python风4
Posted sunyongchao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python风4相关的知识,希望对你有一定的参考价值。
1.匿名函数
匿名函数就是一行函数;
匿名函数的名字叫做lambda;
lambda <==> def 关键字
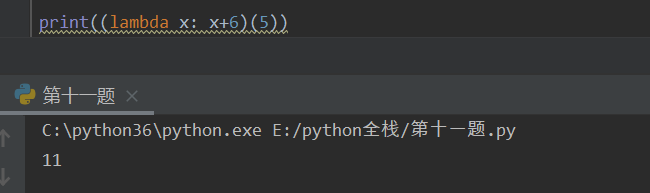
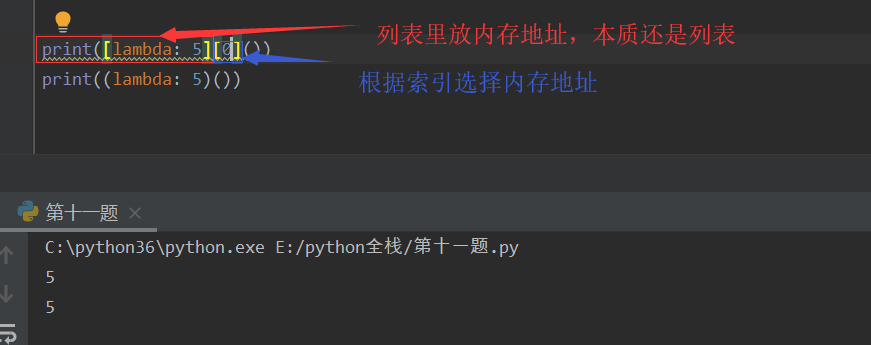
格式:lambda x:x+1
x:冒号前x,是普通函数的形参,可以不接收参数(x可以不写)
:x -- 冒号后x,是普通函数的返回值(只能返回一个数据类型)(x必须写)
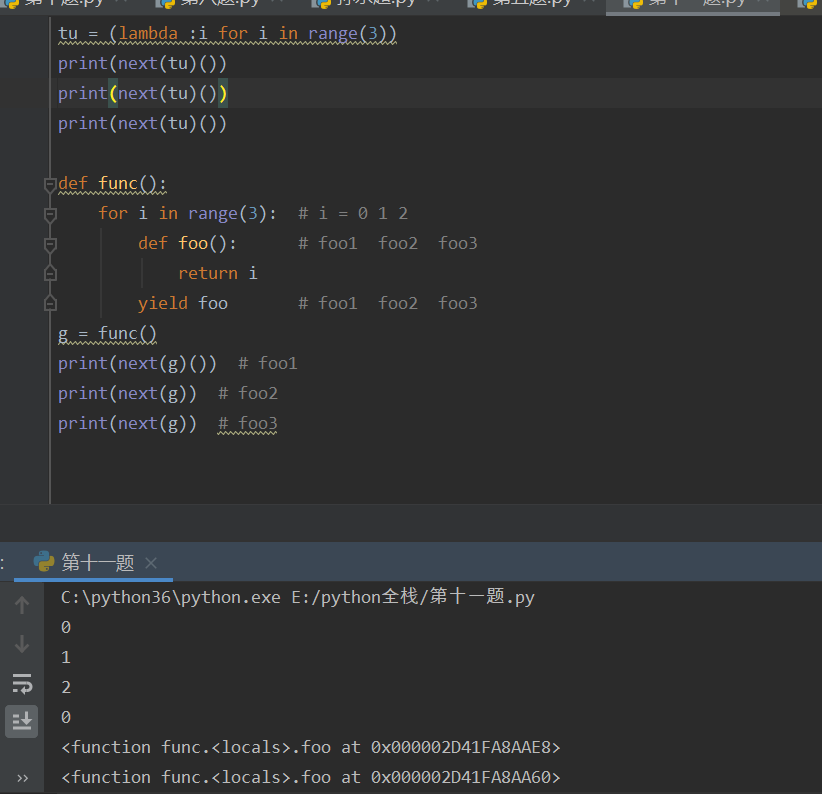
函数体中存放的是代码
生成器体中存放的也是代码
就是yield导致函数和生成器的执行结果不统一
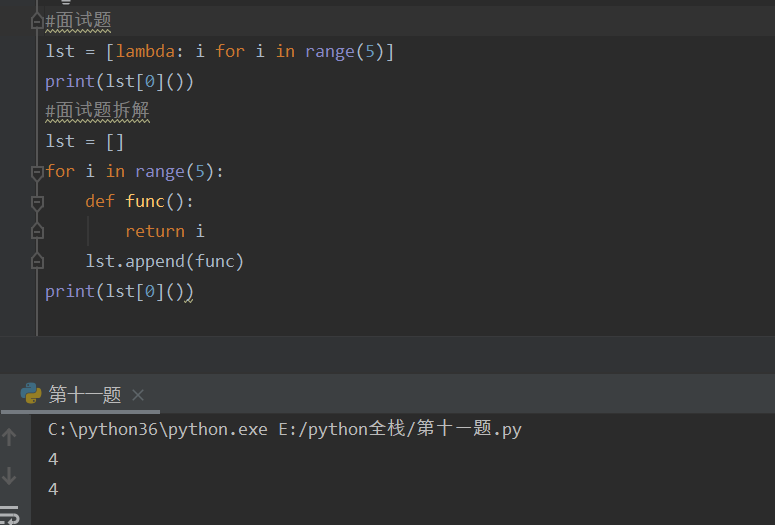
匿名函数拆解:
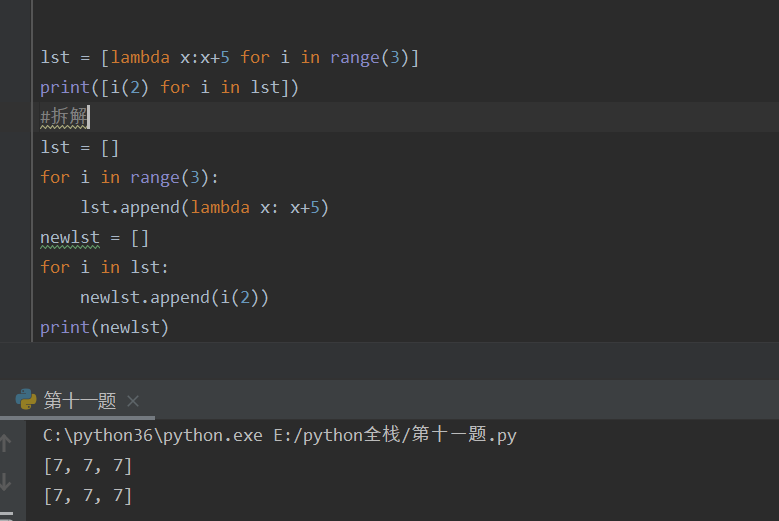
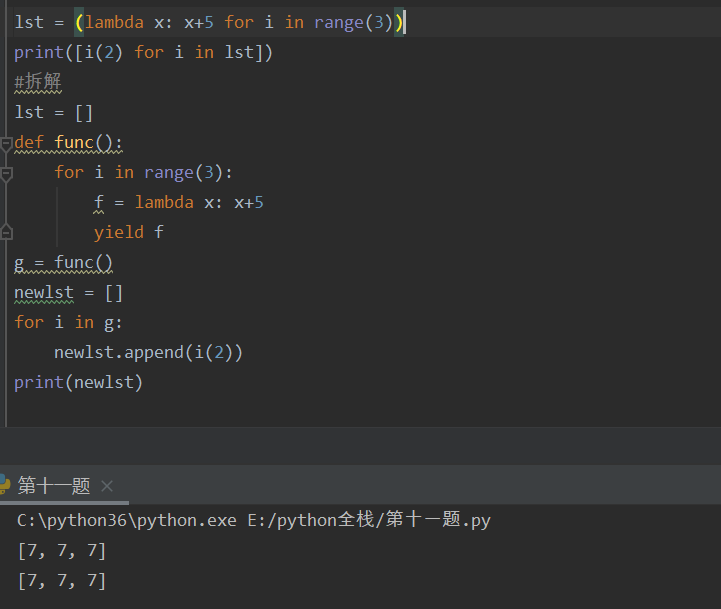
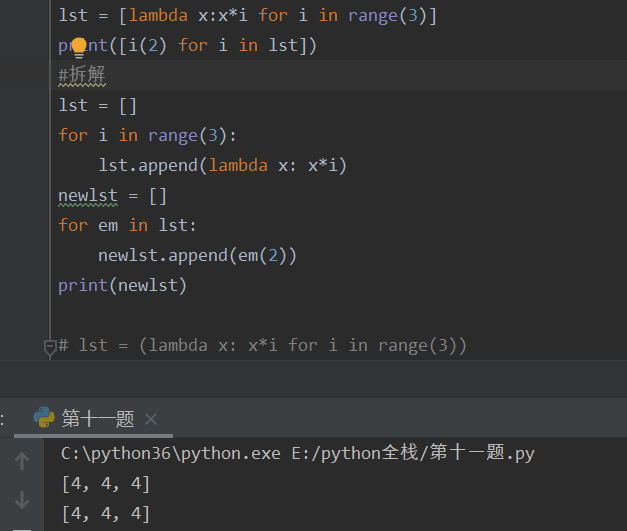
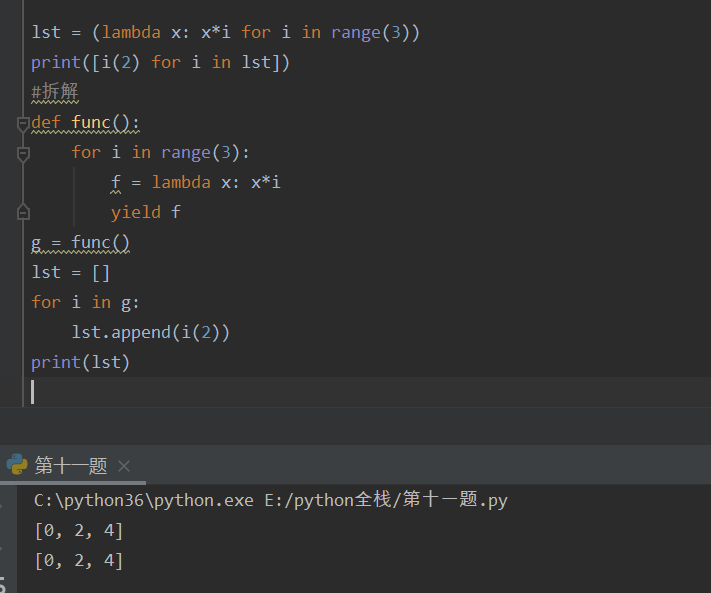2.内置函数
字典定义的两种方法:
print(dict([(1,2),(3,4)]))
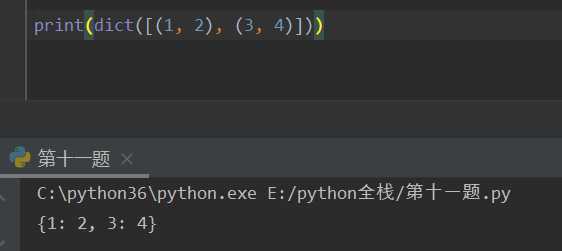
print(dict(k=1, v=2, c=3))
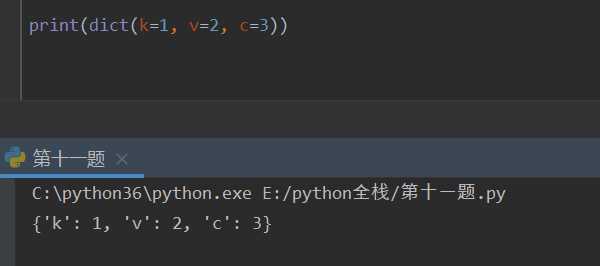
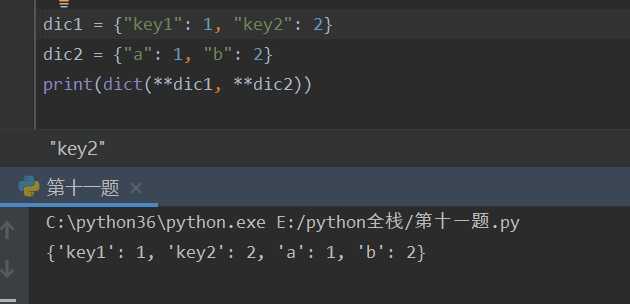
合并字典的方法:
两个字典的键必须是字符串
print() 屏幕输出
sep -- 每个元素之间分隔的方法,默认为空格
end -- print执行完后的结束语句,默认换行符\\n
file -- 文件句柄,默认显示到屏幕
flush -- 刷新
sum() --求和
sum([1,2,2,1]) -- 必须是可迭代对象,可迭代对象中的元素必须为整型
sum([1,2,3],100) -- 100 为指定起始位置的值
abs() -- 绝对值
dir() -- 查看当前对象的所有方法,返回的是列表
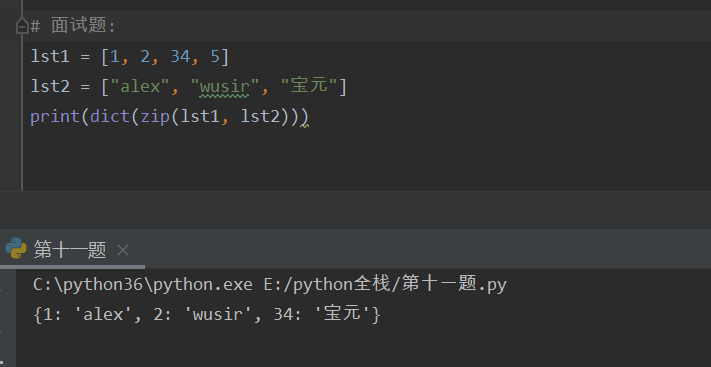
zip -- 拉链方法 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的内容,如果各个可迭代对象的元素个数不一致,则按照长度最短的返回
format -- 格式转换
print(format("alex",">20")) # 右对齐
print(format("alex","<20")) # 左对齐
print(format("alex","^20")) # 居中
print(format(10,"b")) # bin 二进制
print(format(10,"08b")) 八位
print(format(10,"08o")) # oct 八进制
print(format(10,"08x")) # hex 十六进制
print(format(0b1010,"d")) # digit 十进制
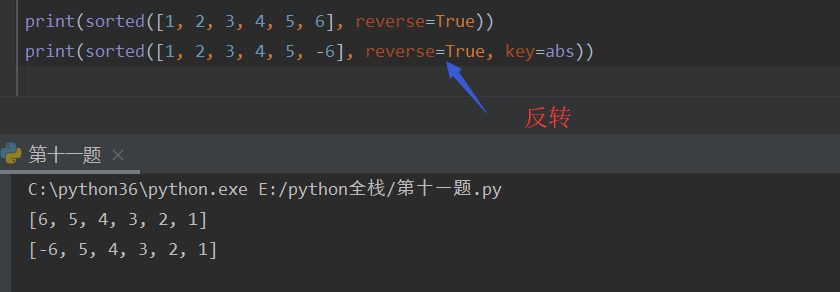
reversed -- 反转
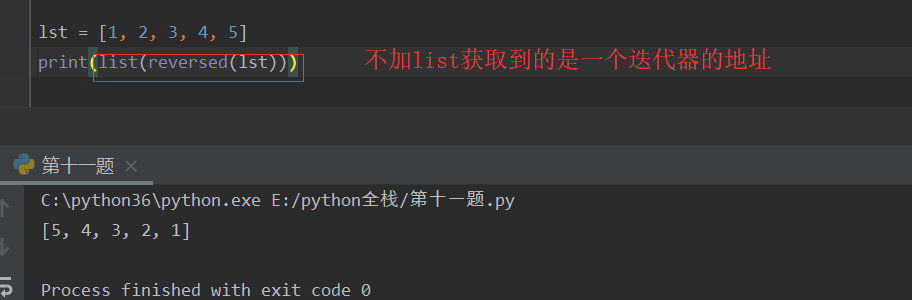
高阶函数
所有的高阶函数在内部都进行了for循环
filter -- 过滤
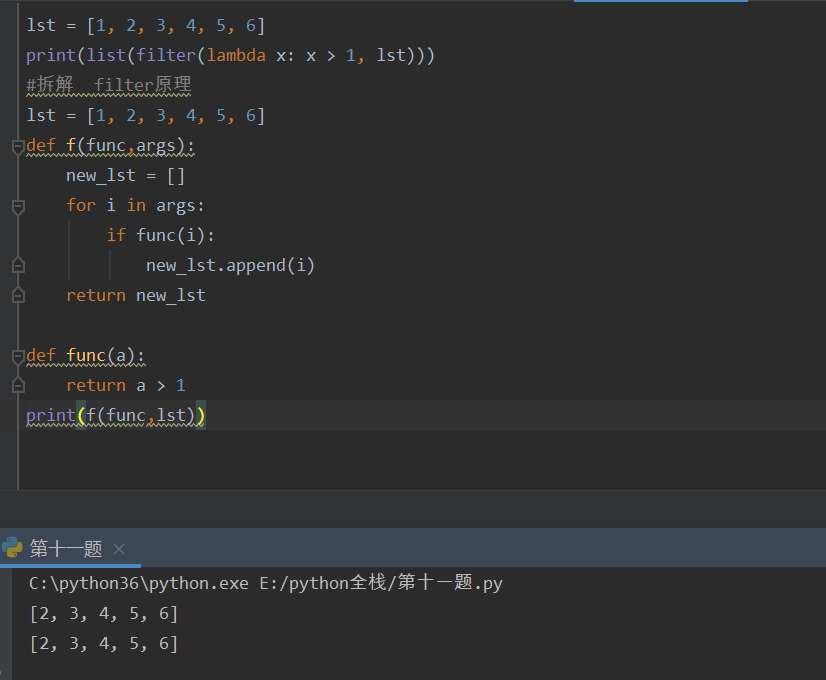
print(list(filter(lambda x:x>2,[1,2,3,4,5])))
1,指定过滤规则(函数名[函数的内存地址]) 2,要过滤的数据
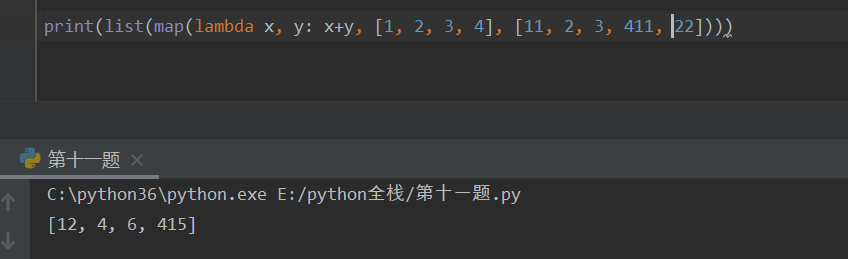
map -- 映射函数 (将可迭代对象中的每个元素执行指定的函数)
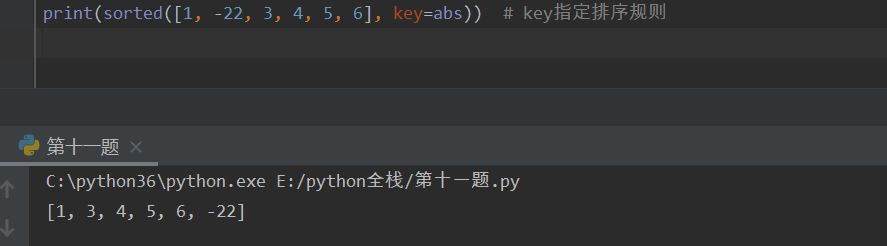
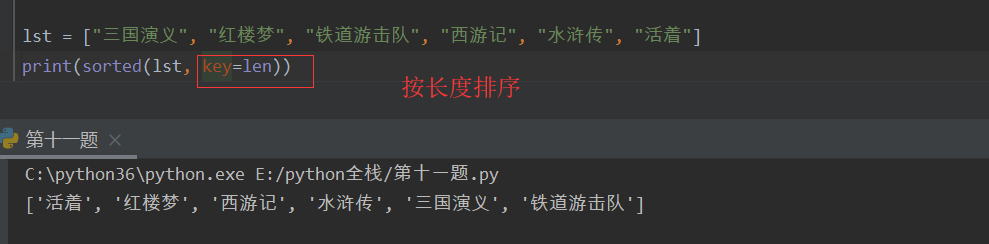
sorted -- 排序函数
max() -- 最大值
min() -- 最小值
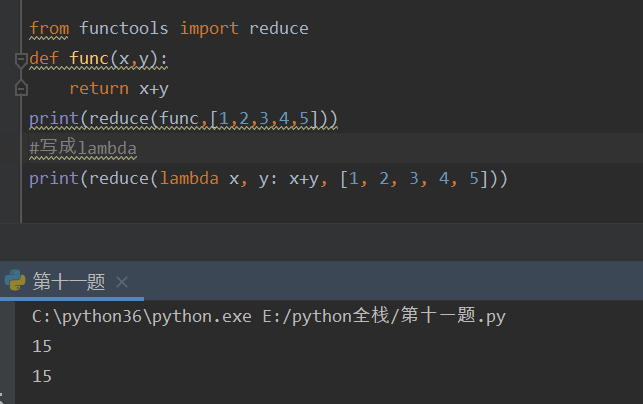
reduce -- 累计算
from functools import reduce
3.闭包
在嵌套函数中,使用非本层且非全局变量的就是闭包
print(inner.__closure__) 判断是否是闭包 返回None就不是闭包
闭包作用:
1.保护数据安全性
2.装饰器
4.装饰器
开放封闭原则
对扩展代码开放
对修改源代码及调用方式封闭
在不修改源代码及调用方式,对功能进行额外添加就是装饰器
start_time = time.time() -- 时间戳
第一版装饰器
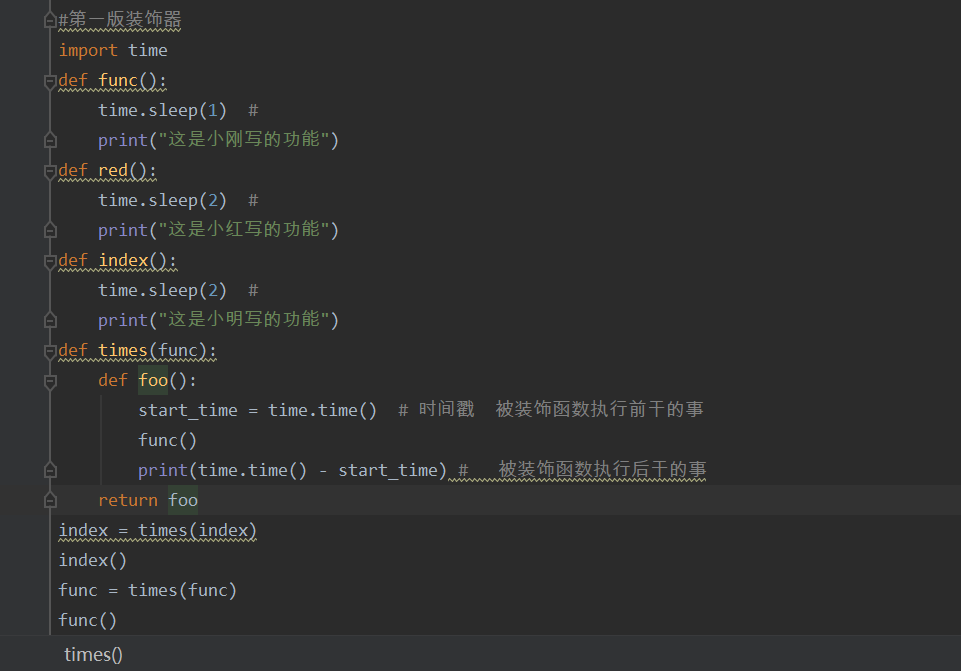
语法糖
python帮咱们做的一个东西,语法糖
要将语法糖放在被装饰的函数正上方
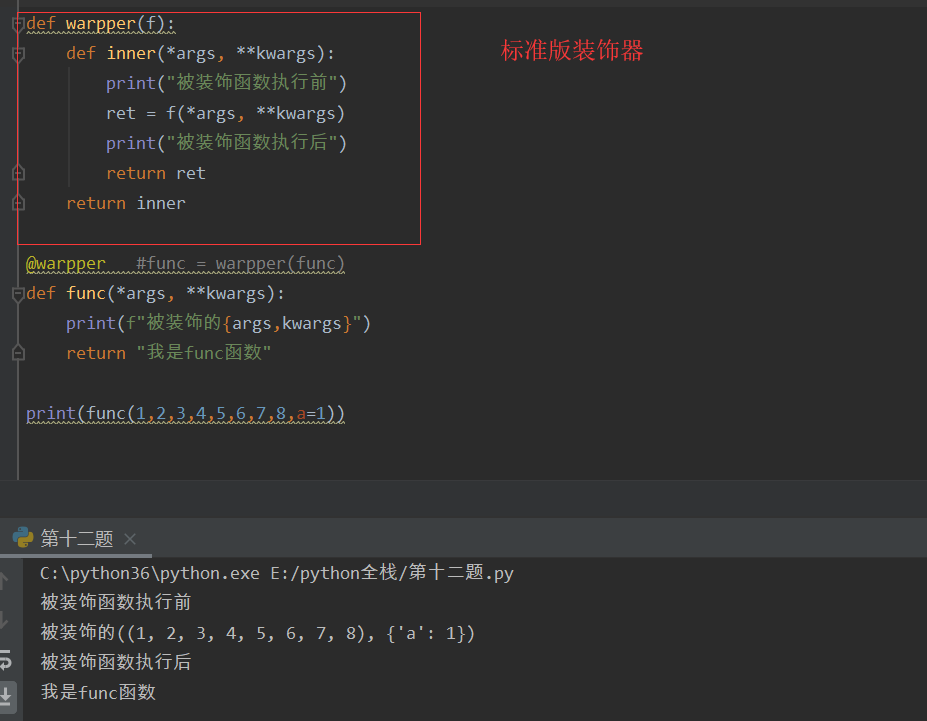
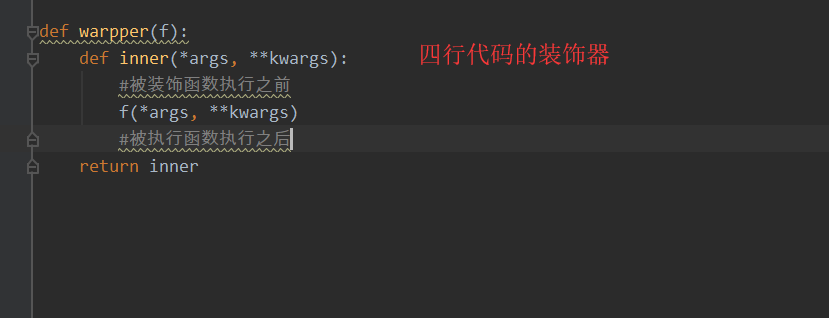
不带语法糖的装饰器
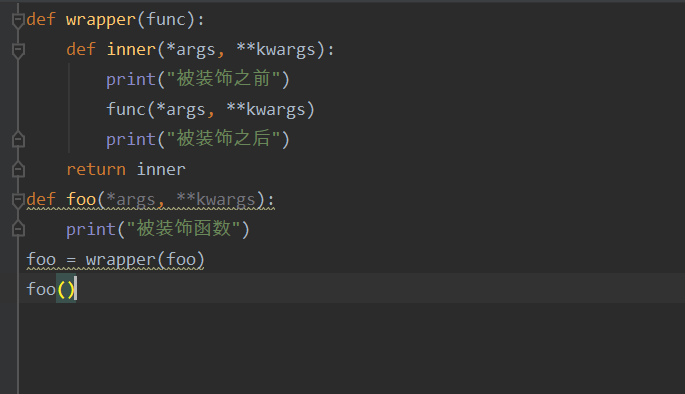5.装饰器进阶
有参数装饰器
有参: 在标准装饰器的外层,套了一层,多套一层就需要额外的调用一层
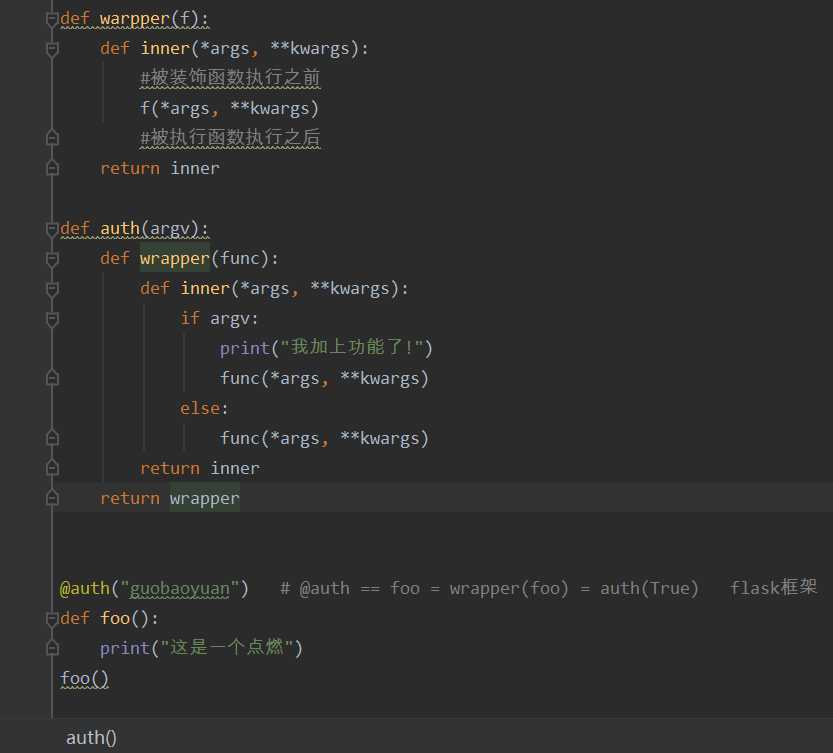
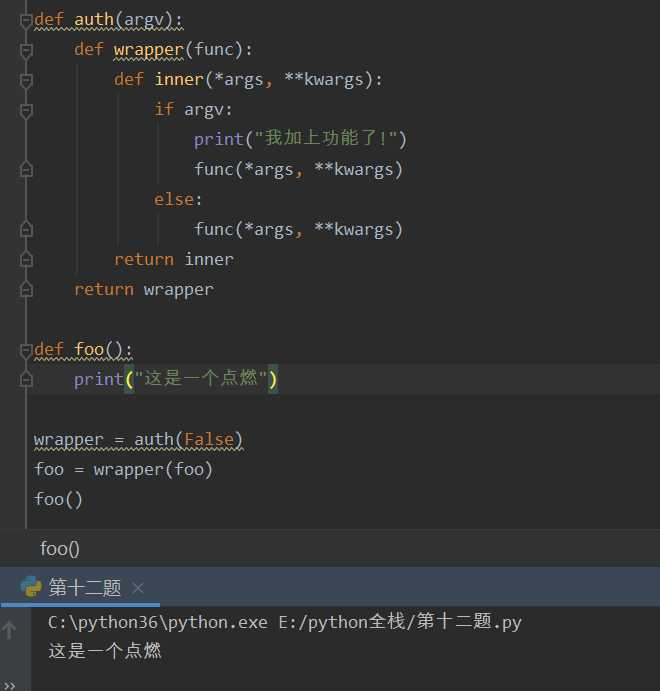
语法糖:@auth(参数)
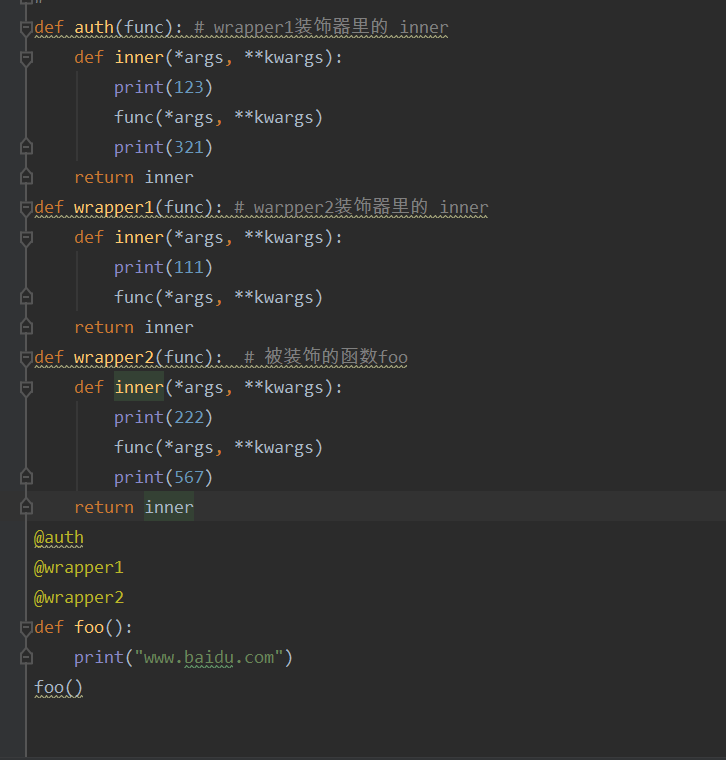
多个装饰器装饰一个函数
多个装饰器装饰一个函数的时候,先执行离被装饰函数最近的装饰器
小技巧: V
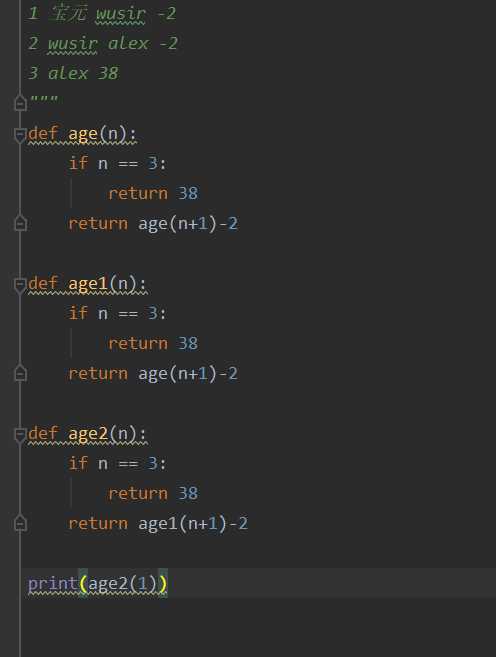
5.递归
一递一归
递:一直传参
归:返回
不断调用自身 (只有这一项是无效递归,死递归)
def func():
print(1)
func()
func()
有明确的终止条件
递归的最大深度(层次) 官方说明1000 实际测试998/997
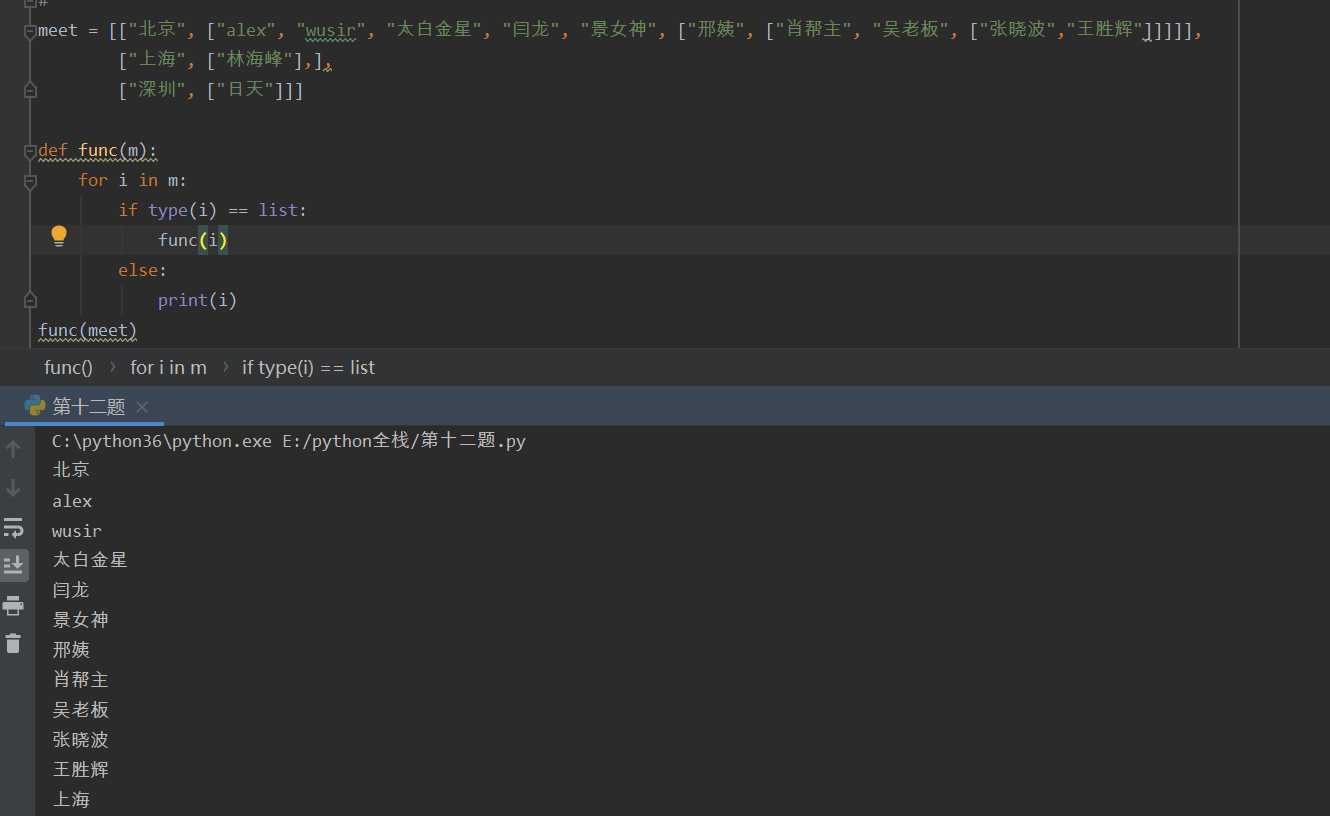
递归的应用场景:
6.自定义模块
模块能干什么?
文件化管理,提高可读性,避免重复代码
拿来就用(避免重复造轮子)python中类库特别多
定义一个模块
一个文件就是一个模块(模块就是一个工具箱,工具是函数)
import会做三件事
将模块中的所有代码读取到当前文件
当前文件开辟空间
等待被调用
import导入同一个模块名时,只执行一次
import+模块名 只能将整个模块拿来
模块名过长时可以起别名,避免覆盖之前的内容
import test as t
from test import t1 as t
as支持import和from
导入模块不能加后缀名
飘红不代表报错
from和import推荐使用from
import和from的区别
from只能执行导入的工具
import 能够执行整个模块中的所有功能
from容易将当前文件中定义的功能覆盖
from比import灵活
import 导入所有 from导入指定功能
import 后边不能有点操作
import 和 from 使用的都是相对路径
import sys # 和python解释交互接口
模块查找顺序
sys.path.append(r"C:\\Users\\oldboy\\Desktop")
内存 > 内置 > 第三方> 自定义
sys.path.insert(0,r"C:\\Users\\oldboy\\Desktop")
内存 > 自定义 > 内置 > 第三方
sys.path.append 添加一个模块查找的路径,python解释器中的环境变量
模块的两种用法
当作模块被导入
当作脚本被执行
if __name__ == "__main__":
当文件被当做模块被调用的时候__name__返回的当前模块名
当文件当做脚本执行时__name__返回的__main__
- 只有py文件当做模块被导入时,字节码才会进行保留
注意自定义模块的名字,不能与内置模块重复
注意自己的思路 -- 循环导入时建议 导入模式放在需要的地方,不能交叉导入
不建议一行导入多个模块
通过__all__ 控制要导入的内容`
`__all__ = ["func"]`
from test import * -- 拿整个模块
pip -- 管理包工具7.time
import time -- 内置模块 -- 标准库
time.time() -- 时间戳 ,浮点数,单位为秒
time.sleep() 睡眠
将时间戳转换成结构化时间
time.localtime() --- 默认当前时间
print(time.localtime(time.time())) 结果是元组
print(time.localtime(time.time())[0]) 索引取值
print(time.localtime(time.time()).tm_year) 根据名字取值
将结构化时间转换成字符串
time.strftime()
time_g = time.localtime()
print(time.strftime("%Y-%m-%d %H:%M:%S",time_g))
将字符串转换成结构化时间
time.strptime()
str_time = "2018-10-1 10:11:12"
time_g = time.strptime(str_time, "%Y-%m-%d %H:%M:%S")
print(time_g)
将结构化时间转换成时间戳
time.mktime()
time_g = time.localtime()
print(time.mktime(time_g))
%Y 年 %m 月 %d 日 %H 时间 %M 分钟 %S 秒8.datatime
from datetime import datetime
print(datetime(2018, 10, 1, 10, 11, 12) - datetime(2011, 11, 1, 20, 10, 10)) --- 差为天数,小时,分,秒
from datetime import datetime print(datetime.now()) # 获取当前时间将对象转换成时间戳
datetime.timestamp()
d = datetime.now()
print(d.timestamp())
将时间戳转换成对象
datetime.fromtimestamp()
import time
f_t = time.time()
print(datetime.fromtimestamp(f_t))
将对象转换成字符串
datetime.strftime()
d = datetime.now()
print(d.strftime("%Y-%m-%d %H:%M:%S"))
将字符串转换成对象
datetime.strptime()
s = "2018-12-31 10:11:12"
print(datetime.strptime(s, "%Y-%m-%d %H:%M:%S"))
可以进行加减运算
from datetime import datetime,timedelta
print(datetime.now() - timedelta(days=1)) -- 按天减(减一天)
print(datetime.now() - timedelta(hours=1)) --- 按小时减9.random -- 随机数
import random
print(random.randint(1,50))
选择1-50之间随机的整数
print(random.random())
0-1 之间随机小数,不包含1
print(random.uniform(1,10))
1- 10 之间随机小数,不包含10
print(random.choice((1,2,3,4,5,7)))
从容器中随机选择一个
print(random.choices((1,2,3,4,5,7),k=3))
从容器中随机选择3个元素,以列表的形式方式,会出现重复元素
print(random.sample((1,2,3,4,5,7),k=3))
从容器中随机选择3个元素,以列表的形式方式,不会出现重复元素
print(random.randrange(1,10,2)) 随机的奇数或随机的偶数
lst = [1,2,3,4,5,6,7]
random.shuffle(lst)
洗牌 将有序的数据打散
print(lst)10.软件开发规范
分文件管理
当代码存在一个py文件中时
不便于管理,修改,增加
可读性差
加载速度慢
软件开发规范是Django的雏形
约定俗成的:
start.py -- 启动文件 --启动接口
common.py -- 公共文件 -- 大家需要的功能
seetings.py -- 配置文件 -- 又叫静态文件,存储变量
src.py -- 主逻辑文件
register -- 用户相关数据文件
logg.log -- 日志文件
bin -- 启动文件夹
lib -- 公共文件夹
conf -- 配置文件夹
core --主逻辑文件夹
db -- 数据文件夹
log -- 日志文件
11.sys
sys 与python解释器做交互
print(sys.path) 模块查找的顺序
print(sys.argv) 只能在终端执行 代替input
print(sys.modules) 查看加载到内存的模块
print(sys.platform) 查看当前操作系统平台 mac - darwin win - win32
print(sys.version) 查看当前解释器的版本
12.序列化
序列化:将数据类型转换成字符串(dump,dumps)
反序列化:将字符串转换成原数据类型(load,loads)
dumps loads -- 用于网络传输
dump load -- 用于文件储存
json
json能够序列:字典,列表,元组,元组序列后变成列表
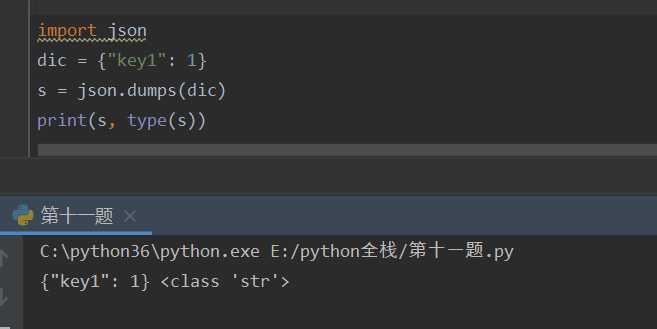
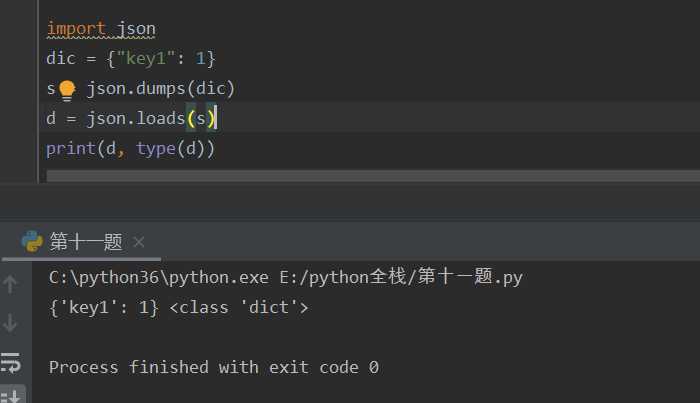
json.dump(dic,open("a","a",encoding="utf-8")) 将源数据类型转换成字符串,写入到文件中
print(json.load(open("a","r",encoding="utf-8"))[‘key‘]) 将文件中字符串转成源数据类型
pickle
只有python有,几乎可以序列python中所有数据类型,匿名函数不能序列
a = pickle.dumps(func) 将原数据类型转换成类似字节的内容
print(pickle.loads(a)) 将类似字节的内容转换成原数据类型13.os
工作路径:
import os -- os是和操作系统做交互,给操作发指令
os.getcwd() -- 获取当前文件的工作路径
os.chdir("绝对路径地址") -- 路径切换
os.curdir -- 返回当前目录 (".")
os.pardir -- 获取当前目录的父目录字符串名 ("..")
文件夹:
os.mkdir("文件夹名") -- 创建文件夹
os.rmdir("文件夹名") -- 删除文件夹
os.makedirs("文件夹名/文件夹名") -- 递归创建文件夹
os.removedirs("文件夹名/文件夹名") -- 递归删除文件夹名
os.listdir("绝对路径") -- 查看当前文件夹下所有内容
文件:
os.remove("绝对路径") -- 删除文件,彻底删除,找不回来
os.rename() -- 重命名
路径:
os.path.abcpath("文件名") -- 返回的是绝对路径
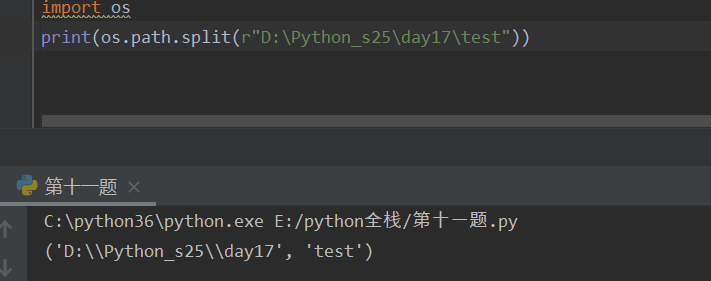
os.path.split("绝对路径") -- 将路径分割成一个路径和一个文件名
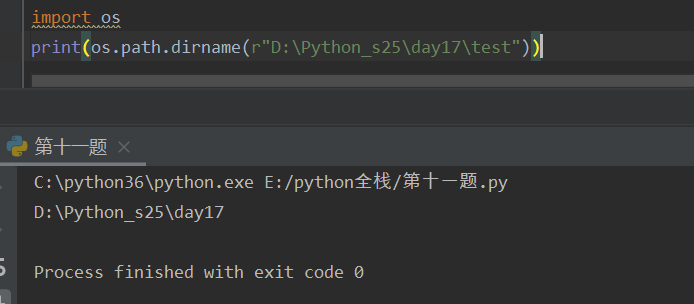
os.path.dirname("绝对路径") -- 获取到父目录
os.path.basename("绝对路径") -- 获取文件名
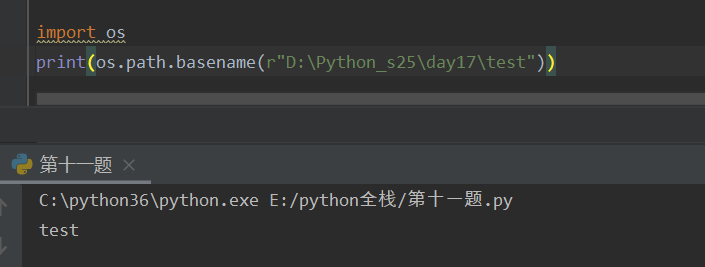
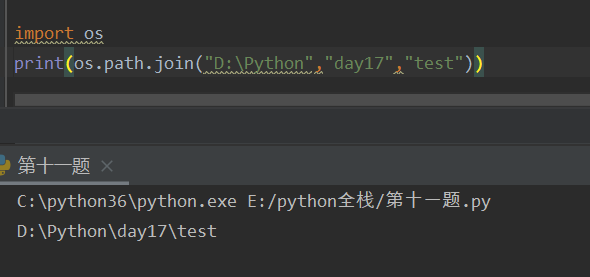
os.path.join("绝对路径","文件名") -- 路径拼接(非常重要)
判断:
os.path.exists("绝对路径") -- 判断当前路径是否存在
os.path.isabs("绝对路径") -- 判断是不是绝对路径
os.path.isdir("绝对路径") -- 判断是不是文件夹
os.path.isfile("绝对路径") -- 判断是不是文件
os.path.getsize("绝对路径") -- 获取文件大小以上是关于python风4的主要内容,如果未能解决你的问题,请参考以下文章