Spark 定制版:016~Spark Streaming源码解读之数据清理内幕彻底解密
Posted zisheng_wang_DATA
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark 定制版:016~Spark Streaming源码解读之数据清理内幕彻底解密相关的知识,希望对你有一定的参考价值。
本讲内容:
a. Spark Streaming数据清理原因和现象
b. Spark Streaming数据清理代码解析
注:本讲内容基于Spark 1.6.1版本(在2016年5月来说是Spark最新版本)讲解。
上节回顾
上一讲中,我们之所以用一节课来讲No Receivers,是因为企业级Spark Streaming应用程序开发中在越来越多的采用No Receivers的方式。No Receiver方式有自己的优势,比如更大的控制的自由度、语义一致性等等。所以对No Receivers方式和Receiver方式都需要进一步研究、思考
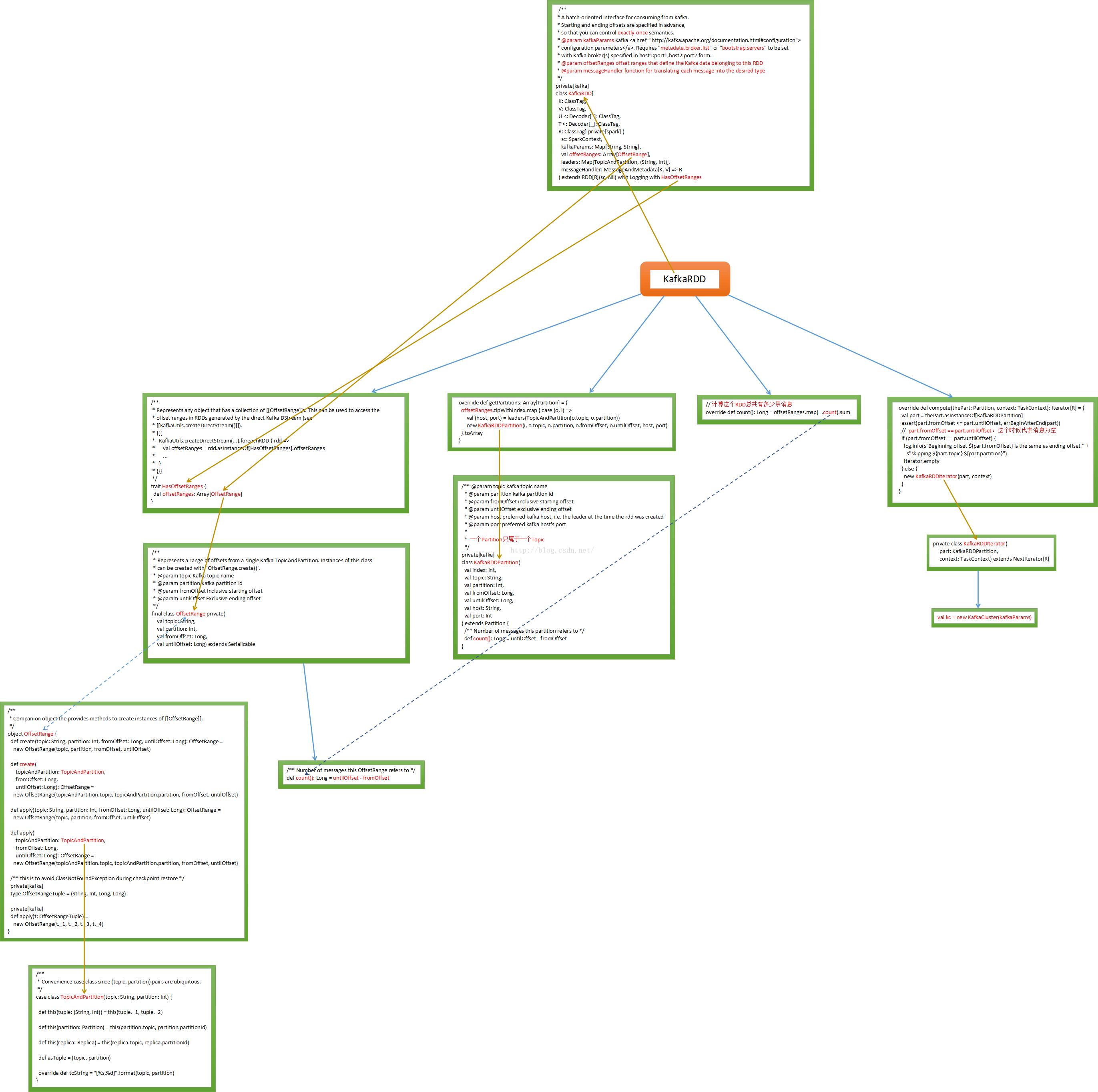
aSpark Streaming现在支持两个方式,一种是Receivers的方式来接收数据的输入或者对数据的控制,另一种是No Receivers的方式,也就是directAPI。其实No Receivers的方式是更符合读取数据和操作数据的思路的,因为Spark是一个计算框架,作为一个计算框架底层会有数据来源,如果用No Receivers的方式直接操作数据来源中的数据,这是更自然的一种方式。如果要操作数据来源肯定要有一个封装器,封装器肯定是RDD类型的,所以SparkStreaming为了封装数据推出了一个自定义的RDD叫KafkaRDD
从Kafka中消费数据的一种实现,首先要确定开始和结束的offset来保证exactly-once。
kafkaParams 中最关键的是metadata.broker.list,这个broker是kafka中的概念。就是SparkStreaming直接去操作kafka集群,offsetRanges指的是哪一片数据是这个RDD的。Kafka传数据的时候会进行编码所以需要Decoder。直接从kafka中读取数据需要自定义一个RDD,如果想从Hbase中直接读数据也需要自定义RDD
最后我们附上代码执行流程图:
(来源:http://blog.csdn.net/hanburgud/article/details/51545691,感谢作者)
开讲
上一讲中我们主要是讲Spark Streaming应用程序开发中采用No Receivers的方式解密
本讲我们要给大家解密park Streaming中数据清理的流程,主要从背景、Spark Streaming数据是如何清理的、源码解析三个方面给大家逐一展开
背景
Spark Streaming数据清理的工作无论是在实际开发中,还是自己动手实践中都是会面临的,Spark Streaming中Batch Durations中会不断的产生RDD,这样会不断的有内存对象生成,其中包含元数据和数据本身。由此Spark Streaming本身会有一套产生元数据以及数据的清理机制
Spark Streaming数据是如何清理的?
a. 操作DStream的时候会产生元数据,所以要解决RDD的数据清理工作就一定要从DStream入手。因为DStream是RDD的模板,DStream之间有依赖关系。
DStream的操作产生了RDD,接收数据也靠DStream,数据的输入,数据的计算,输出整个生命周期都是由DStream构建的。由此,DStream负责RDD的整个生命周期。因此研究的入口的是DStream
b. 基于Kafka数据来源,通过Direct的方式访问Kafka,DStream随着时间的进行,会不断的在自己的内存数据结构中维护一个HashMap,HashMap维护的就是时间窗口,以及时间窗口下的RDD.按照Batch Duration来存储RDD以及删除RDD
c. Spark Streaming本身是一直在运行的,在自己计算的时候会不断的产生RDD,例如每秒Batch Duration都会产生RDD,除此之外可能还有累加器,广播变量。由于不断的产生这些对象,因此Spark Streaming有自己的一套对象,元数据以及数据的清理机制
d. Spark运行在jvm上,jvm会产生对象,jvm需要对对象进行回收工作,如果我们不管理gc(对象产生和回收),jvm很快耗尽。现在研究的是Spark Streaming的Spark GC。Spark Streaming对rdd的数据管理、元数据管理相当jvm对gc管理。 数据、元数据是操作DStream时产生的,数据、元数据的回收则需要研究DStream的产生和回收
源码解析
看下DStream的继承结构
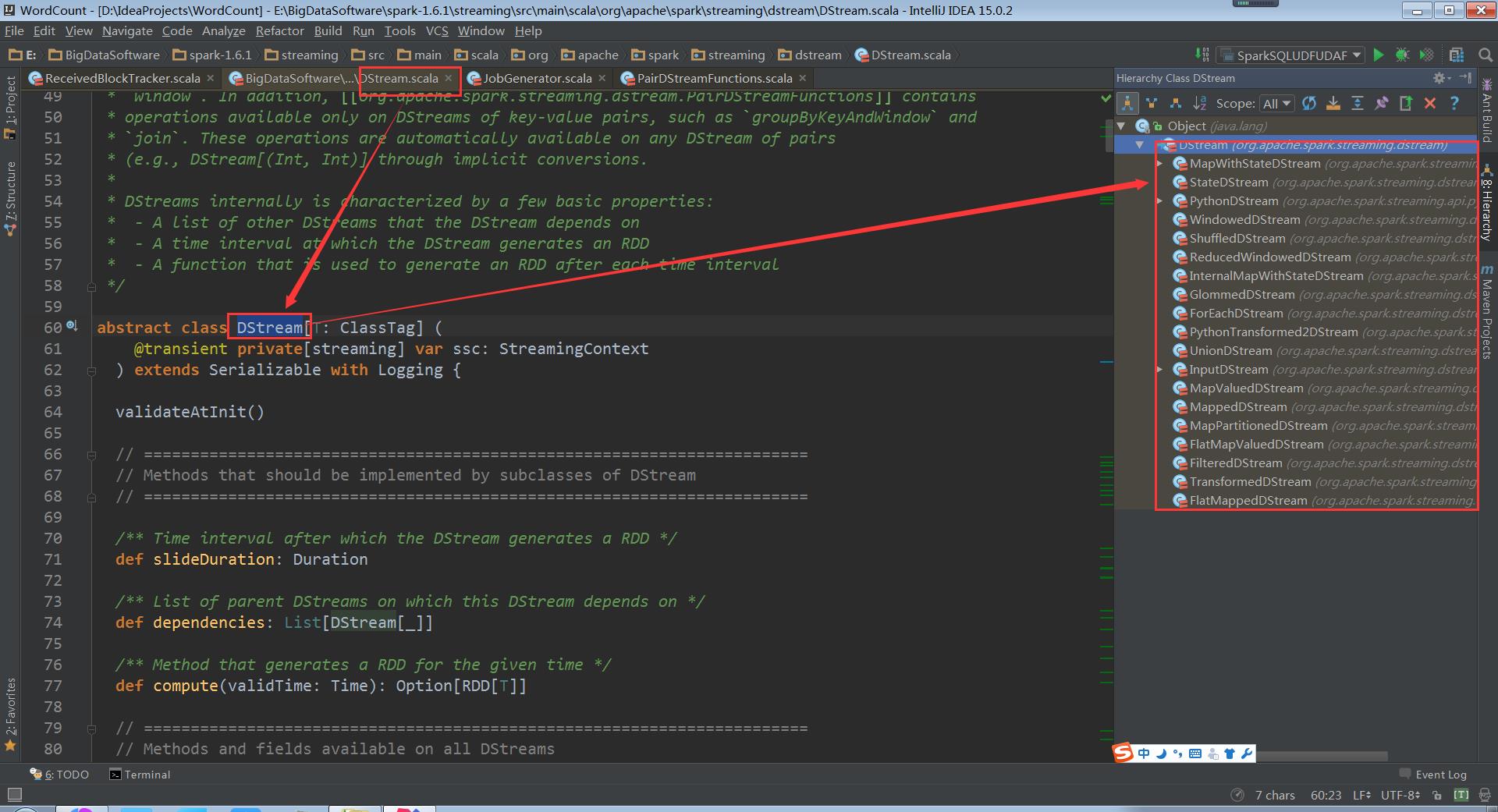
接收数据靠InputDStream,数据输入、数据操作、数据输出,整个生命周期都是基于DStream构建的;得出结论:DStream负责rdd的生命周期,rrd是DStream产生的,对rdd的操作也是对DStream的操作,所以不断产生batchDuration的循环,所以研究对rdd的操作也就是研究对DStream的操作
generatedRDDs安照Batch Duration的方式来存储RDD以及删除RDD
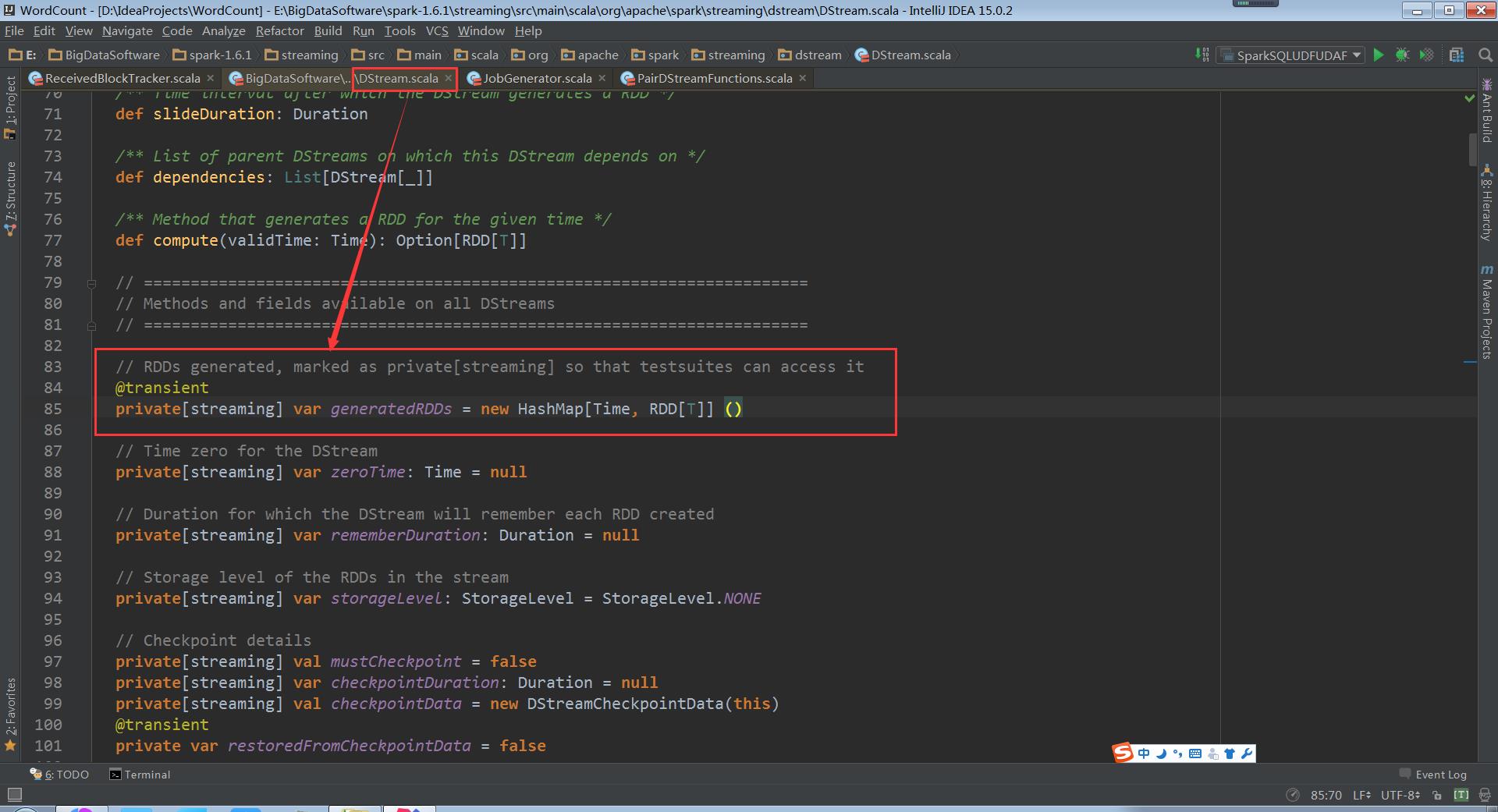
我们在实际开发中,可能手动缓存,即使不缓存的话,它在内存generatorRDD中也有对象,如何释放他们?不仅仅是RDD本身,也包括数据源(数据来源)和元数据(metada),因此释放RDD的时候这三方面都需要考虑
释放跟时钟Click有关系,因为数据是周期性产生,所以肯定是周期性释放
因此下一步就需要找JobGenerator
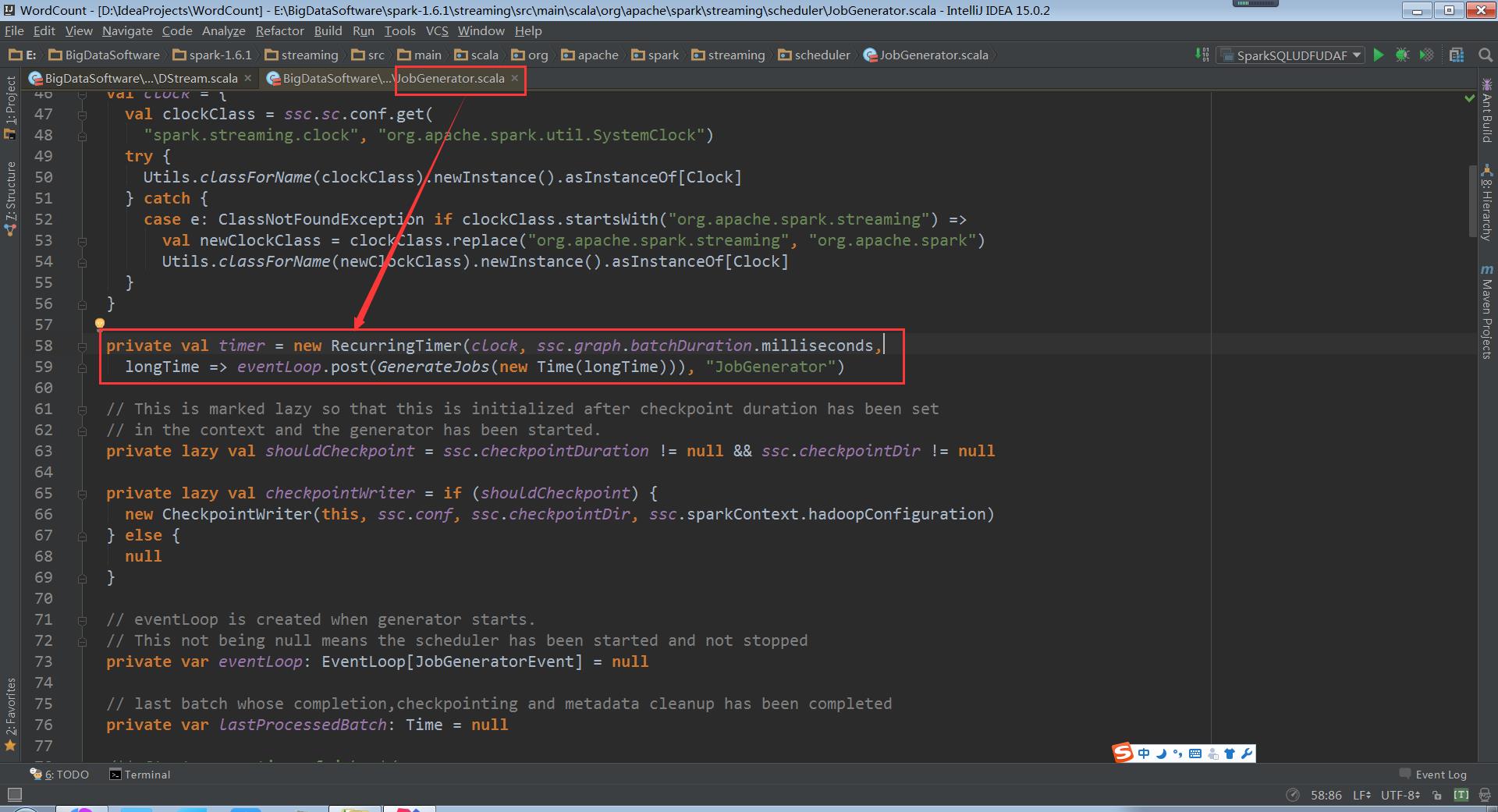
走进JobGenerator中
RecurringTimer消息循环器将消息不断的发送给EventLoop
eventLoop:onReceive接收到消息
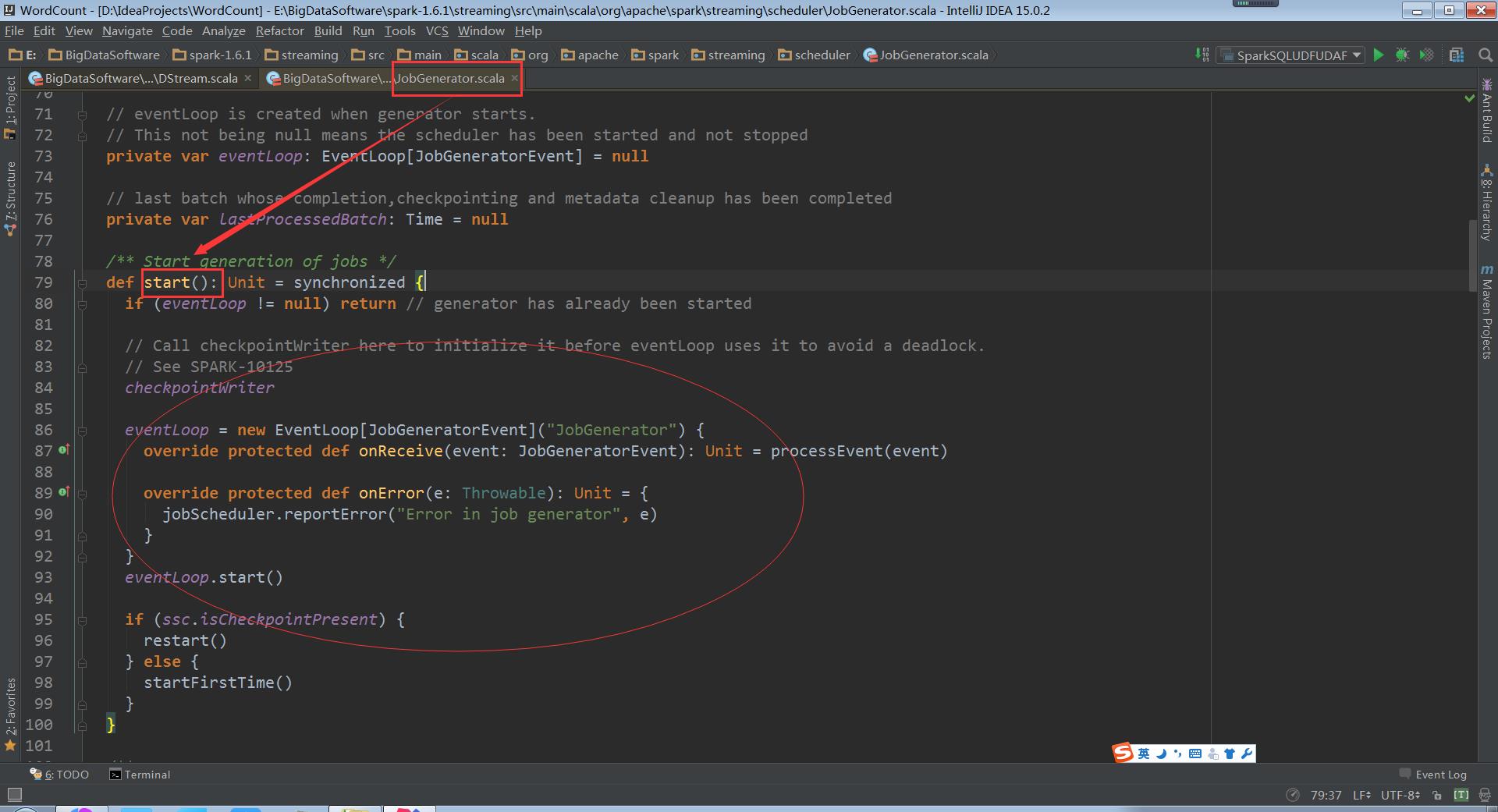
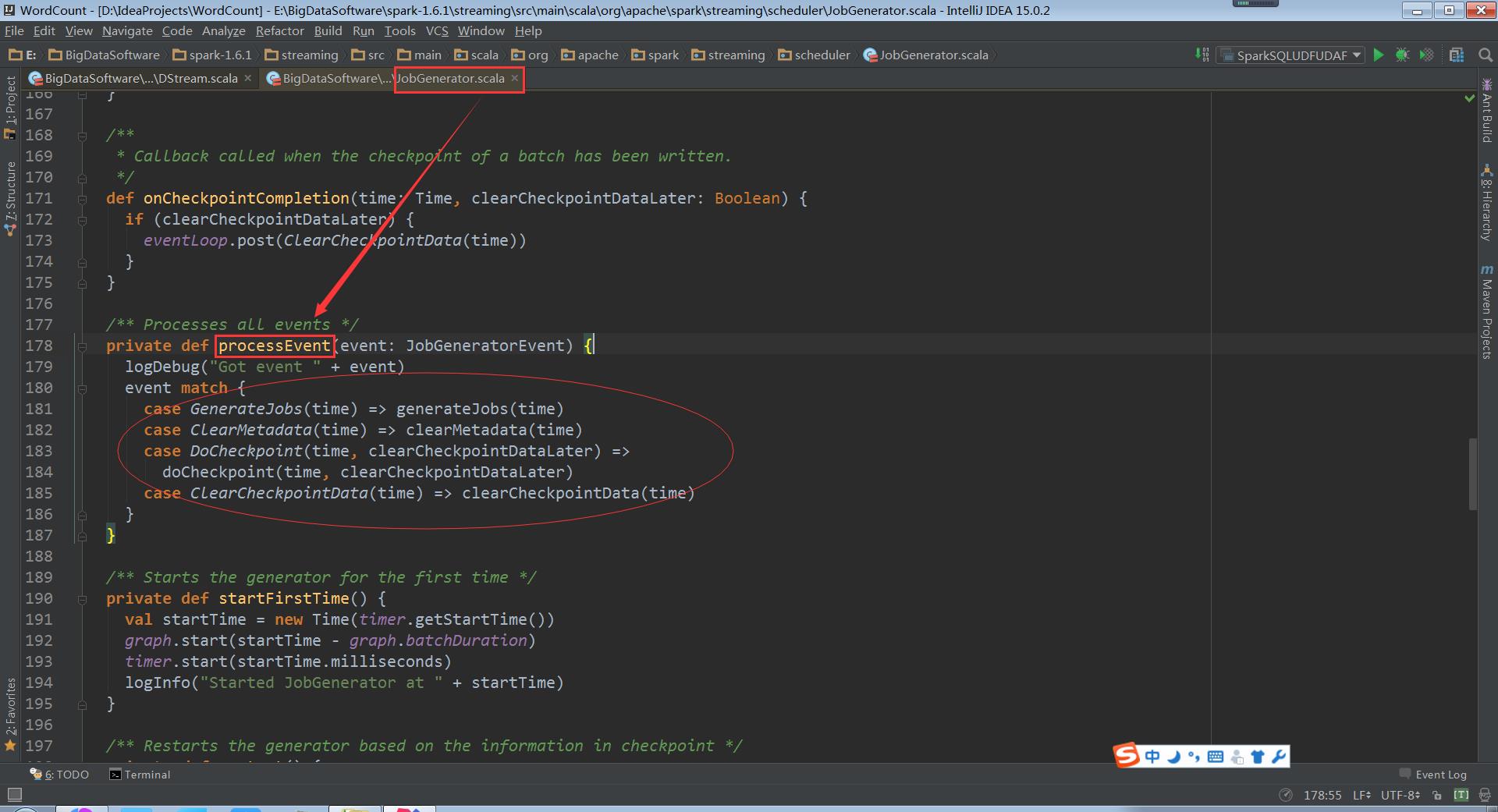
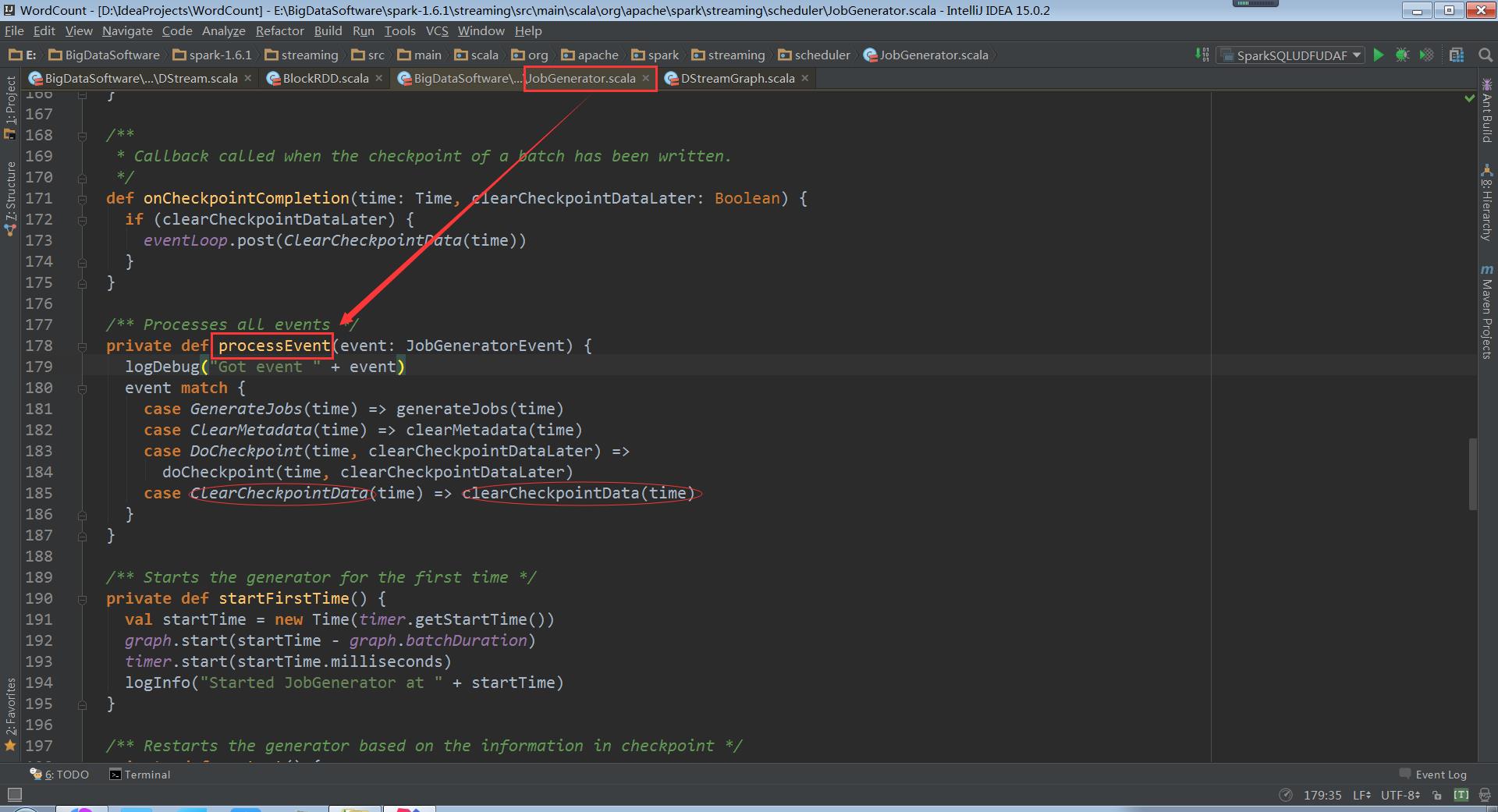
processEvent中就会接收到ClearMetadata和ClearCheckpointData
clearMetadata清楚元数据信息
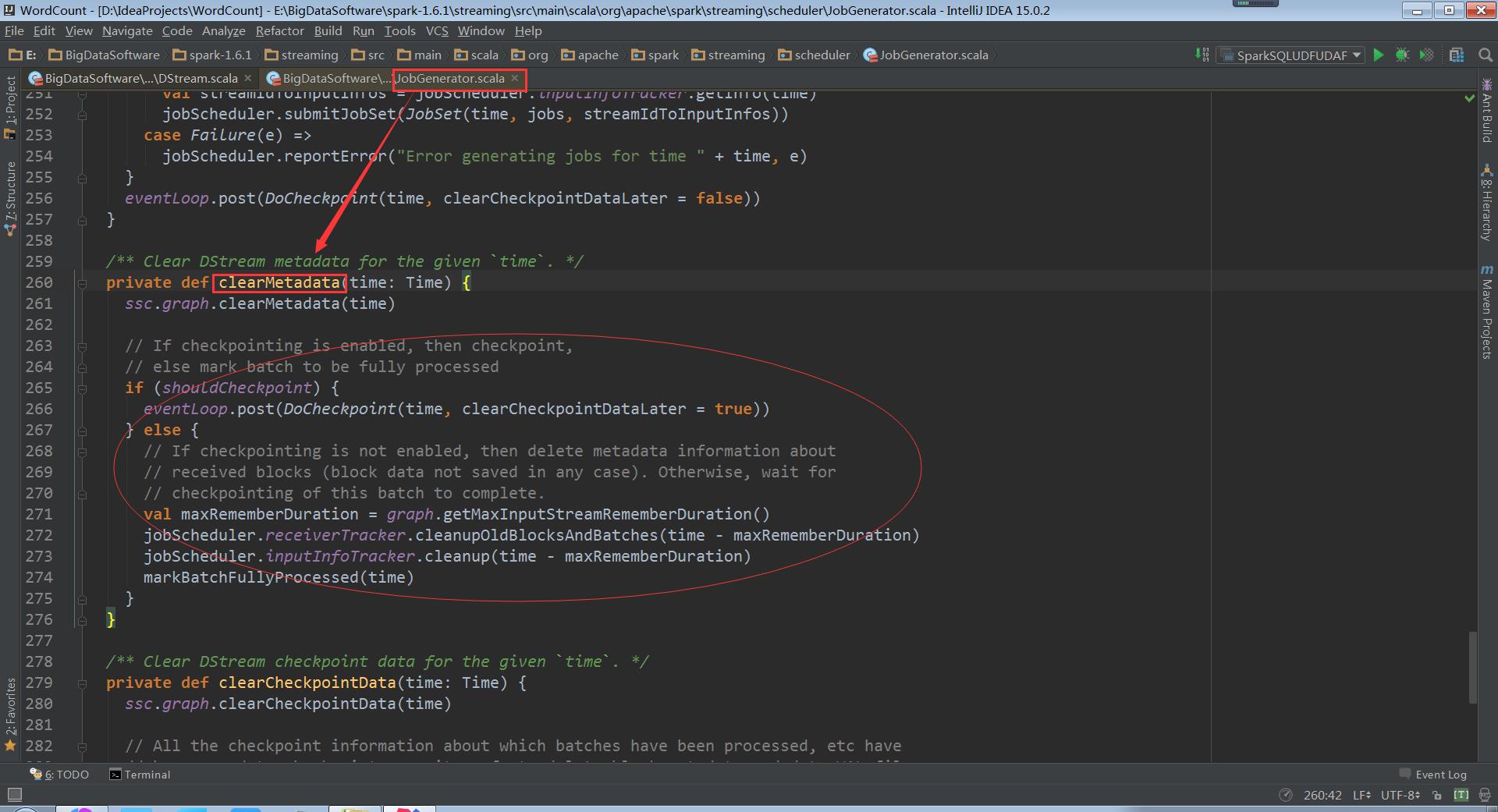
走进DStreamGraph
DStreamGraph首先会清理outputDStream,其实就是forEachDStream
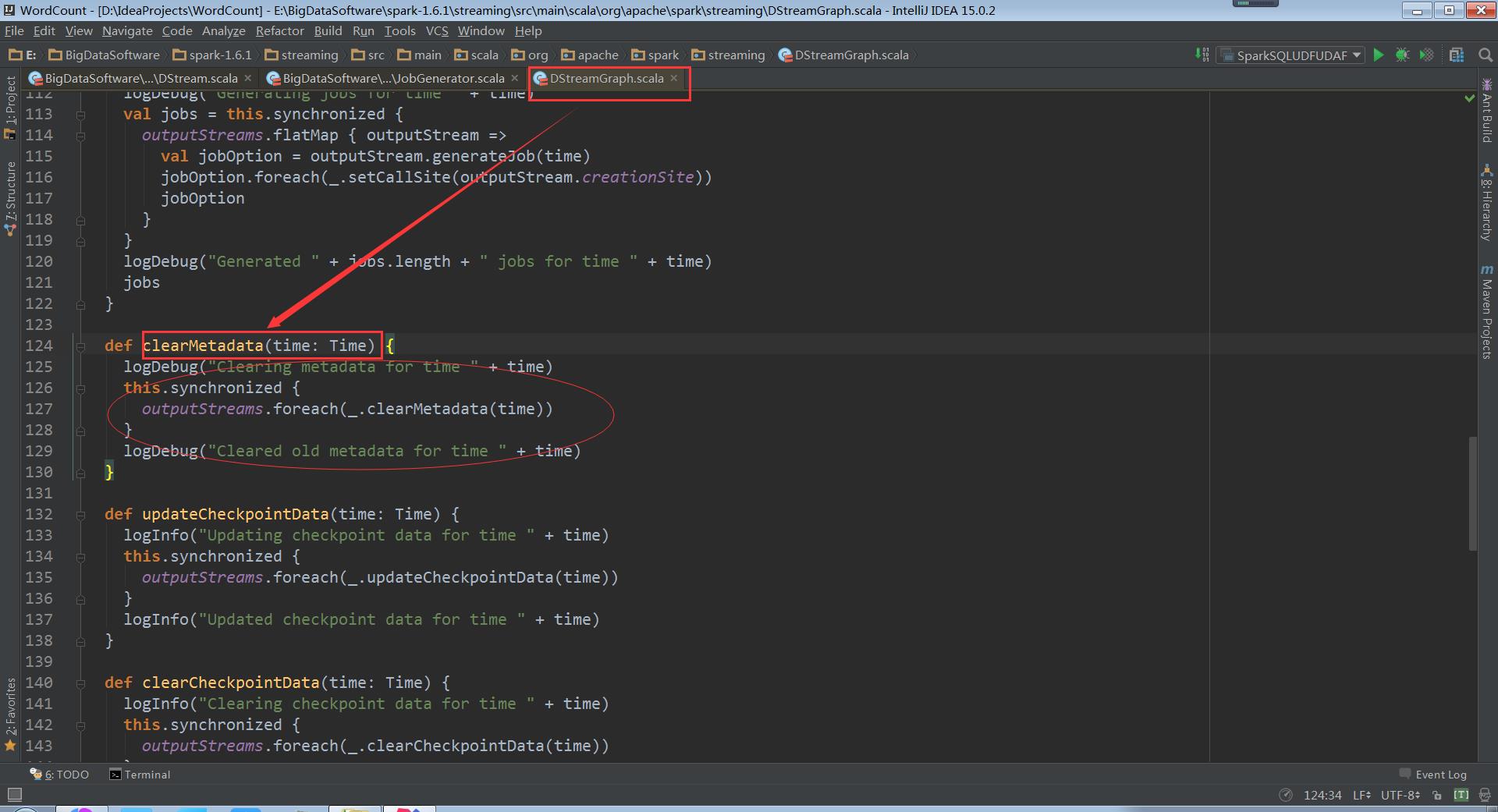
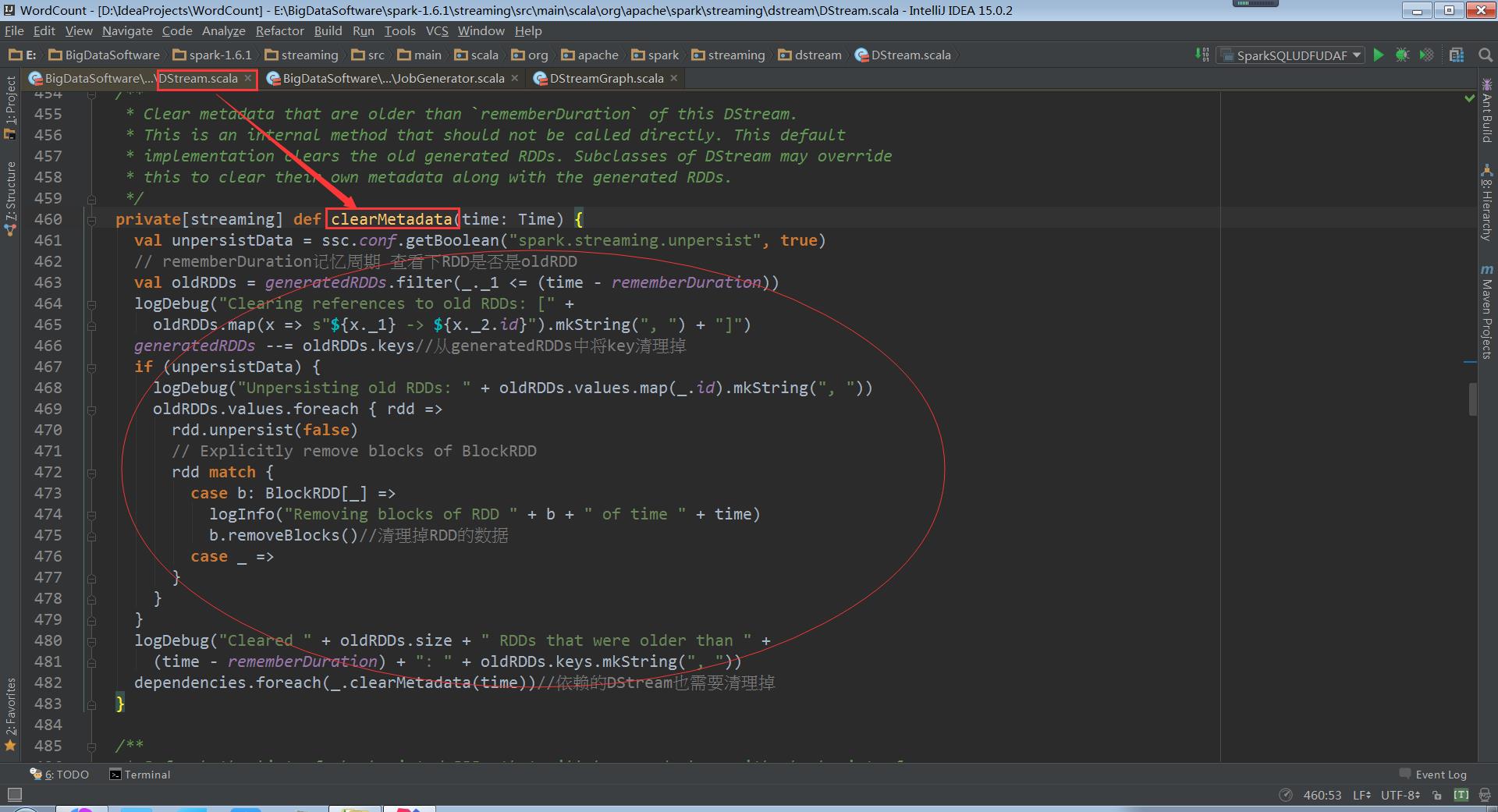
走进DStream
DStream.clearMetadata:除了清除RDD,也可以清除metadata元数据。如果想RDD跨Batch Duration的话可以设置rememberDuration时间
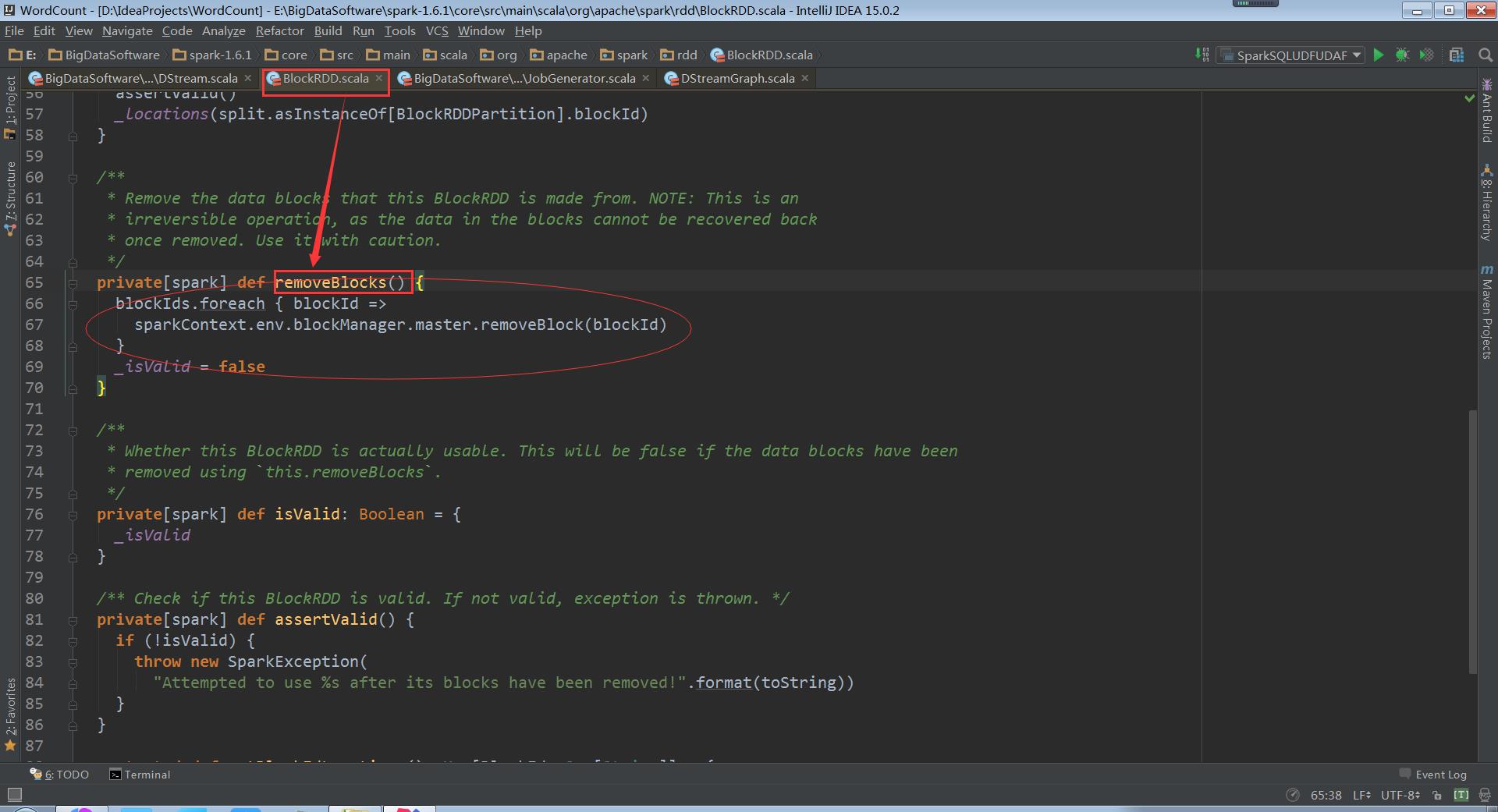
走进BlockRDD
在BlockRDD中removeBlocks方法里,blockManagerMaster根据blockId将Block删除。删除Block的操作是不可逆的
我们再次回到上面JobGenerator中的processEvent
clearCheckpointData清除缓存数据
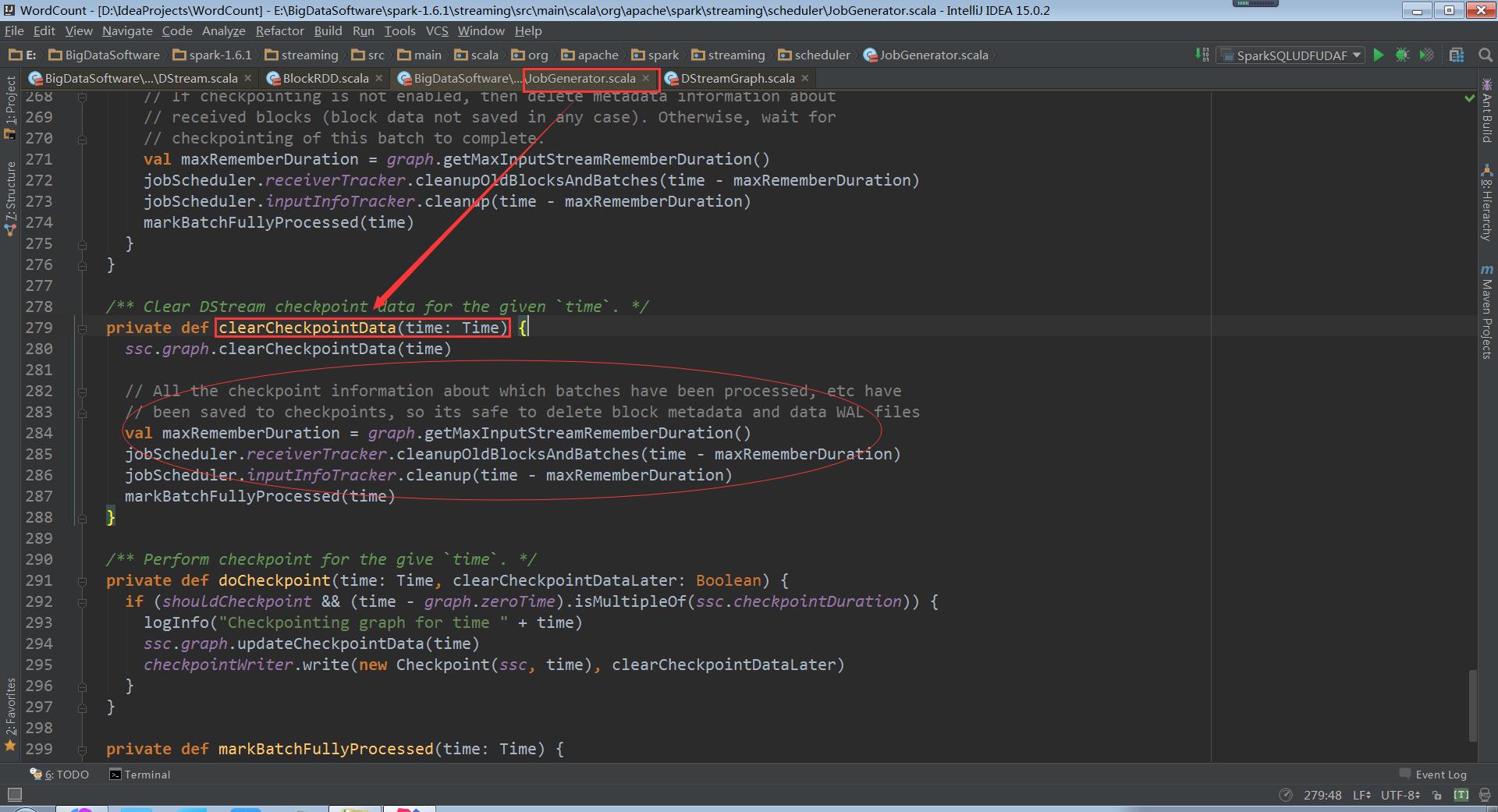
继续跟踪上面 的clearCheckpointData,走进DStreamGraph
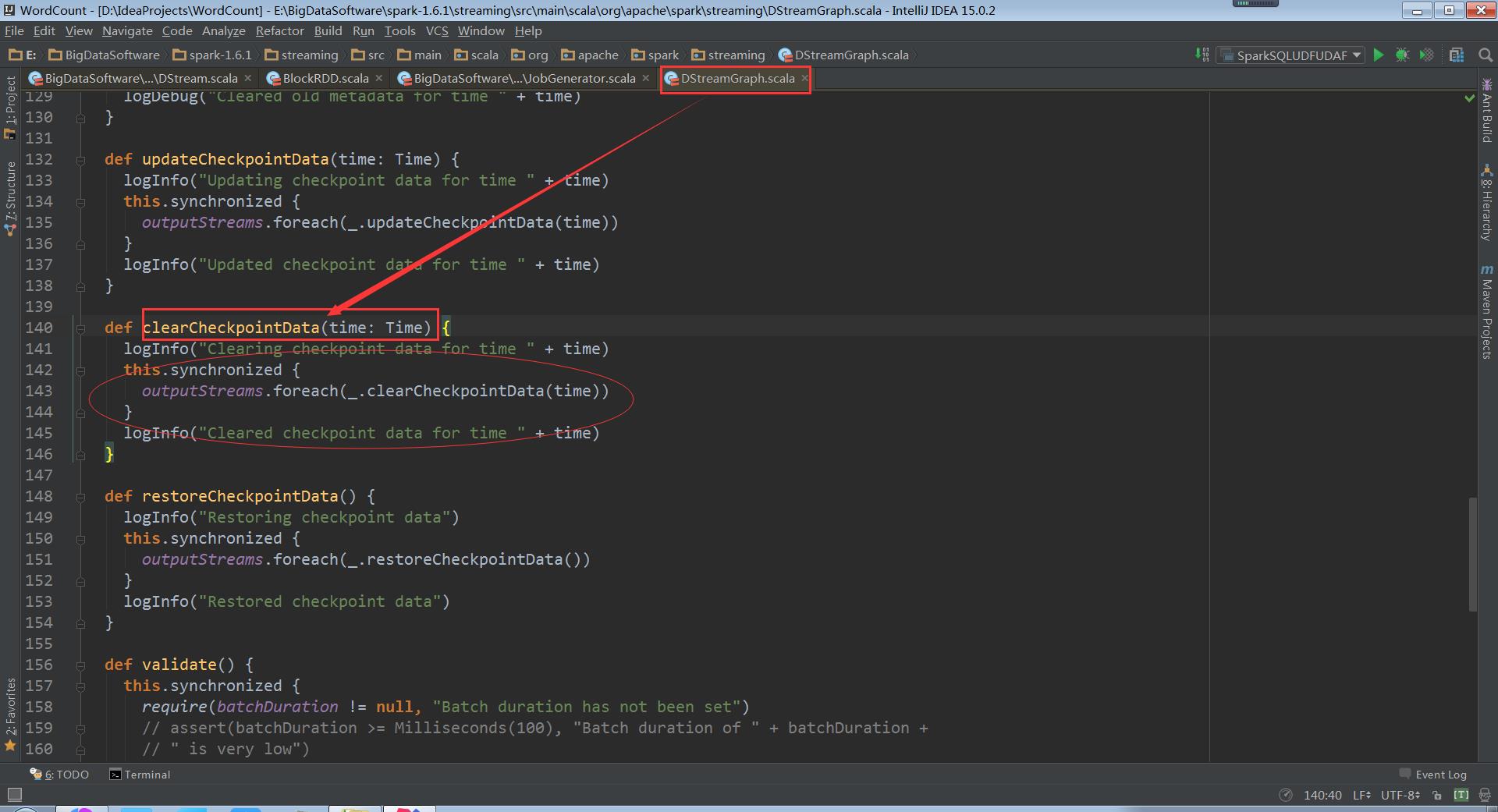
继续跟踪上面 的ClearCheckpointData,和清除元数据信息一样,还是清除DStream依赖的缓存数据
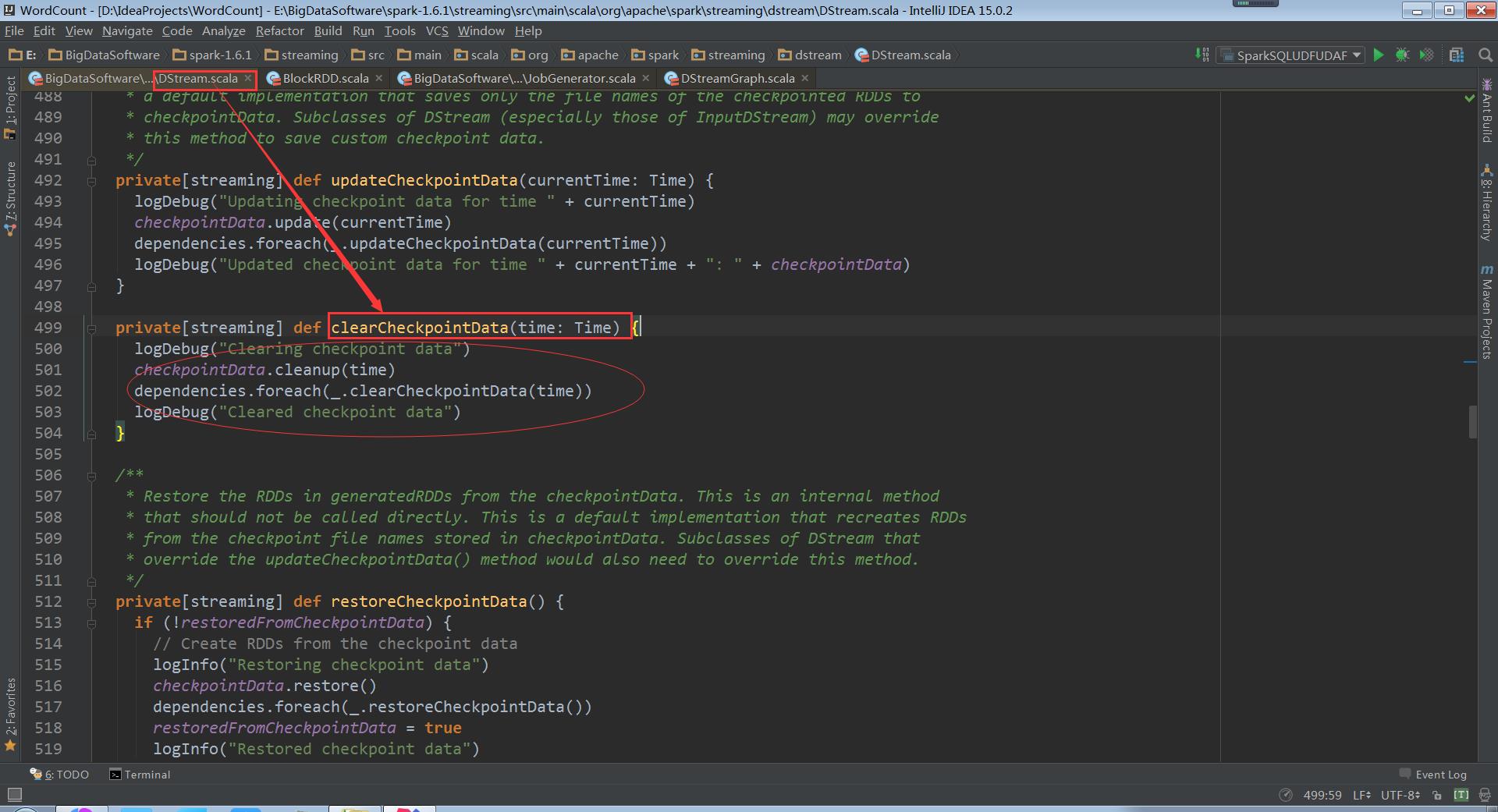
走进DStreamCheckpointData
cleanup清除缓存的数据
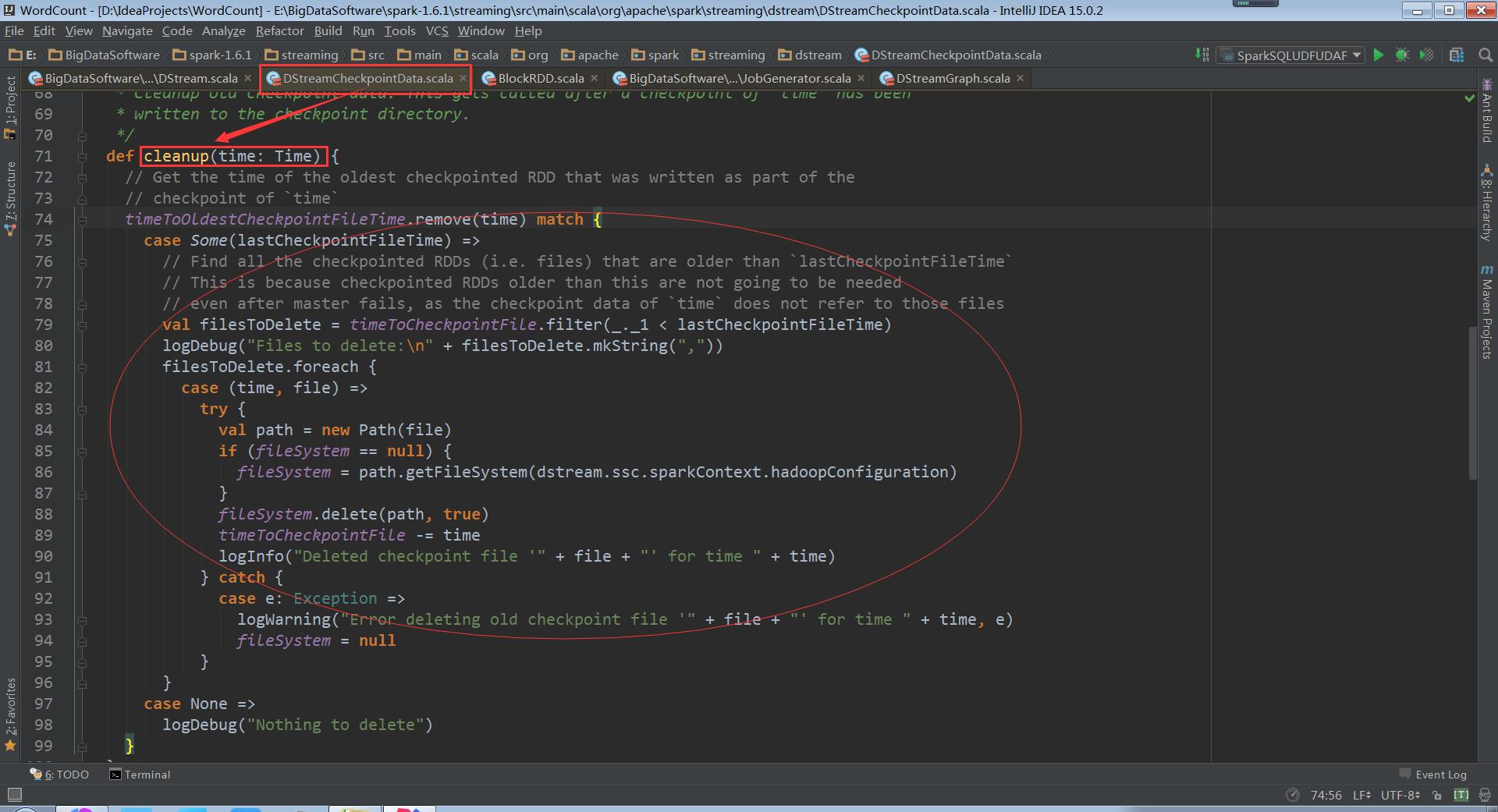
至此数据清理的过程就一幕了然了,但是这个清理是什么时候被触发的?
其实在最终提交Job的时候,是交给JobHandler去执行的
走进JobScheduler
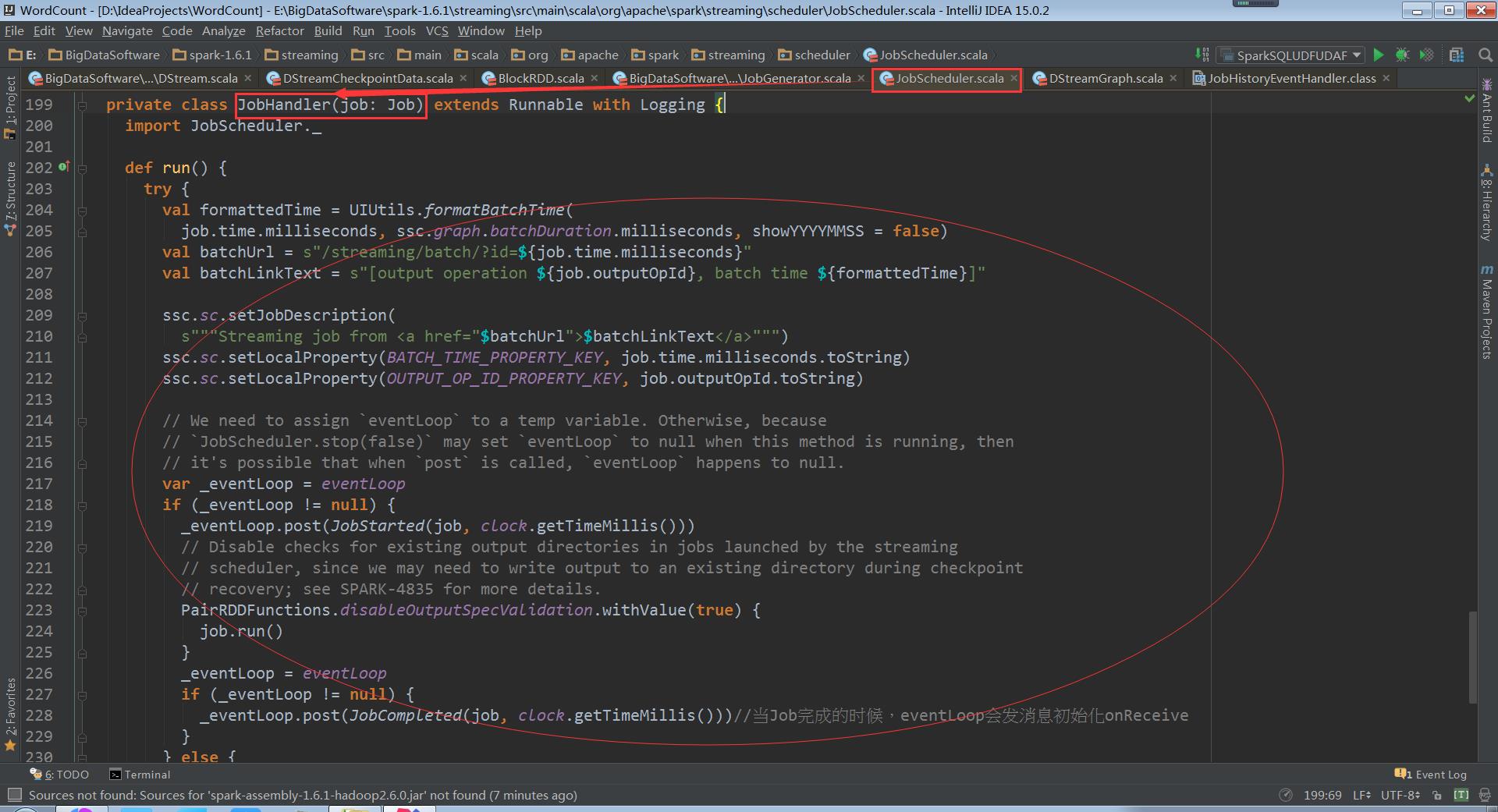
OnReceive初始化接收到消息JobCompleted
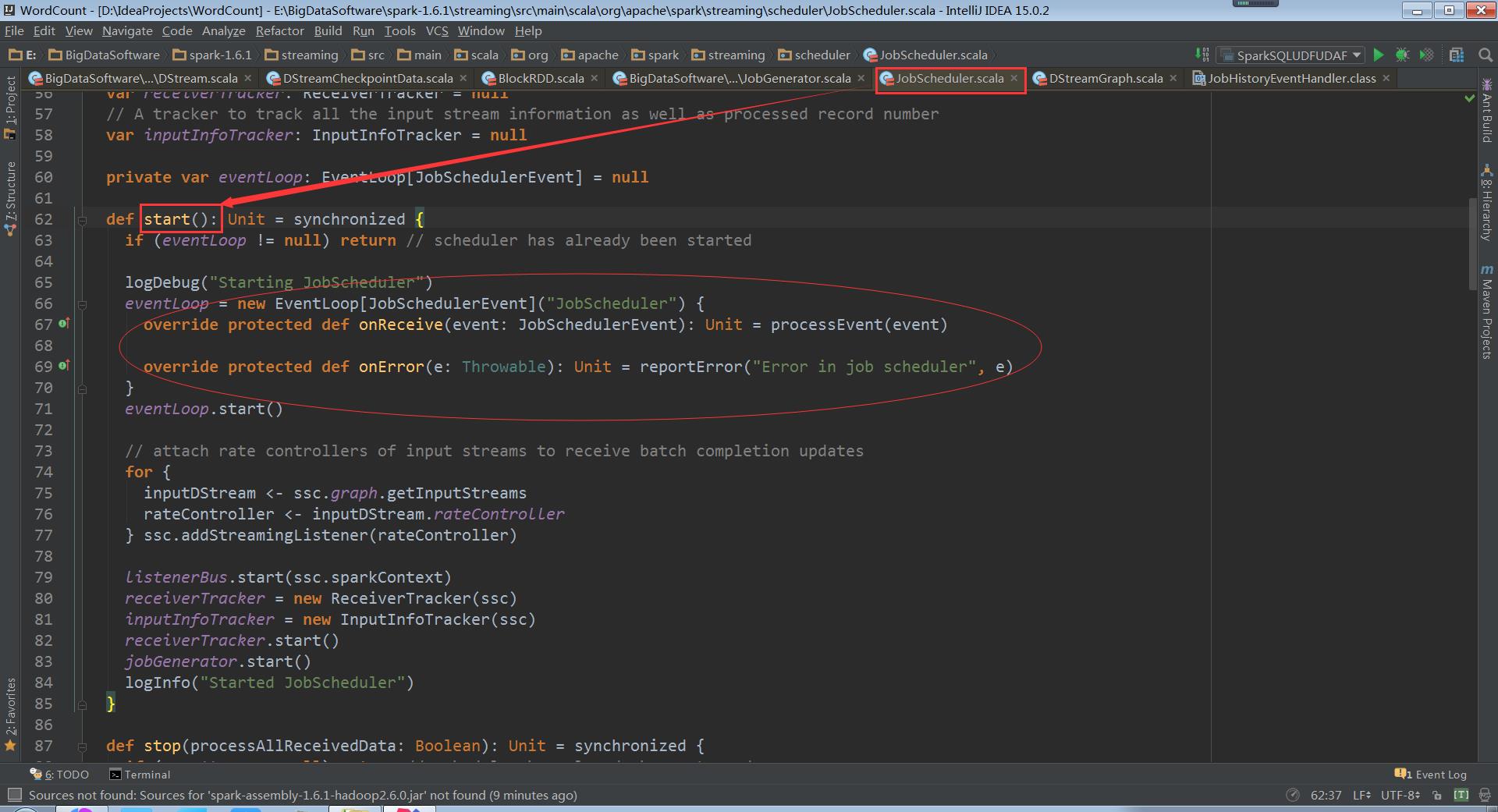
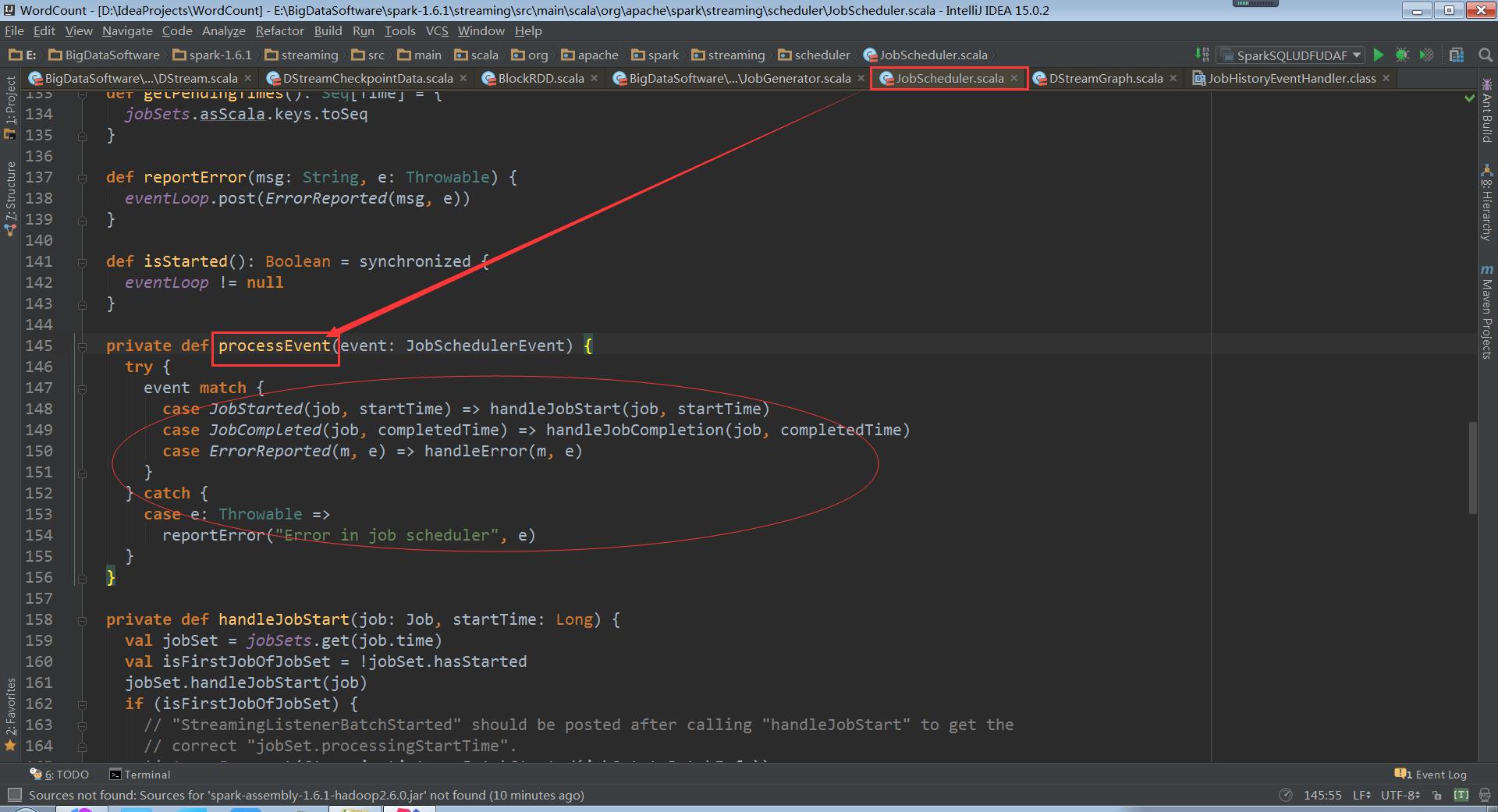
processEvent
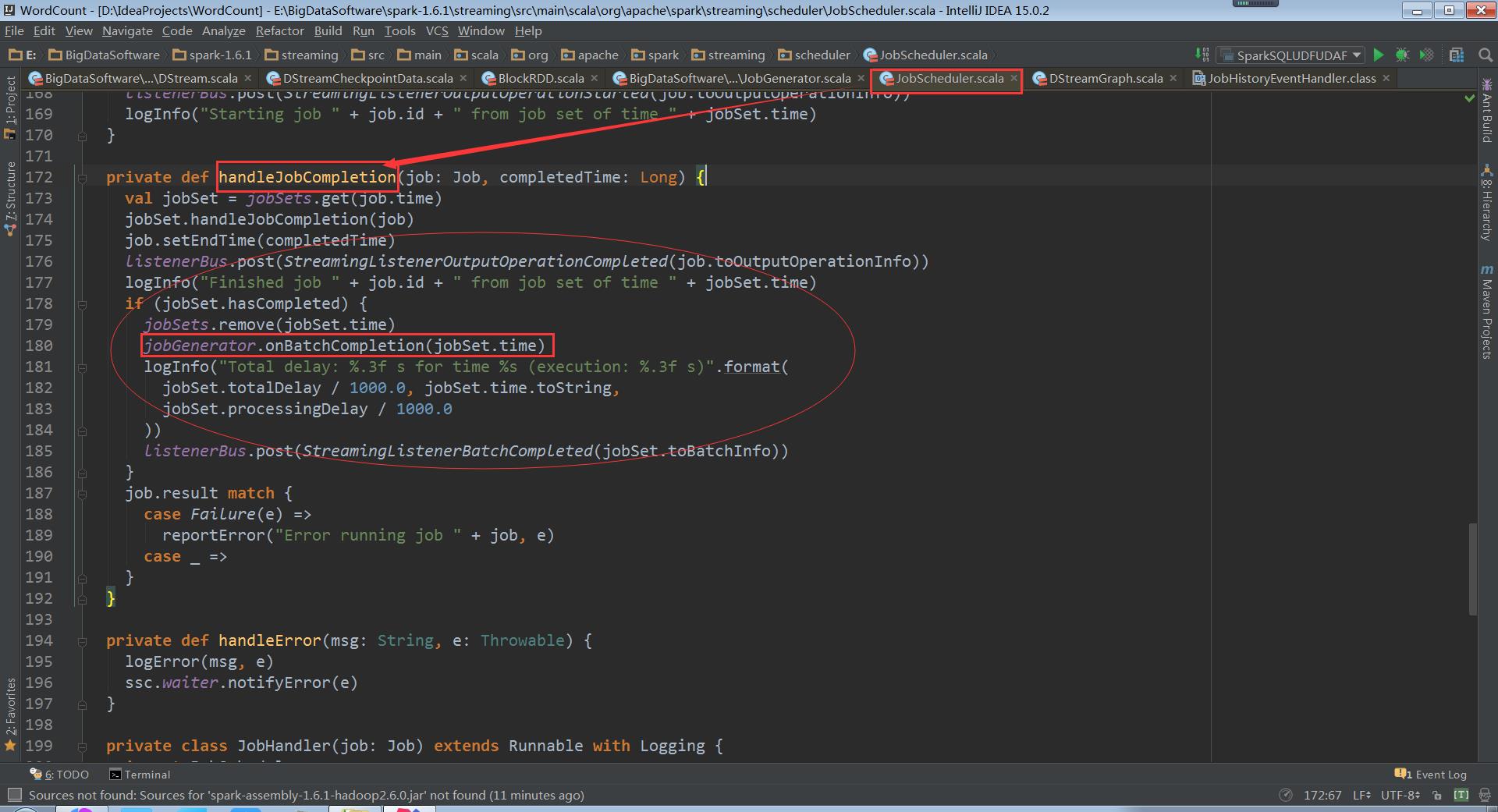
调用JobGenerator的onBatchCompletion方法清楚元数据
以上是关于Spark 定制版:016~Spark Streaming源码解读之数据清理内幕彻底解密的主要内容,如果未能解决你的问题,请参考以下文章
Spark 定制版:008~Spark Streaming源码解读之RDD生成全生命周期彻底研究和思考
Spark 定制版:009~Spark Streaming源码解读之Receiver在Driver的精妙实现全生命周期彻底研究和思考
Py4JJavaError:调用 o45.load 时出错。 :java.lang.NoClassDefFoundError:org/apache/spark/sql/sources/v2/Strea