Spark 知识点总结--调优
Posted wcgstudy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark 知识点总结--调优相关的知识,希望对你有一定的参考价值。
搭建集群: SPARK_WORKER-CORES : 当计算机是32核双线程的时候,需要指定SPARK_WORKER_CORES的个数为64个
SPARK_WORKER_MEMORY :
任务提交:
./spark-submit --master node:port --executor-cores --class ..jar xxx
--executor-cores: 指定每个executor使用的core 的数量
--executor-memory: 指定每个executor最多使用的内存
--total-executor-cores: standalone 集群中 spark application 所使用的总的core
--num-executor : 在yarn 中为 spark application 启动的executor
--Driver-cores: driver使用的core
--Driver-memory: driver使用的内存
以上的参数是在spark-submit 提交任务的时候指定的,也可以在spark-defaults.xml中进行配置
spark 并行度调优: (一般在做测试的时候使用)
sc.textFile(xx,minnum)
sc.parallelize(seq,num)
sc.makeRDD(seq,num)
sc.parallelizePairs(List,num )
在算子层面提高并行度:
ReduceByKey(fun,num),join(xx,num),distinct(num),groupByKey(num)
可以使用repartition进行升高并行度:
repartition(num)/coalesce() repartition(num) = coalesce(num,shuffle=num)
spark.default.parallelism : 本地模式默认的并行度是local[数字] standalone/yarn: 当前executor中所使用的所有的core 的个数
spark.sql.shuffle.partitions 200
自定义分区器
sparkStreaming:
receiver 模式: spark.streaming.blockInterval = 200ms
direct 模式(spark2.3+) : 与读取的topic的 partition 的个数是一致
代码调优:
1、 避免创建重复的RDD,尽量复用同一个RDD
2、对多次使用的RDD进行持久化
持久化的算子:
cache(): 默认将数据放在了内存中,当跨job使用RDD的时候,可以将数据放置到cache中
persist():
MEMORY_ONLY :直接将数据放置到内存中
MEMORY_ONLY_SER: 当数据量比较大的时候,可以将数据序列化之后放置到内存中
MEMORY_AND_DISK:将数据放置到磁盘中
MEMORY_AND_DISK_SER:
checkpoint()
3、尽量避免shuffle类的算子:
map类算子+光弄方式变量来替代join
4、使用map端有预聚合的shuffle类算子
reduceByKey:
aggregateByKey:
代码演示:
package com.optimize.study.spark import org.apache.spark.SparkConf, SparkContext object aggregateByKey def main(args: Array[String]): Unit = val conf = new SparkConf().setMaster("local").setAppName("test") val sc = new SparkContext(conf) val unit = sc.parallelize(Array[(String, Int)]( ("zhangsan", 18), ("zhangsan", 19), ("lisi", 20), ("wangwu", 21), ("zhangsan", 22), ("lisi", 23), ("wangwu", 24), ("wangwu", 25) ), 2) val result = unit.aggregateByKey(" ")((s:String,i:Int)=>s+"$"+i,(s1:String,s2:String)=>s1+"#"+s2) result.foreach(println)
combineByKey:
代码演示:
package com.bjsxt.myscalacode import org.apache.spark.rdd.RDD import org.apache.spark.SparkConf, SparkContext object MyCombineByKey def main(args: Array[String]): Unit = val conf = new SparkConf().setMaster("local").setAppName("test") val sc = new SparkContext(conf) val rdd1 = sc.parallelize(Array[(String, Int)]( ("zhangsan", 18), ("zhangsan", 19), ("lisi", 20), ("wangwu", 21), ("zhangsan", 22), ("lisi", 23), ("wangwu", 24), ("wangwu", 25) ),2) /** * partition index = 0,value = (zhangsan,18) =>(zhangsan,hello18) =>(zhangsan,hello18#19) * partition index = 0,value = (zhangsan,19) * partition index = 0,value = (lisi,20) =>(lisi,hello20) =>(lisi,hello20) * partition index = 0,value = (wangwu,21) =>(wangwu,hell21) =>(wangwu,hell21) * =>(zhangsna,hello18#19@hello22) * =>(lisi,hello20@hello23) * =>(wangwu,hello21@hello24#25) * partition index = 1,value = (zhangsan,22) =>(zhangsna,hello22) =>(zhangsna,hello22) * partition index = 1,value = (lisi,23) =>(lisi,hello23) =>(lisi,hello23) * partition index = 1,value = (wangwu,24) =>(wangwu,hello24) =>(wangwu,hello24#25) * partition index = 1,value = (wangwu,25) */ val unit: RDD[(String, String)] = rdd1.combineByKey((i:Int)=>"hello"+i, (s:String, i:Int)=>s+"#"+i, (s1:String, s2:String)=>s1+"@"+s2) unit.foreach(println) // rdd1.mapPartitionsWithIndex((index,iter)=> // val transIter = iter.map(one => // s"partition index = $index,value = $one" // ) // transIter // ).foreach(println)
map端有预聚合的好处: (相对于直接聚合的好处就是: 直接聚合的时候先将数据进行拉取,然后在reduce端进行聚合,但是预聚合会先在每个map端进行一次聚合然后在对聚合后的数据进行拉取合并)
减少map端shuffle的数据量
减少reduce端拉取的数据量
减少reduce端聚合的次数
4、尽量使用高性能的算子:
使用foreachPartition代替foreach
使用mappartitions代替map
在大量的数据过滤之后使用coalesce减少分区
使用reduceByKey代替GroupByKey
使用repartitionAndSortWithinPartitions代替repartition和sort类操作
5、使用广播变量
使用广播变量可以减少executor端内存的使用
6、使用Kryo优化序列化的性能 spark 中使用到序列化的地方
a、RDD<自定义类型>
b、task 序列化
c、RDD持久化可以进行序列化 MEMOYR_AND_DISK_SER
spark使用Kryo序列化机制。Kryo序列化机制,比默认的java序列化机制速度要快很多,序列化之后的数据所占有的内存更小,大概是java序列化后所使用内存的1/10,所以使用Kryo序列化之后,可以让网络传输的数据更少,在集群中消耗的内存资源更少
spark使用kryo序列化机制需要进行注册:
SparkConf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer").registerKryoClasses(new class[]()SpeedSortKey.class)
7、优化数据结构:
在spark 中尽量使用原生的数据类型代替字符串
在spark中尽量使用字符串代替对象
在spark 中尽量使用数组代替集合
8、代码优化:
减少内存使用
减少节点之间的数据传输
减少磁盘的IO
9、数据本地化调节 --数据本地化级别
a、PROCESS_LOCAL : task处理的数据在当前executor内存中
B、NODE_LOCAL:task处理的数据在当前节点的磁盘上,或者在当前节点其他executor的内存中
C、NO_PREF: task处理数据在外部的数据库中
D、RACK_LOCAL : task处理数据在同机架的其他worker节点的executor内存或者磁盘上
E、ANY :task处理数据在其他的机架上
相关参数调优:
spark.locality.process 3s --指从process级别降级到node级别所需等待的时间
spark.locality.node 3s --指从node级别降级到pref级别所需等待的时间
spark.locality.rack --指rack降级所需等待的时间
driver发送task首先按照数据本地化最高级别进行发送,当task等待3s重试5次之后,如果task依然没有被执行,driver会将task降级发送,同理,依次进行降级处理
10、内存调优
给task足够的运行内存,避免频繁的发生GC,最终导致发min GC 或者 FULL GC ,使JVM停止工作
较少shuffle的聚合内存和较少RDD和广播变量的存储内存
参数:
静态内存:
减少spark.shuffle.memoryFraction 0.2
减少spark.storage.memoryFraction 0.6
统一内存:
spark.memory.fraction 0.6
11、shuffle调节
spark.reducer.maxSizeInFlight : 默认48 M 只 每次拉取数据量的大小
spark.shuffle.io.maxRetries: 默认拉取数据失败重试的次数
spark.shuffle.io.retryWait: 重试的等待间隔
spark.shuffle.sort.bypassMergeThreshold: 200
12、堆外内存调节
节点之间连接的等待时长: --conf spark.core.connection.ack.wait.timeout = 300
正常reduce task 从 maptask 拉取数据的过程是:
首先将数据拉取到jvm存储空间,然后jvm将数据存储到网卡buffer,然后通过网络对数据进行传输
有了堆外内存之后,就跳过;了JVM转存数据的过程,直接将数据从磁盘传输到网卡buffer,然后将数据向外进行传输
Spark每个executor中的堆外内存大小是executor内存大小的1/10,多数情况下需要将这个内存的大小调节到2G以上
调节堆外内存的参数:
yarn下:
--conf spark.yarn.executor.memoryOverhead = 2048 M
standalone下:
--conf spark.executor.memoryOverhead = 2048 M
13、数据倾斜处理
数据倾斜:
MR: 某个task处理的数据大于其他task处理的数据
hive:某张表中的某个字段下相同的key 非常多,其他key 对应的数据量非常少
spark: RDD 中某个分区的数据量大于其他分区的数据量
数据倾斜解决:
hive ETL处理:
场景: Spark需要频繁的操作一张hive有数据倾斜的表,每次操作都会按照倾斜的字段进行关联
解决: 可以菇凉业务是否可以将倾斜提前到hive中发生,这样在spark中就不会存在数据倾斜“治标不治本”
过滤少数倾斜的key:
场景: spark 中估计少数倾斜的key是否对业务有影响,如果对业务影响不大,可以将这些key直接过滤掉,再去进行业务分析
解决: 可以使用filter算子直接将这些倾斜的key过滤掉
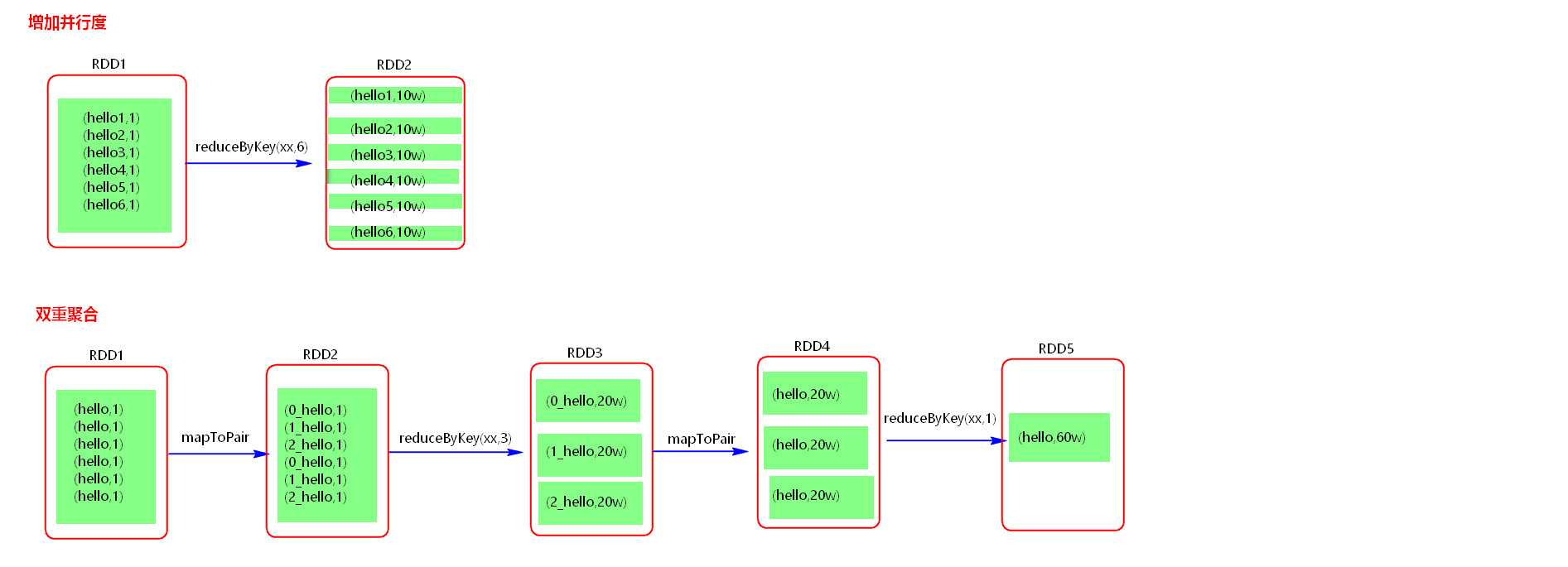
增加并行度:
场景: 数据量大,分区少,不同的key多,可以直接升高并行度
解决: 可以直接使用算子升高并行度
双重聚合:
场景:分区少,key相同的多,数据量大
解决: 可以对相同的key加上随机的前缀,进行聚合,然后对聚合的结果去掉前缀,再去聚合得到最后的结果
将reduce join 转换为 map join:
场景:两个RDD。一个RDD大,一个RDD小,有数据倾斜,对两个RDD需要进行join操作
解决: 将小的RDD回收到Driver端,然后将数据广播出去,对大的RDD进行Map类的算子操作,这样流彻底的避免了shuffle的产生,就没有数据的倾斜
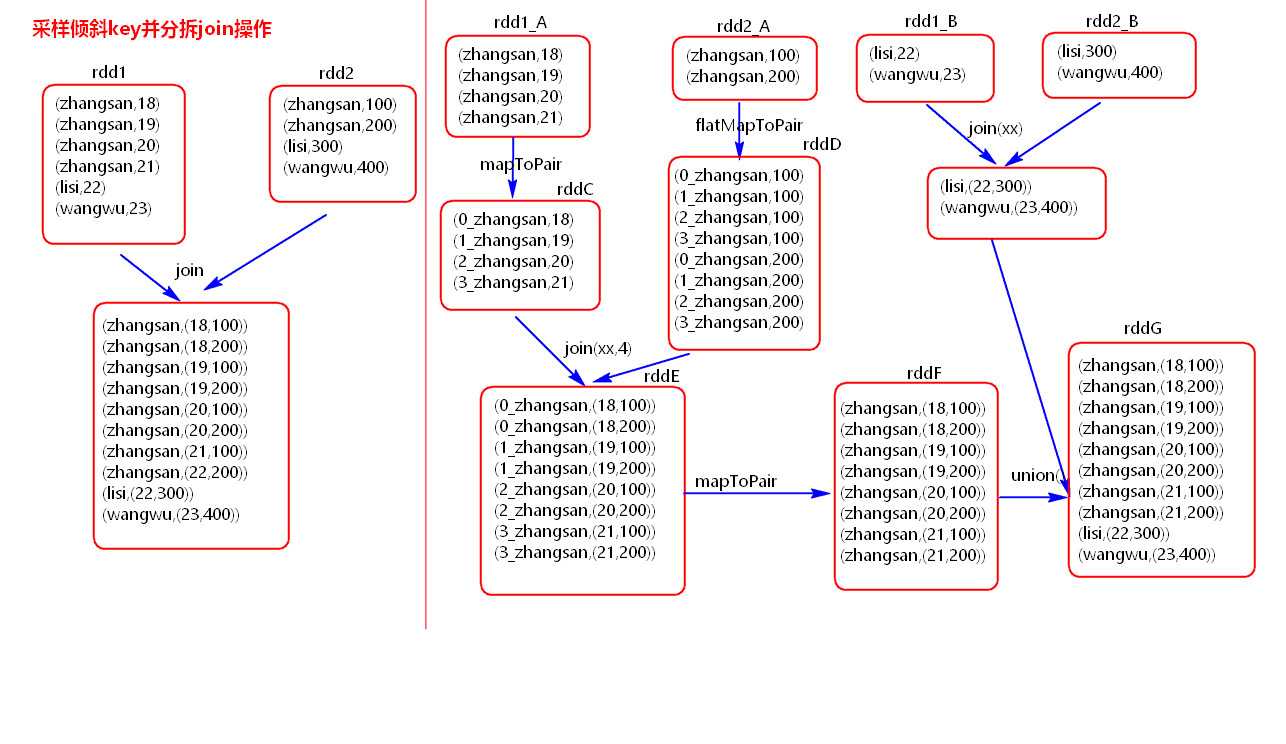
采样倾斜的key并分拆join 操作 :
场景: 两个RDD。一个RDD比较大,数据倾斜,另一个RDD也比较大,对两个RDD采用join操作,无法采用上述操作进行优化
解决: 用采样分析拆分倾斜的key,随机加前缀,前后膨胀,然后在join解决数据倾斜的问题
使用随机前缀和扩容RDD进行join
场景: 两个RDD, 一个RDD大,有大量的KEY有数据倾斜,另一个RDD也比较大,要对两个RDD进行join操作
解决: 使用随机前缀和扩容RDD进行操作,前提条件是需要较大的内存空间
以上是关于Spark 知识点总结--调优的主要内容,如果未能解决你的问题,请参考以下文章
Redis 选型调优监控数据一致性等四大难点知识总结 | 进阶技巧
大厂Mysql高频面试题!让人抓狂的Nginx性能调优,面试总结
全面深度剖析Spark2--知识点,源码,调优,JVM,图计算,项目