(长期更新)python数据建模实战零零散散问题及解决方案梳理
Posted likedata
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(长期更新)python数据建模实战零零散散问题及解决方案梳理相关的知识,希望对你有一定的参考价值。
注1:本文旨在梳理汇总出我们在建模过程中遇到的零碎小问题及解决方案(即当作一份答疑文档),会不定期更新,不断完善, 也欢迎大家提问,我会填写进来。
注2:感谢阅读。为方便您查找想要问题的答案,可以就本页按快捷键Ctrl+F,搜索关键词查找,谢谢。
1. 读写csv文件时,存在新的一列,Unnamed:0?
答:read_csv()时,防止出现,设置参数index_col=0;写入csv文件时,防止出现,设置参数index=False。
2. 日期类型和字符串互转。
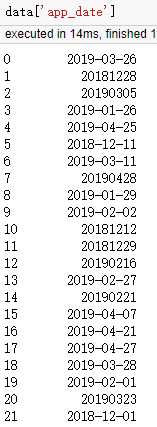
场景:我们从数据库取得的数据往往不是规整的,如存在‘19900807,1992-04-12’格式,且数据类型为str。
答:引入datetime模块。举例如下:
数据如图:
代码如下,即可解决:
1 data[‘app_date‘] = data[‘app_date‘].apply(lambda x: x.replace(‘-‘, ‘‘)) # 20190326,20181228 2 data[‘app_date‘] = data[‘app_date‘].apply(lambda x: datetime.datetime.strptime(x,‘%Y%m%d‘)) # %Y%m%d or %Y-%m-%d的选择,取决于x格式带不带‘-‘ 3 data[‘app_date‘] = data[‘app_date‘].apply(lambda x: x.strftime(‘%y%m‘)) # %y%m: 1903,1812...; %Y%m:201903, 201812...
3. (简写)字符串格式化,两种方式
①%


1 for i in range(3): 2 s = ‘%d‘ %i 3 print(s) # 依次输出 1, 2, 3
②.format()
1 s = ‘等级考试‘ 2 y = ‘-‘ 3 4 print (‘0:1^25‘.format(s, y)) # ----------等级考试-----------
4. 建模时,对于python删除变量的两种小思路
1) 针对dataframe格式的data
data.drop(col, aixs= 1, inplace = True)
#col为想要删除的变量名--列名,方法:DataFrame.drop(self, labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors=‘raise‘)
2) 针对series格式的columns行索引
cols = data.columns cols = cols.drop(col) #有个方法:cols.drop(labels, errors=‘raise‘)
5. 我们在预处理及特征工程阶段会分析各变量属于什么类别,都有哪些呢?
我们接触到的统计学变量(variables)可以分为数值变量(Numerical Variables)和分类变量(Categorical Variables)。
数值变量又可以分为---离散型变量(discrete)、连续型变量(continuous)。
分类变量又可以分为---有序分类变量(ordinal)、无序分类变量(nominal)。
6. python读写文件时模式mode选择的异同(多用于open(‘xx‘)、to_csv(‘xx‘)等地方)
1). r模式
只读模式,该模式下打开的文件如果不存在,将会出错;并且打开后,只能读取,不能写入
2). r+模式
在上述特点上增加一条:可以向文件中写入。
3). w模式
该模式打开的文件如果已经存在,会先清空,如果没有,会新建一个文件,然后只能写入数据,不能读取
4). w+模式
在上述特点上增加一条:可以读取。
5). a模式
该模式打开的文件如果已经存在,不会清空,写入的内容追加到文件尾,但不能读取文件;文件不存在就会新建一个,然后写入。(以追加的方式写入)
6). a+模式
在上述特点上增加一条:可以读取数据。
7). 二进制模式,在上述后面加上b,如‘rb‘,读取二进制文件。
7. 排序取最大(小)值对应的索引,argmin,idxmin,argmax,argmin
numpy分析: numpy 的 ndarray.argmin 的 Series 版
Series分析: argmin=idxmin,argmax=idxmax
DataFrame分析: 没有arg,只有idxmin,idxmax
8. 经常要用到映射方法,apply,applymap,map,定义如下
apply: 使用在DataFrame上,用于对row或者column进行计算; applymap: 用于DataFrame上,是元素级操作(常用); map: 用于series上,是元素级操作。
9. 删除特定列的重复行,drop_duplicates()
DataFrame.drop_duplicates(subset=None, keep=‘first‘, inplace=False)
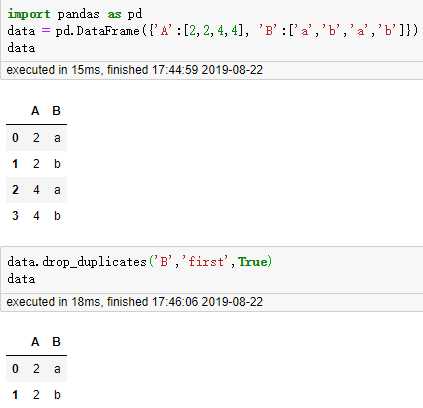
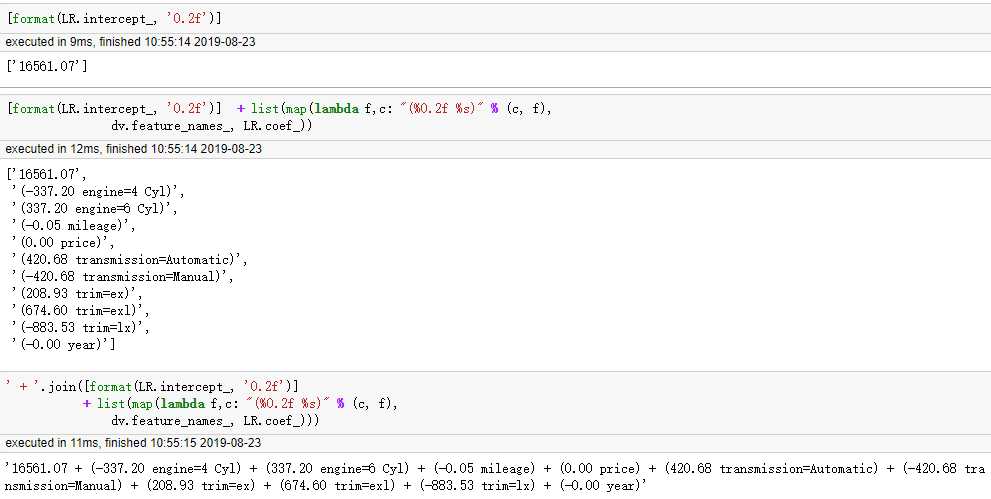
10. 记录一个map,str的join的示例
注:感谢阅读。如果书写风格影响观看体验,还望多多提出来,本人会虚心接受,谢谢
以上是关于(长期更新)python数据建模实战零零散散问题及解决方案梳理的主要内容,如果未能解决你的问题,请参考以下文章