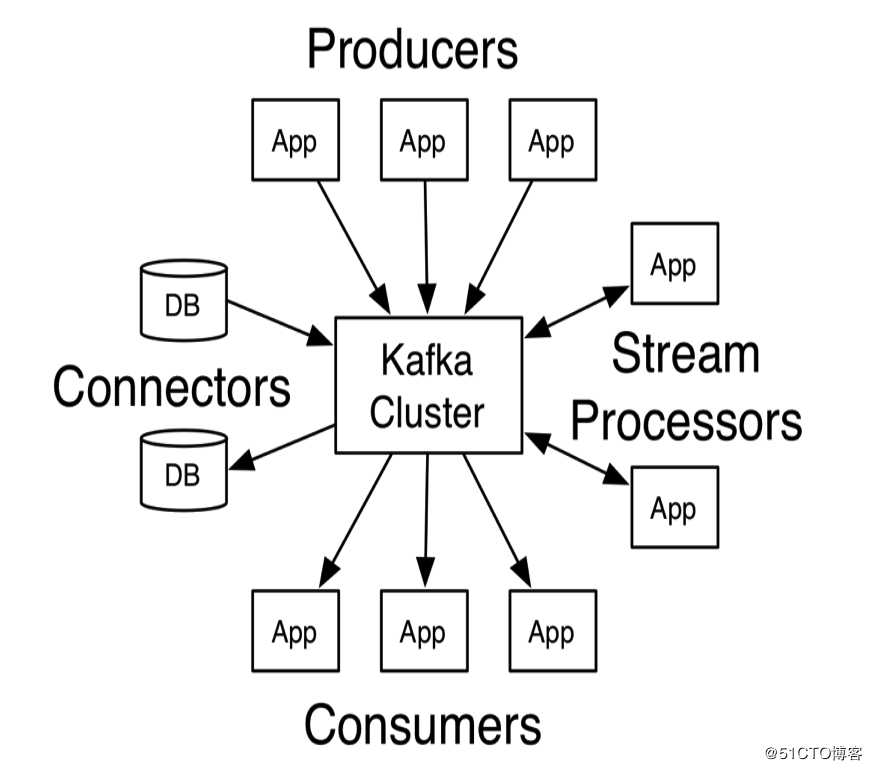
找了一些其他博主的图:这里自己就懒的画了
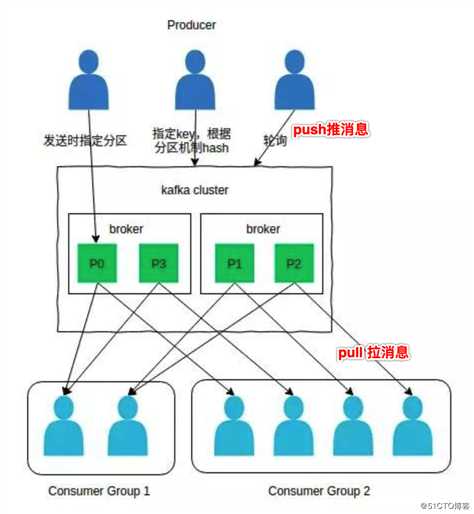
通俗点讲:就是producer ----> kafka cluster(brokers) -----> consumer
生产者生产消息 经过 kafka队列 被消费者消费
相关的组件概念见:
topic and logs
废话不多说,先见图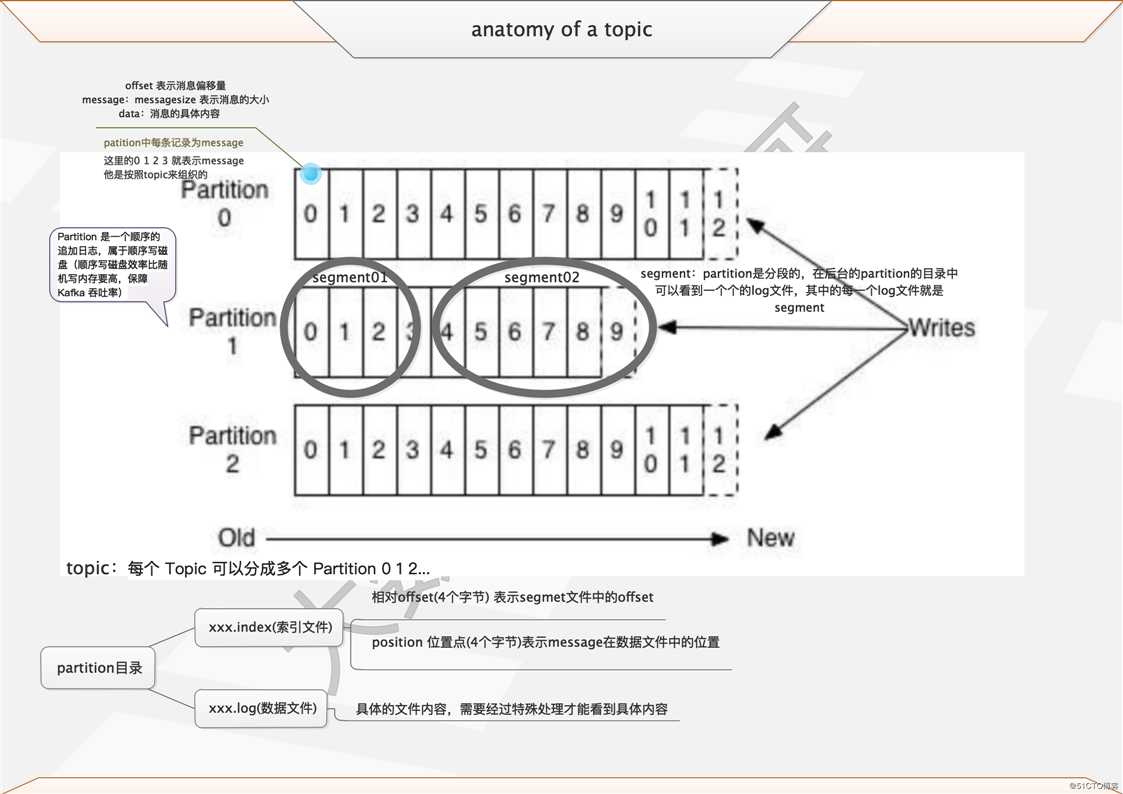
文字解释如下:
Message 是按照 Topic 来组织的,每个 Topic 可以分成多个 Partition(对server.properties/num.partitions)。 本人习惯性配置文件为num.partitions=broker个数,人为的分配到各个节点上。
Partition 中的每条记录(Message)包含三个属性:Offset,messageSize 和 Data。
其中 Offset 表示消息偏移量;messageSize 表示消息的大小;Data 表示消息的具体内容。
Partition 是以文件的形式存储在文件系统中,位置由 server.properties/log.dirs 指定,其命名规则为 <topic_name>-<partition_id>。
生产配置文件为:log.dirs=/data/kafka/kafka-logs
[hadoop@kafka03-55-13 kafka-logs]$ pwd
/data/kafka/kafka-logs
[hadoop@kafka03-55-13 kafka-logs]$ ls |grep mjh
topic-by-mjh-0
topic-by-mjh-1
topic-by-mjh-10
topic-by-mjh-11
topic-by-mjh-12
...
...
...Partition 可能位于不同的 Broker 上,Partition 是分段的,每个段是一个 Segment 文件。
Partition 目录下包括了数据文件和索引文件
[hadoop@kafka03-55-13 kafka-logs]$ cd topic-by-mjh-0
[hadoop@kafka03-55-13 topic-by-mjh-0]$ ll
total 4
-rw-rw-r-- 1 hadoop hadoop 10485760 Aug 24 20:13 00000000000000000334.index
-rw-rw-r-- 1 hadoop hadoop 0 Aug 13 17:42 00000000000000000334.log
-rw-rw-r-- 1 hadoop hadoop 10485756 Aug 24 20:13 00000000000000000334.timeindex
-rw-rw-r-- 1 hadoop hadoop 4 Aug 16 14:16 leader-epoch-checkpointIndex 采用稀疏存储的方式,它不会为每一条 Message 都建立索引,而是每隔一定的字节数建立一条索引,避免索引文件占用过多的空间。
缺点是没有建立索引的 Offset 不能一次定位到 Message 的位置,需要做一次顺序扫描,但是扫描的范围很小。
索引包含两个部分(均为 4 个字节的数字),分别为相对 Offset 和 Position。
相对 Offset 表示 Segment 文件中的 Offset,Position 表示 Message 在数据文件中的位置。
小结:
1、Partition 是一个顺序的追加日志,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障 Kafka 吞吐率)。
2、Kafka 的 Message 存储采用了分区(Partition),磁盘顺序读写,分段(LogSegment)和稀疏索引这几个手段来达到高效性。
Partition and Replica
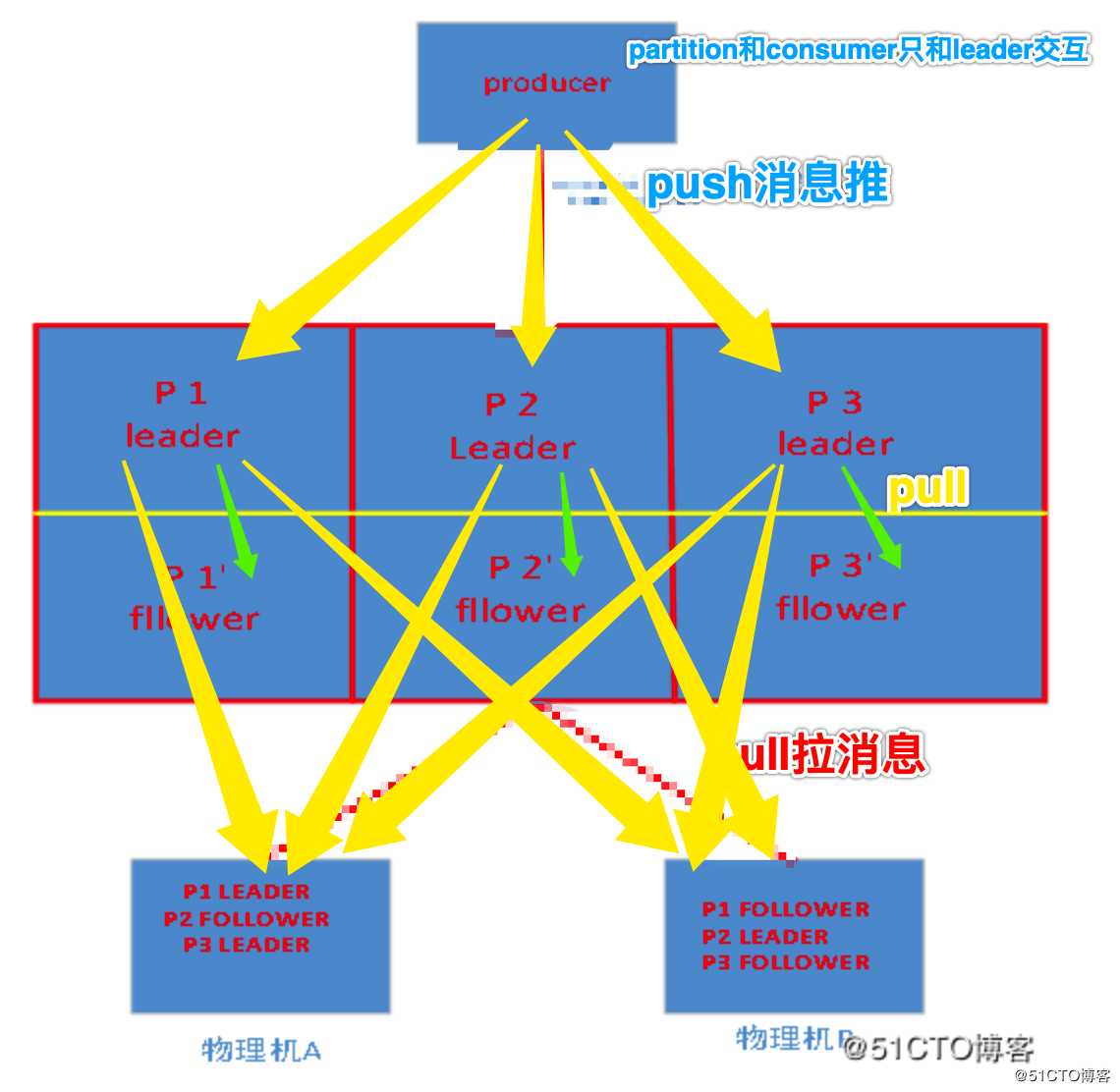
一个 Topic 物理上分为多个 Partition,位于不同的 Broker 上。如果没有 Replica,一旦 Broker 宕机,其上所有的 Patition 将不可用。
每个 Partition 可以有多个Replica(对应server.properties/default.replication.factor),分配到不同的 Broker 上。本人默认习惯为 default.replication.factor=2 也就是默认2个副本,比较合理
其中有一个 Leader 负责读写,处理来自 Producer 和 Consumer 的请求;其他作为 Follower 从 Leader Pull 消息,保持与 Leader 的同步。
如何分配 Partition 和 Replica 到 Broker 上?步骤如下:
1、将所有 Broker(假设共 n 个 Broker)和待分配的 Partition 排序。
2、将第 i 个 Partition 分配到第(i mod n)个 Broker 上。
3、将第 i 个 Partition 的第 j 个 Replica 分配到第((i + j) mode n)个 Broker 上。
根据上面的分配规则,若 Replica 的数量大于 Broker 的数量,必定会有两个相同的 Replica 分配到同一个 Broker 上,产生冗余。因此 Replica 的数量应该小于或等于 Broker 的数量。
//这里kafka硬性规定了创建的replica不能超过broker的数量,必须等于小于broker的数量
这里有2个算法函数解释一下
1、mod:求余函数;
2、mode:返回在某数组或数据区域中出现频率最多的数值,mode是一个位置测量函数。
我这里只有3个broker 创建4个replica就出现报错 具体见下
[root@kafka02-55-12 ~]# kafka-topics.sh --zookeeper 10.211.55.11:2181,10.211.55.12:2181,10.211.55.13:2181/kafkagroup --replication-factor 4 --partitions 9 --create --topic topic-zhuhair
**Error while executing topic command : Replication factor: 4 larger than available brokers: 3.**
[2019-08-24 20:41:40,611] ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 4 larger than available brokers: 3.pratition的leader是如何选举的
参考链接:
架构成长之路:Kafka设计原理看了又忘,忘了又看?一文让你掌握: https://www.toutiao.com/i6714606866355192328/
以上是关于kafka深入研究之路-剖析各原理的主要内容,如果未能解决你的问题,请参考以下文章