Centos 使用kubeadm安装Kubernetes 1.15.3
Posted majiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Centos 使用kubeadm安装Kubernetes 1.15.3相关的知识,希望对你有一定的参考价值。
本来没打算搞这个文章的,第一里面有瑕疵(没搞定的地方),第二在我的Ubuntu 18 Kubernetes集群的安装和部署 以及Helm的安装 也有安装,第三 和社区的问文章比较雷同 https://www.kubernetes.org.cn/5551.html
kubeadm是Kubernetes官方提供的用于快速安装Kubernetes集群的工具,伴随Kubernetes每个版本的发布都会同步更新,kubeadm会对集群配置方面的一些实践做调整,通过实验kubeadm可以学习到Kubernetes官方在集群配置上一些新的最佳实践。
最近发布的Kubernetes 1.15.2中,kubeadm对HA集群的配置已经达到beta可用,说明kubeadm距离生产环境中可用的距离越来越近了。
1.准备
1.1系统配置
在安装之前,需要先做如下准备。两台Centos 18如下:
192.168.100.11 k8s-master 192.168.100.12 k8s-node
禁用防火墙:
systemctl stop firewalld
systemctl disable firewalld
禁用SELINUX:
setenforce 0 vi /etc/selinux/config SELINUX=disabled
创建vi /etc/sysctl.d/k8s.conf文件,添加如下内容:
net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1
执行命令使修改生效。
modprobe br_netfilter
sysctl -p /etc/sysctl.d/k8s.conf
1.2kube-proxy开启ipvs的前置条件
由于ipvs已经加入到了内核的主干,在所有的Kubernetes节点k8s-master和k8s-node上执行以下脚本:
cat > /etc/sysconfig/modules/ipvs.modules <<EOF #!/bin/bash modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack_ipv4 EOF chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
上面脚本创建了的/etc/sysconfig/modules/ipvs.modules文件,保证在节点重启后能自动加载所需模块。 使用以下命令查看是否已经正确加载所需的内核模块。
lsmod | grep -e ip_vs -e nf_conntrack_ipv4
接下来还需要确保各个节点上已经安装了ipset软件包。
为了便于查看ipvs的代理规则,最好安装一下ipvsadm管理工具。
如果以上前提条件如果不满足,则即使kube-proxy的配置开启了ipvs模式,也会退回到iptables模式。
1.3安装Docker
Kubernetes从1.6开始使用CRI(Container Runtime Interface)容器运行时接口。默认的容器运行时仍然是Docker,使用的是kubelet中内置dockershim CRI实现。
安装docker的yum源:
yum install -y yum-utils device-mapper-persistent-data lvm2 yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
查看最新的Docker版本:
yum list docker-ce.x86_64 --showduplicates |sort -r
这里在各节点安装docker的18.09.7版本。
yum makecache fast yum install -y --setopt=obsoletes=0 docker-ce-18.09.7-3.el7 systemctl start docker systemctl enable docker
确认一下iptables filter表中FOWARD链的默认策略(pllicy)为ACCEPT。
iptables -nvL
1.4 修改docker cgroup driver为systemd
根据文档CRI installation中的内容,对于使用systemd作为init system的Linux的发行版,使用systemd作为docker的cgroup driver可以确保服务器节点在资源紧张的情况更加稳定,因此这里修改各个节点上docker的cgroup driver为systemd。
创建或修改vi /etc/docker/daemon.json:
"exec-opts": ["native.cgroupdriver=systemd"]
重启docker:
systemctl restart docker docker info | grep Cgroup Cgroup Driver: systemd
2.使用kubeadm部署Kubernetes
2.1 安装kubeadm和kubelet
下面在各节点安装kubeadm和kubelet:
cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg EOF
测试地址https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64是否可用
curl https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64 yum makecache fast yum install -y kubelet kubeadm kubectl
从安装结果可以看出还安装了cri-tools, kubernetes-cni, socat三个依赖:
- 官方从Kubernetes 1.14开始将cni依赖升级到了0.7.5版本
- socat是kubelet的依赖
- cri-tools是CRI(Container Runtime Interface)容器运行时接口的命令行工具
运行kubelet –help可以看到原来kubelet的绝大多数命令行flag参数都被DEPRECATED了,
而官方推荐我们使用–config指定配置文件,并在配置文件中指定原来这些flag所配置的内容。具体内容可以查看这里Set Kubelet parameters via a config file。这也是Kubernetes为了支持动态Kubelet配置(Dynamic Kubelet Configuration)才这么做的,参考Reconfigure a Node’s Kubelet in a Live Cluster。
kubelet的配置文件必须是json或yaml格式,具体可查看这里。
Kubernetes 1.8开始要求关闭系统的Swap,如果不关闭,默认配置下kubelet将无法启动。 关闭系统的Swap方法如下:
swapoff -a修改 /etc/fstab 文件,注释掉 SWAP 的自动挂载,使用确认swap已经关闭。 swappiness参数调整,修改 /etc/sysctl.d/k8s.conf添加下面一行:
vm.swappiness=0执行sysctl -p /etc/sysctl.d/k8s.conf使修改生效。
2.2 使用kubeadm init初始化集群
在各节点开机启动kubelet服务:
使用 kubeadm config print init-defaults 可以打印集群初始化默认的配置,
从默认的配置中可以看到,可以使用imageRepository定制在集群初始化时拉取k8s所需镜像的地址。基于默认配置定制出本次使用kubeadm初始化集群所需的配置文件kubeadm.yaml:
apiVersion: kubeadm.k8s.io/v1beta2 kind: InitConfiguration localAPIEndpoint: advertiseAddress: 192.168.100.11 bindPort: 6443 nodeRegistration: taints: - effect: PreferNoSchedule key: node-role.kubernetes.io/master --- apiVersion: kubeadm.k8s.io/v1beta2 kind: ClusterConfiguration kubernetesVersion: v1.15.3 networking: podSubnet: 10.244.0.0/16
使用kubeadm默认配置初始化的集群,会在master节点打上node-role.kubernetes.io/master:NoSchedule的污点,阻止master节点接受调度运行工作负载。这里测试环境只有两个节点,所以将这个taint修改为node-role.kubernetes.io/master:PreferNoSchedule。
在开始初始化集群之前可以使用 kubeadm config images pull 预先在各个节点上拉取所k8s需要的docker镜像。
接下来使用kubeadm初始化集群,选择k8s-master作为Master Node,在k8s-master上执行下面的命令:
上面记录了完成的初始化输出的内容,根据输出的内容基本上可以看出手动初始化安装一个Kubernetes集群所需要的关键步骤。 其中有以下关键内容:
- [kubelet-start] 生成kubelet的配置文件”/var/lib/kubelet/config.yaml”
- [certs]生成相关的各种证书
- [kubeconfig]生成相关的kubeconfig文件
- [control-plane]使用/etc/kubernetes/manifests目录中的yaml文件创建apiserver、controller-manager、scheduler的静态pod
- [bootstraptoken]生成token记录下来,后边使用kubeadm join往集群中添加节点时会用到
- 下面的命令是配置常规用户如何使用kubectl访问集群:
-
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config - 最后给出了将节点加入集群的命令kubeadm join 192.168.100.11:6443 --token 8msx9w.mi6nrzcqn48p6o0u \\
--discovery-token-ca-cert-hash sha256:83a6b4e2ddc275858564ab3a4bea7d72eb3ede6cf5ec40db87dabb39ba1a2d87
查看一下集群状态,确认个组件都处于healthy状态:
集群初始化如果遇到问题,可以使用下面的命令进行清理:
kubeadm reset ifconfig cni0 down ip link delete cni0 ifconfig flannel.1 down ip link delete flannel.1 rm -rf /var/lib/cni/
2.3 安装Pod Network
接下来安装flannel network add-on:
curl -O https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml kubectl apply -f kube-flannel.yml
这里注意kube-flannel.yml这个文件里的flannel的镜像是0.11.0,quay.io/coreos/flannel:v0.11.0-amd64
如果Node有多个网卡的话,参考flannel issues 39701,目前需要在kube-flannel.yml中使用–iface参数指定集群主机内网网卡的名称,否则可能会出现dns无法解析。需要将kube-flannel.yml下载到本地,flanneld启动参数加上–iface=<iface-name>
使用kubectl get pod --all-namespaces=true -o wide 或者 kubectl get pod -n kube-system 确保所有的Pod都处于Running状态。
2.4 测试集群DNS是否可用
kubectl run curl --image=radial/busyboxplus:curl -it kubectl run --generator=deployment/apps.v1beta1 is DEPRECATED and will be removed in a future version. Use kubectl create instead. If you don‘t see a command prompt, try pressing enter. [ root@curl-5cc7b478b6-r997p:/ ]$
进入后执行nslookup kubernetes.default确认解析正常:
nslookup kubernetes.default Server: 10.96.0.10 Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local Name: kubernetes.default Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local
2.5 向Kubernetes集群中添加Node节点
下面将node2这个主机添加到Kubernetes集群中,在node2上执行:
node2加入集群很是顺利,下面在master节点上执行命令查看集群中的节点:
kubectl get node NAME STATUS ROLES AGE VERSION k8s-master Ready master 12m v1.15.3 k8s-node Ready <none> 3m1s v1.15.3
2.5.1 如何从集群中移除Node
如果需要从集群中移除node2这个Node执行下面的命令:
在master节点上执行:
kubectl drain k8s-node --delete-local-data --force --ignore-daemonsets
kubectl delete node k8s-node
在node2上执行:
kubeadm reset ifconfig cni0 down ip link delete cni0 ifconfig flannel.1 down ip link delete flannel.1 rm -rf /var/lib/cni/
在node1上执行:
kubectl delete node node2
2.6 kube-proxy开启ipvs
修改ConfigMap的kube-system/kube-proxy中的config.conf,mode: “ipvs”
之后重启各个节点上的kube-proxy pod:
kubectl get pod -n kube-system | grep kube-proxy | awk ‘system("kubectl delete pod "$1" -n kube-system")‘ [root@k8s-master ~]# kubectl get pod -n kube-system | grep kube-proxy kube-proxy-f9rnj 1/1 Running 0 39s kube-proxy-q6hks 1/1 Running 0 44s [root@k8s-master ~]# kubectl logs kube-proxy-f9rnj -n kube-system I0822 09:49:35.870937 1 server_others.go:170] Using ipvs Proxier. W0822 09:49:35.871397 1 proxier.go:401] IPVS scheduler not specified, use rr by default I0822 09:49:35.872146 1 server.go:534] Version: v1.15.3
日志中打印出了Using ipvs Proxier,说明ipvs模式已经开启。
3.Kubernetes常用组件部署
越来越多的公司和团队开始使用Helm这个Kubernetes的包管理器,这里也将使用Helm安装Kubernetes的常用组件。
3.1 Helm的安装
Helm由客户端命helm令行工具和服务端tiller组成,Helm的安装十分简单。 下载helm命令行工具到master节点node1的/usr/local/bin下,这里下载的2.14.1版本:
curl -O https://get.helm.sh/helm-v2.14.1-linux-amd64.tar.gz tar -zxvf helm-v2.14.1-linux-amd64.tar.gz cd linux-amd64/ cp helm /usr/local/bin/
为了安装服务端tiller,还需要在这台机器上配置好kubectl工具和kubeconfig文件,确保kubectl工具可以在这台机器上访问apiserver且正常使用。 这里的node1节点已经配置好了kubectl。
因为Kubernetes APIServer开启了RBAC访问控制,所以需要创建tiller使用的service account: tiller并分配合适的角色给它。 详细内容可以查看helm文档中的Role-based Access Control。 这里简单起见直接分配cluster-admin这个集群内置的ClusterRole给它。创建helm-rbac.yaml文件:
接下来使用helm部署tiller:
tiller默认被部署在k8s集群中的kube-system这个namespace下:
注意由于某些原因需要网络可以访问gcr.io和kubernetes-charts.storage.googleapis.com,如果无法访问可以通过helm init –service-account tiller –tiller-image <your-docker-registry>/tiller:v2.13.1 –skip-refresh使用私有镜像仓库中的tiller镜像
最后在k8s-master上修改helm chart仓库的地址为azure提供的镜像地址:
3.2 使用Helm部署nginx Ingress
为了便于将集群中的服务暴露到集群外部,需要使用Ingress。接下来使用Helm将Nginx Ingress部署到Kubernetes上。 Nginx Ingress Controller被部署在Kubernetes的边缘节点上,关于Kubernetes边缘节点的高可用相关的内容可以查看之前整理的Bare metal环境下Kubernetes Ingress边缘节点的高可用,Ingress Controller使用hostNetwork。
我们将k8s-node(192.168.100.11)做为边缘节点,打上Label:
kubectl label node k8s-master node-role.kubernetes.io/edge= #kubectl label node k8s-master node-role.kubernetes.io/edge- #减号表示删除 kubectl get node
stable/nginx-ingress chart的值文件ingress-nginx.yaml如下:
controller: replicaCount: 1 hostNetwork: true nodeSelector: node-role.kubernetes.io/edge: ‘‘ affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - nginx-ingress - key: component operator: In values: - controller topologyKey: kubernetes.io/hostname tolerations: - key: node-role.kubernetes.io/master operator: Exists effect: NoSchedule - key: node-role.kubernetes.io/master operator: Exists effect: PreferNoSchedule defaultBackend: nodeSelector: node-role.kubernetes.io/edge: ‘‘ tolerations: - key: node-role.kubernetes.io/master operator: Exists effect: NoSchedule - key: node-role.kubernetes.io/master operator: Exists effect: PreferNoSchedule
nginx ingress controller的副本数replicaCount为1,将被调度到node1这个边缘节点上。这里并没有指定nginx ingress controller service的externalIPs,而是通过hostNetwork: true设置nginx ingress controller使用宿主机网络。
helm repo update helm install stable/nginx-ingress -n nginx-ingress --namespace ingress-nginx -f ingress-nginx.yaml kubectl get pod -n ingress-nginx -o wide
如果访问http://192.168.100.11返回default backend,则部署完成。
3.3 使用Helm部署dashboard
kubernetes-dashboard.yaml:
image: repository: k8s.gcr.io/kubernetes-dashboard-amd64 tag: v1.10.1 ingress: enabled: true hosts: - k8s.frognew.com annotations: nginx.ingress.kubernetes.io/ssl-redirect: "true" nginx.ingress.kubernetes.io/backend-protocol: "HTTPS" tls: - secretName: frognew-com-tls-secret hosts: - k8s.frognew.com nodeSelector: node-role.kubernetes.io/edge: ‘‘ tolerations: - key: node-role.kubernetes.io/master operator: Exists effect: NoSchedule - key: node-role.kubernetes.io/master operator: Exists effect: PreferNoSchedule rbac: clusterAdminRole: true
安装
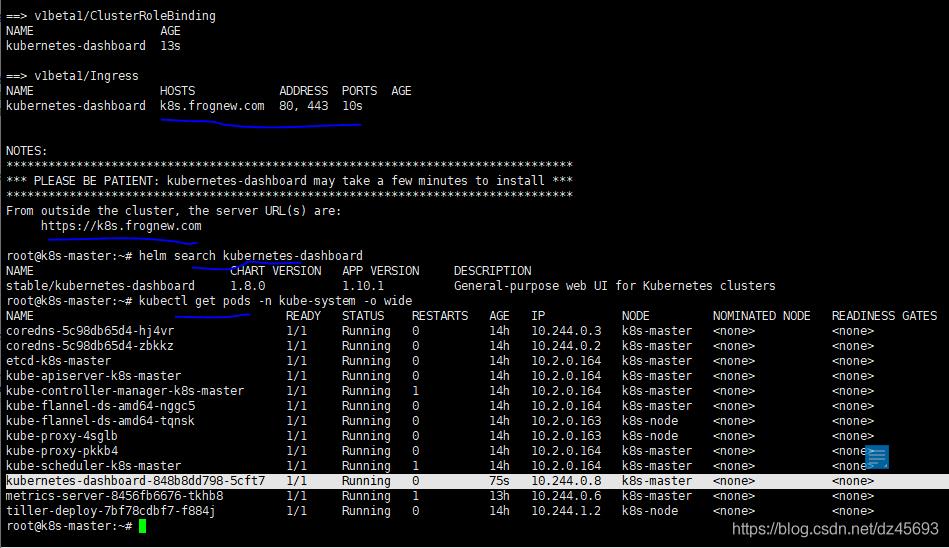
helm install stable/kubernetes-dashboard -n kubernetes-dashboard --namespace kube-system -f kubernetes-dashboard.yaml kubectl -n kube-system get secret | grep kubernetes-dashboard-token kubectl describe -n kube-system secret/kubernetes-dashboard-token-xxx
在dashboard的登录窗口使用上面的token登录。
![]() ?
?
但是遗憾的我不知道 怎么访问,我估计与dns的配置有关吧。http://k8s.frognew.com/ 是无法访问
这里我参考了很多文章,好像都成功就是不能访问。。。。。
3.4 使用Helm部署metrics-server
从Heapster的github https://github.com/kubernetes/heapster中可以看到已经,heapster已经DEPRECATED。 这里是heapster的deprecation timeline。 可以看出heapster从Kubernetes 1.12开始从Kubernetes各种安装脚本中移除。
Kubernetes推荐使用metrics-server。我们这里也使用helm来部署metrics-server。
metrics-server.yaml:
args: - --logtostderr - --kubelet-insecure-tls - --kubelet-preferred-address-types=InternalIP nodeSelector: node-role.kubernetes.io/edge: ‘‘ tolerations: - key: node-role.kubernetes.io/master operator: Exists effect: NoSchedule - key: node-role.kubernetes.io/master operator: Exists effect: PreferNoSchedule
使用下面的命令可以获取到关于集群节点基本的指标信息:
遗憾的是,当前Kubernetes Dashboard还不支持metrics-server。因此如果使用metrics-server替代了heapster,将无法在dashboard中以图形展示Pod的内存和CPU情况(实际上这也不是很重要,当前我们是在Prometheus和Grafana中定制的Kubernetes集群中各个Pod的监控,因此在dashboard中查看Pod内存和CPU也不是很重要)。 Dashboard的github上有很多这方面的讨论,如https://github.com/kubernetes/dashboard/issues/2986,Dashboard已经准备在将来的某个时间点支持metrics-server。但由于metrics-server和metrics pipeline肯定是Kubernetes在monitor方面未来的方向,所以推荐使用metrics-server。
参考
利用Helm一键部署Kubernetes Dashboard并启用免费HTTPS
以上是关于Centos 使用kubeadm安装Kubernetes 1.15.3的主要内容,如果未能解决你的问题,请参考以下文章