Hadoop源码分析——数据节点写数据2
Posted lfdanding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop源码分析——数据节点写数据2相关的知识,希望对你有一定的参考价值。
数据接收
客户端写往数据节点的数据由org.apache.hadoop.hdfs.server.datanode.BlockReceiver.java中的receiveBlock方法接收
void receiveBlock(
DataOutputStream mirrOut, // output to next datanode
DataInputStream mirrIn, // input from next datanode
DataOutputStream replyOut, // output to previous datanode
String mirrAddr, DataTransferThrottler throttlerArg,
int numTargets) throws IOException {
mirrorOut = mirrOut;
mirrorAddr = mirrAddr;
throttler = throttlerArg;
try {
// write data chunk header
if (!finalized) {
BlockMetadataHeader.writeHeader(checksumOut, checksum);
}
if (clientName.length() > 0) {
responder = new Daemon(datanode.threadGroup,
new PacketResponder(this, block, mirrIn,
replyOut, numTargets,
Thread.currentThread()));
responder.start(); // start thread to processes reponses
}
/*
* Receive until packet length is zero.
*/
while (receivePacket() > 0) {}
// flush the mirror out
if (mirrorOut != null) {
try {
mirrorOut.writeInt(0); // mark the end of the block
mirrorOut.flush();
} catch (IOException e) {
handleMirrorOutError(e);
}
}
// wait for all outstanding packet responses. And then
// indicate responder to gracefully shutdown.
if (responder != null) {
((PacketResponder)responder.getRunnable()).close();
}
// if this write is for a replication request (and not
// from a client), then finalize block. For client-writes,
// the block is finalized in the PacketResponder.
if (clientName.length() == 0) {
// close the block/crc files
close();
// Finalize the block. Does this fsync()?
block.setNumBytes(offsetInBlock);
datanode.data.finalizeBlock(block);
datanode.myMetrics.incrBlocksWritten();
}
} catch (IOException ioe) {
LOG.info("Exception in receiveBlock for " + block + " " + ioe);
IOUtils.closeStream(this);
if (responder != null) {
responder.interrupt();
}
cleanupBlock();
throw ioe;
} finally {
if (responder != null) {
try {
responder.join();
} catch (InterruptedException e) {
throw new IOException("Interrupted receiveBlock");
}
responder = null;
}
}
}receiveBlock()将大部分处理工作交给receivePacket()。BlockReceiver.receiveBlock()循环调用receivePacket(),处理这次写请求的所有数据包。当所有的数据接收完毕后,它进行下述清理工作:发送一个空的数据包到下游节点,通知后面的数据节点这次写操作结束;等待PacketResponder线程结束,线程结束,表明所有的响应已经发送给上游节点,同时,本节点的处理结果也已经通知名字节点;关闭文件,并更新数据块文件的长度,然后,通过FSDataset.finalizeBlock()提交数据块。至此,写数据请求处理完毕
receivePacket()代码如下:
/**
* Receives and processes a packet. It can contain many chunks.
* returns size of the packet.
*/
private int receivePacket() throws IOException {
int payloadLen = readNextPacket();
if (payloadLen <= 0) {
return payloadLen;
}
buf.mark();
//read the header
buf.getInt(); // packet length
offsetInBlock = buf.getLong(); // get offset of packet in block
long seqno = buf.getLong(); // get seqno
boolean lastPacketInBlock = (buf.get() != 0);
int endOfHeader = buf.position();
buf.reset();
if (LOG.isDebugEnabled()){
LOG.debug("Receiving one packet for " + block +
" of length " + payloadLen +
" seqno " + seqno +
" offsetInBlock " + offsetInBlock +
" lastPacketInBlock " + lastPacketInBlock);
}
setBlockPosition(offsetInBlock);
// First write the packet to the mirror:
if (mirrorOut != null && !mirrorError) {
try {
mirrorOut.write(buf.array(), buf.position(), buf.remaining());
mirrorOut.flush();
} catch (IOException e) {
handleMirrorOutError(e);
}
}
buf.position(endOfHeader);
int len = buf.getInt();
if (len < 0) {
throw new IOException("Got wrong length during writeBlock(" + block +
") from " + inAddr + " at offset " +
offsetInBlock + ": " + len);
}
if (len == 0) {
LOG.debug("Receiving empty packet for " + block);
} else {
offsetInBlock += len;
int checksumLen = ((len + bytesPerChecksum - 1)/bytesPerChecksum)*
checksumSize;
if ( buf.remaining() != (checksumLen + len)) {
throw new IOException("Data remaining in packet does not match " +
"sum of checksumLen and dataLen");
}
int checksumOff = buf.position();
int dataOff = checksumOff + checksumLen;
byte pktBuf[] = buf.array();
buf.position(buf.limit()); // move to the end of the data.
/* skip verifying checksum iff this is not the last one in the
* pipeline and clientName is non-null. i.e. Checksum is verified
* on all the datanodes when the data is being written by a
* datanode rather than a client. Whe client is writing the data,
* protocol includes acks and only the last datanode needs to verify
* checksum.
*/
if (mirrorOut == null || clientName.length() == 0) {
verifyChunks(pktBuf, dataOff, len, pktBuf, checksumOff);
}
try {
if (!finalized) {
//finally write to the disk :
out.write(pktBuf, dataOff, len);
// If this is a partial chunk, then verify that this is the only
// chunk in the packet. Calculate new crc for this chunk.
if (partialCrc != null) {
if (len > bytesPerChecksum) {
throw new IOException("Got wrong length during writeBlock(" +
block + ") from " + inAddr + " " +
"A packet can have only one partial chunk."+
" len = " + len +
" bytesPerChecksum " + bytesPerChecksum);
}
partialCrc.update(pktBuf, dataOff, len);
byte[] buf = FSOutputSummer.convertToByteStream(partialCrc, checksumSize);
checksumOut.write(buf);
LOG.debug("Writing out partial crc for data len " + len);
partialCrc = null;
} else {
checksumOut.write(pktBuf, checksumOff, checksumLen);
}
datanode.myMetrics.incrBytesWritten(len);
/// flush entire packet before sending ack
flush();
// update length only after flush to disk
datanode.data.setVisibleLength(block, offsetInBlock);
dropOsCacheBehindWriter(offsetInBlock);
}
} catch (IOException iex) {
datanode.checkDiskError(iex);
throw iex;
}
}
// put in queue for pending acks
if (responder != null) {
((PacketResponder)responder.getRunnable()).enqueue(seqno,
lastPacketInBlock);
}
if (throttler != null) { // throttle I/O
throttler.throttle(payloadLen);
}
return payloadLen;
}receivePacket()方法一开始就调用readNextPacket(),通过该方法最少读入一个写请求数据包。读入的数据放在类型为ByteBuffer的缓冲区buf中。ByteBuffer是java.nio.Buffer的子类
readNextPacket()的实现比较琐碎,需要保证缓冲区剩余空间可以读入整个数据包,必须考虑数据包的长度(必要时需要重新分配缓冲区)、并根据需要调整数据在缓冲区中的位置。总而言之,readNextPacket()一次读入一个完整的数据包。
BlockReceiver.receivePacket()从缓冲区读入数据包的包头信息,并赋值到对象的成员变量,接下来的准备动作是:调用setBlockPosition()方法,设置写数据时的文件位置。代码如下
buf.mark();
//read the header
buf.getInt(); // packet length
offsetInBlock = buf.getLong(); // get offset of packet in block
long seqno = buf.getLong(); // get seqno
boolean lastPacketInBlock = (buf.get() != 0);
int endOfHeader = buf.position();
buf.reset();
if (LOG.isDebugEnabled()){
LOG.debug("Receiving one packet for " + block +
" of length " + payloadLen +
" seqno " + seqno +
" offsetInBlock " + offsetInBlock +
" lastPacketInBlock " + lastPacketInBlock);
}
setBlockPosition(offsetInBlock);我们知道,写数据的时候其实需要同时写两个文件,数据块文件和它的校验信息文件,BlockReceiver.setBlockPositiion()会设置这两个文件的写位置,为后续持久化数据做准备。设置数据块文件的写位置比较简单,但校验信息文件的就相对复杂了,这又是一个和分块校验相关的调整。校验信息的计算需要数据以块的形式组织,但用户以流的形式写数据,如果写(追加)数据的开始点落在某个校验块的中间,需要在确定校验信息文件写位置的时候,计算不完整数据校验块(图中的校验块n)的校验信息,为后续写校验数据做准备。
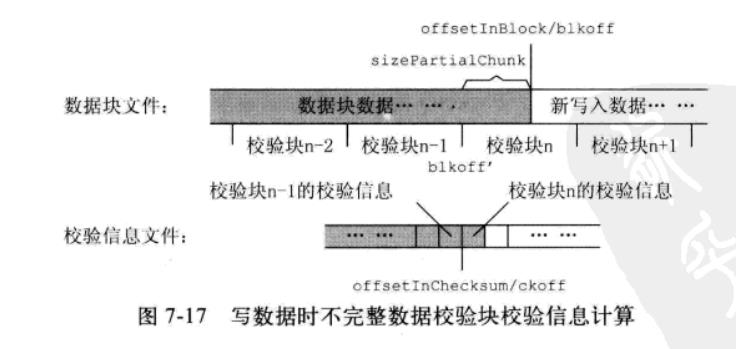
setBlockPosition()方法只有一个参数offsetInBlock,即数据块文件的写位置,如果该位置不处于校验块的边界,就会调用computePartialChunkCrc()计算上述校验信息。该方法需要三个参数,进入方法时,前面两个参数blkoff,ckoff的值如上图,第三个参数bytesPerChecksum是校验块的大小。根据这些参数,首先可以计算出不完整数据块的长度sizePartialChunk,然后,分配缓冲区读入数据,计算这些数据的校验和。校验和的结果保存在BlockReceiver的成员变量partialCrc中,后面会和新写入的数据一起,计算出新的校验和的值,并保持在校验信息文件的当前位置。注意,对于数据块文件,新写入的数据会追加在数据块文件的文件尾,但校验信息文件,如果对应的是一个不完整数据校验块,那么,文件的最后部分(从ckoff开始的地方)会被更新,而不能简单地直接进行追加。代码如下:
/**
* Sets the file pointer in the local block file to the specified value.
*/
private void setBlockPosition(long offsetInBlock) throws IOException {
if (finalized) {
if (!isRecovery) {
throw new IOException("Write to offset " + offsetInBlock +
" of block " + block +
" that is already finalized.");
}
if (offsetInBlock > datanode.data.getLength(block)) {
throw new IOException("Write to offset " + offsetInBlock +
" of block " + block +
" that is already finalized and is of size " +
datanode.data.getLength(block));
}
return;
}
if (datanode.data.getChannelPosition(block, streams) == offsetInBlock) {
return; // nothing to do
}
long offsetInChecksum = BlockMetadataHeader.getHeaderSize() +
offsetInBlock / bytesPerChecksum * checksumSize;
if (out != null) {
out.flush();
}
if (checksumOut != null) {
checksumOut.flush();
}
// If this is a partial chunk, then read in pre-existing checksum
if (offsetInBlock % bytesPerChecksum != 0) {
LOG.info("setBlockPosition trying to set position to " +
offsetInBlock + " for " + block +
" which is not a multiple of bytesPerChecksum " +
bytesPerChecksum);
computePartialChunkCrc(offsetInBlock, offsetInChecksum, bytesPerChecksum);
}
if (LOG.isDebugEnabled()) {
LOG.debug("Changing block file offset of block " + block + " from " +
datanode.data.getChannelPosition(block, streams) +
" to " + offsetInBlock +
" meta file offset to " + offsetInChecksum);
}
// set the position of the block file
datanode.data.setChannelPosition(block, streams, offsetInBlock, offsetInChecksum);
}
/**
* reads in the partial crc chunk and computes checksum
* of pre-existing data in partial chunk.
*/
private void computePartialChunkCrc(long blkoff, long ckoff,
int bytesPerChecksum) throws IOException {
// find offset of the beginning of partial chunk.
//
int sizePartialChunk = (int) (blkoff % bytesPerChecksum);
int checksumSize = checksum.getChecksumSize();
blkoff = blkoff - sizePartialChunk;
LOG.info("computePartialChunkCrc sizePartialChunk " +
sizePartialChunk + " " + block +
" offset in block " + blkoff +
" offset in metafile " + ckoff);
// create an input stream from the block file
// and read in partial crc chunk into temporary buffer
//
byte[] buf = new byte[sizePartialChunk];
byte[] crcbuf = new byte[checksumSize];
FSDataset.BlockInputStreams instr = null;
try {
instr = datanode.data.getTmpInputStreams(block, blkoff, ckoff);
IOUtils.readFully(instr.dataIn, buf, 0, sizePartialChunk);
// open meta file and read in crc value computer earlier
IOUtils.readFully(instr.checksumIn, crcbuf, 0, crcbuf.length);
} finally {
IOUtils.closeStream(instr);
}
// compute crc of partial chunk from data read in the block file.
partialCrc = new PureJavaCrc32();
partialCrc.update(buf, 0, sizePartialChunk);
LOG.info("Read in partial CRC chunk from disk for " + block);
// paranoia! verify that the pre-computed crc matches what we
// recalculated just now
if (partialCrc.getValue() != FSInputChecker.checksum2long(crcbuf)) {
String msg = "Partial CRC " + partialCrc.getValue() +
" does not match value computed the " +
" last time file was closed " +
FSInputChecker.checksum2long(crcbuf);
throw new IOException(msg);
}
//LOG.debug("Partial CRC matches 0x" +
// Long.toHexString(partialCrc.getValue()));
}上述准备工作完成后,receivePacket()把请求的数据包发送到下游的数据节点,通过这种方式,写数据的数据包就会流经数据流管道上的所有数据节点。代码如下
if (mirrorOut != null && !mirrorError) {
try {
mirrorOut.write(buf.array(), buf.position(), buf.remaining());
mirrorOut.flush();
} catch (IOException e) {
handleMirrorOutError(e);
}
}接下来要提及的是数据长度为0的数据包,这是一种特殊的数据包,当客户端长时间没有输出数据时,就会发送这样的心跳包,用于维护客户端和数据流管道上的各个数据节点的TCP连接。,如果数据包的长度不是0,就要将请求包中的数据和校验和写入文件。代码如下:
if (len == 0) {
LOG.debug("Receiving empty packet for " + block);
} else {
offsetInBlock += len;
int checksumLen = ((len + bytesPerChecksum - 1)/bytesPerChecksum)*
checksumSize;
if ( buf.remaining() != (checksumLen + len)) {
throw new IOException("Data remaining in packet does not match " +
"sum of checksumLen and dataLen");
}
int checksumOff = buf.position();
int dataOff = checksumOff + checksumLen;
byte pktBuf[] = buf.array();
buf.position(buf.limit()); // move to the end of the data.
/* skip verifying checksum iff this is not the last one in the
* pipeline and clientName is non-null. i.e. Checksum is verified
* on all the datanodes when the data is being written by a
* datanode rather than a client. Whe client is writing the data,
* protocol includes acks and only the last datanode needs to verify
* checksum.
*/
if (mirrorOut == null || clientName.length() == 0) {
verifyChunks(pktBuf, dataOff, len, pktBuf, checksumOff);
}
try {
if (!finalized) {
//finally write to the disk :
out.write(pktBuf, dataOff, len);
// If this is a partial chunk, then verify that this is the only
// chunk in the packet. Calculate new crc for this chunk.
if (partialCrc != null) {
if (len > bytesPerChecksum) {
throw new IOException("Got wrong length during writeBlock(" +
block + ") from " + inAddr + " " +
"A packet can have only one partial chunk."+
" len = " + len +
" bytesPerChecksum " + bytesPerChecksum);
}
partialCrc.update(pktBuf, dataOff, len);
byte[] buf = FSOutputSummer.convertToByteStream(partialCrc, checksumSize);
checksumOut.write(buf);
LOG.debug("Writing out partial crc for data len " + len);
partialCrc = null;
} else {
checksumOut.write(pktBuf, checksumOff, checksumLen);
}
datanode.myMetrics.incrBytesWritten(len);
/// flush entire packet before sending ack
flush();
// update length only after flush to disk
datanode.data.setVisibleLength(block, offsetInBlock);
dropOsCacheBehindWriter(offsetInBlock);
}
} catch (IOException iex) {
datanode.checkDiskError(iex);
throw iex;
}
}
// put in queue for pending acks
if (responder != null) {
((PacketResponder)responder.getRunnable()).enqueue(seqno,
lastPacketInBlock);
}
if (throttler != null) { // throttle I/O
throttler.throttle(payloadLen);
}
return payloadLen;主要关注点包括:客户端写数据的时候,只有最后一个数据节点需要通过verifyChunks()方法对数据进行校验,数据流管道中的其他节点不需要执行这项检查。校验发现数据有问题,会上报名字节点,并抛出异常通知调用者BlockReceiver.receivePacket();数据包如果成功接收并顺利写入磁盘后,则需要将处理的结果,通过PacketResponder.enqueue()方法,发送给PacketResponder线程,并由该线程继续后面的处理。
以上是关于Hadoop源码分析——数据节点写数据2的主要内容,如果未能解决你的问题,请参考以下文章