Learn The Architecture Memory Management 译文
Posted justin-y-lin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Learn The Architecture Memory Management 译文相关的知识,希望对你有一定的参考价值。
1、概述
本文档介绍了ARMv8-A架构内存管理的关键——内存地址转换,包括虚拟地址(VA)到物理地址(PA)的转换、地址转换表格式以及TLBs(Translation Lookaside Buffers)管理。
对于任何进行底层bootloader或者驱动代码开发的人员来说,这部分内容都是非常实用的,尤其是对进行MMU(Memory Management Unit)编码的人员。
本文档可以帮助你解到VA如何转换成PA的、识别不同的地址空间、地址转换时地址空间是如何映射的以及TLB相关的操作。
2、什么是内存管理?
内存管理描述了如何访问系统内存。每次操作系统或者应用程序尝试访问内存时,都是硬件负责进行内存管理的,对于应用程序而言,内存管理是一种动态分配内存区域的方式。
2.1、为什么需要内存管理?
因为操作系统和应用程序需要大量的内存来运行,同时,应用程序往往运行在虚拟地址空间,需要实际映射到物理地址空间。
3、虚拟地址和物理地址
使用虚拟地址的一个好处是,操作系统可以控制应用程序的内存布局,操作系统决定虚拟地址是否可见、是否允许访问。这种机制允许操作系统采取沙箱机制管理(即应用程序之间的隔离)应用程序,同时实现了对硬件的抽象。
还有一个好处是,物理内存上不连续的内存区域,在虚拟内存地址空间中可以是连续的。
对于应用程序开发人员而言,他们不需要关心具体的物理内存地址是否可以访问。
实际上,每一个应用程序都维护一个独立的虚拟内存地址空间,它们实际上映射到不同的物理内存区域。操作系统在进行应用程序切换时负责重构虚拟内存地址空间,这就意味着当前应用程序的虚拟地址总是映射到正确的物理内存地址。
虚拟地址通过映射的方式转换为物理地址。虚拟地址和物理地址的映射关系保存在translation tables(地址转换表,或者称作page tables 页表)中,如下图所示:
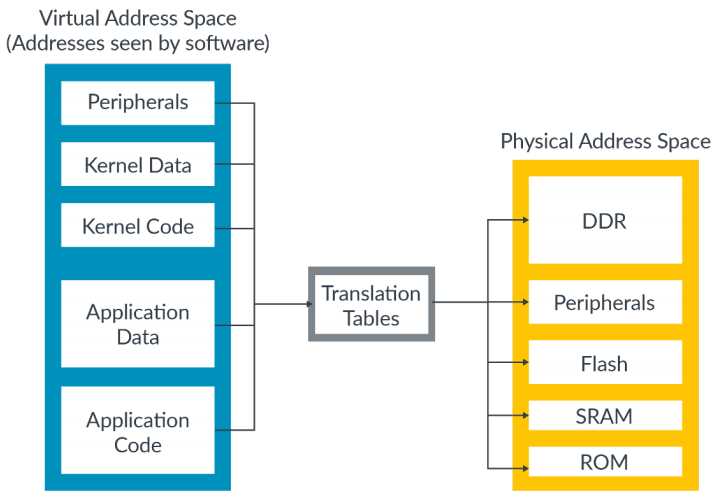
页表保存在内存中,由操作系统或者hypervisor管理。页表不是静态的,而是根据软件对内存的需求及时更新的,页表更新的同时,实际上也改变了虚拟地址和物理地址的映射关系。
4、MMU
MMU负责地址转换,包括:
1)table walk unit,负责从内存中读取页表;
2)TBLs,负责缓存最近使用的页表项;
需要强调的是,应用程序发起的任何内存地址访问都是虚拟地址。虚拟地址会发送给MMU,MMU会首先在TLBs中查找是否有对应的页表项,如果没有找到对应的页表项,那么table walk unit会从内存中读取合适的页表项(table entry)。
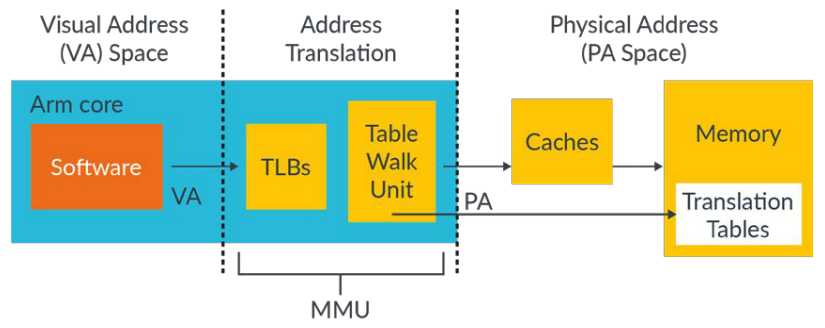
在实际访问物理内存之前,必须完成虚拟地址到物理地址的转换。对于访问缓存数据而言,同样需要实现VA-2-PA的转换,因为ARMv6以后的处理器都将缓存数据保存在物理地址空间中(physically tagged),因此,必须在cache lookup之前完成VA-2-PA转换。ARM CPU包含数据缓存和指令缓存,可以理解为片内物理内存,各自拥有独立的物理地址段。
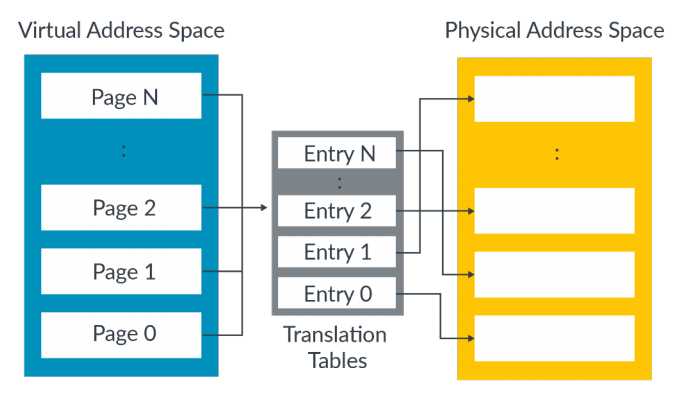
4.1、Table Entry 页表项
虚拟地址空间被划分为以页(32位系统下页大小通常为4KB)为单位的内存页,每一个内存页在页表中占据一个页表项,即Table Entry。页表项和内存页是一一对应的,Entry 0对应block 0(0号内存页),Entry 1对应block 1,依此类推。每一个页表项包含对应的物理地址以及访问属性。
4.2、Table lookup 页表查找
地址转换必然要涉及到页表查找,当发生地址转换时,虚拟地址被分为两部分:
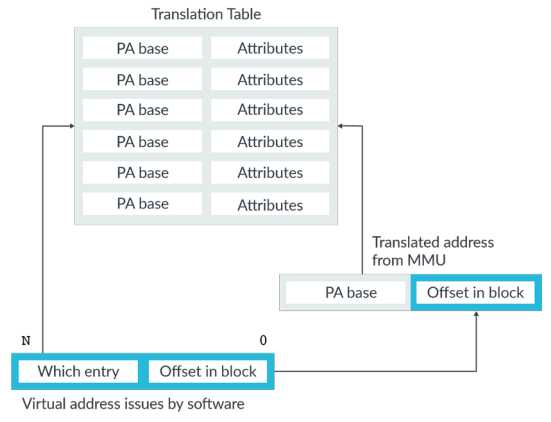
上图是一个一级页表(ARMv8硬件上支持4级页表,Linux内核默认使用3级页表)查找过程图。
虚拟地址的上半部分——Which entry,用来指定页表项,该页表项中保存了虚拟地址对应的物理地址。
虚拟地址的下半部分——Offset in block,表示页内偏移地址,在转换过程中保持不变。
4.3、Mutilevel translation 多级页表转换
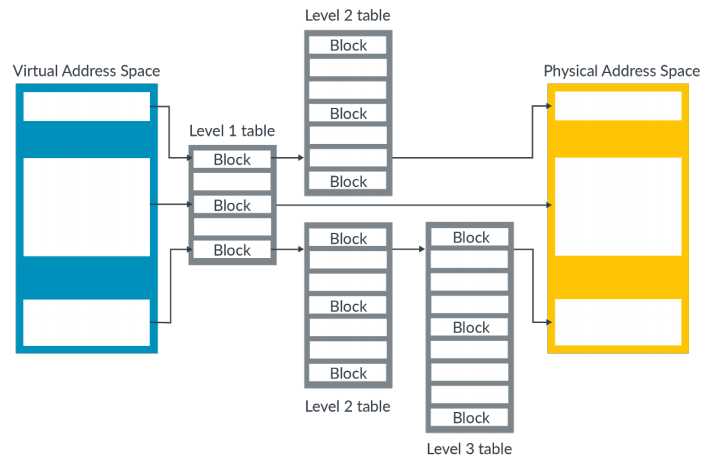
多级页表实际上是将虚拟内存地址空间划分为多个相同大小的页存大页,再将每个内存大页划分为多个相同大小的内存小页。
ARMv8最大支持4级页表,编号0~3。
使用多级页表的好处是,内存大页可以加速地址转换的效率,比如提高TLBs缓存的有效性;同时,内存小页有给应用程序提供了对虚拟内存地址空间的细粒化管理。但是与此同时,TLBs缓存内存小页的有效性就比较差。
为了降低这种开销,操作系统需要在内存大页的效率和内存小页的映射之间进行权衡,决定最合适的页表层级。
5、ARMv8-A虚拟地址空间
ARMv8-A架构有几个独立的虚拟地址空间,如下图所示:
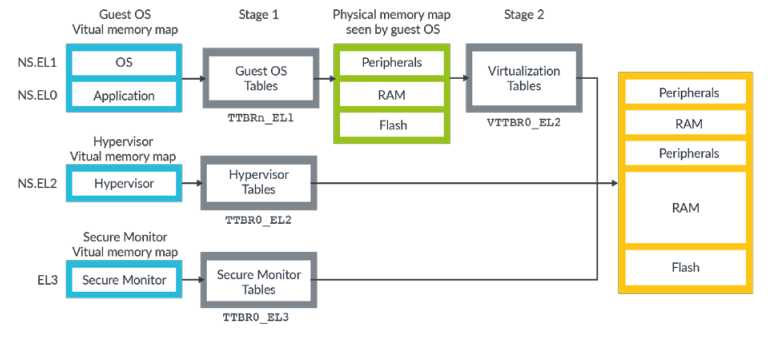
上图显示了三种虚拟地址空间:
1)NS.EL0 and NS.EL1 (Non-secure EL0/EL1)
2)NS.EL2 (Non-secure EL2)
3)EL3
每一种虚拟地址空间都是独立的,而且拥有各自的页表设置(页表层级和页表),我们通常称这种页表设置为——translation regimes。同样的,Secure EL0/EL1/EL2也有各自的虚拟地址空间,只不过上图没有展示出来。
5.1、地址大小
ARMv8-A架构是64位架构,但是并不意味着其地址位宽为64位。
5.1.1 虚拟地址位宽
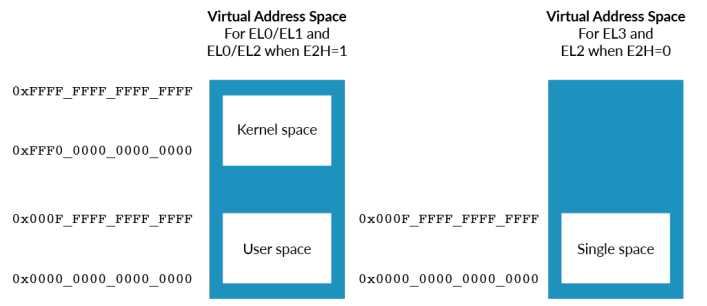
虚拟地址以64位的格式保存,LDR和STR指令通常将地址保存在X寄存器中,但是这并不意味着X寄存器中所有的地址都是有效的。
下图演示了AArch64架构虚拟地址空间布局:
以上是关于Learn The Architecture Memory Management 译文的主要内容,如果未能解决你的问题,请参考以下文章