程序员,你应该知道的二分查找算法
Posted jamaler
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了程序员,你应该知道的二分查找算法相关的知识,希望对你有一定的参考价值。
原理
二分查找(Binary Search)算法,也叫折半查找算法。二分查找的思想非常简单,有点类似分治的思想。二分查找针对的是一个有序的数据集合,每次都通过跟区间的中间元素对比,将待查找的区间缩小为之前的一半,直到找到要查找的元素,或者区间被缩小为 0。
为了方便理解,我们以数组1, 2, 4, 5, 6, 7, 9, 12, 15, 19, 23, 26, 29, 34, 39,在数组中查找26为例,制作了一张查找过程图,其中low标示左下标,high标示右下标,mid标示中间值下标
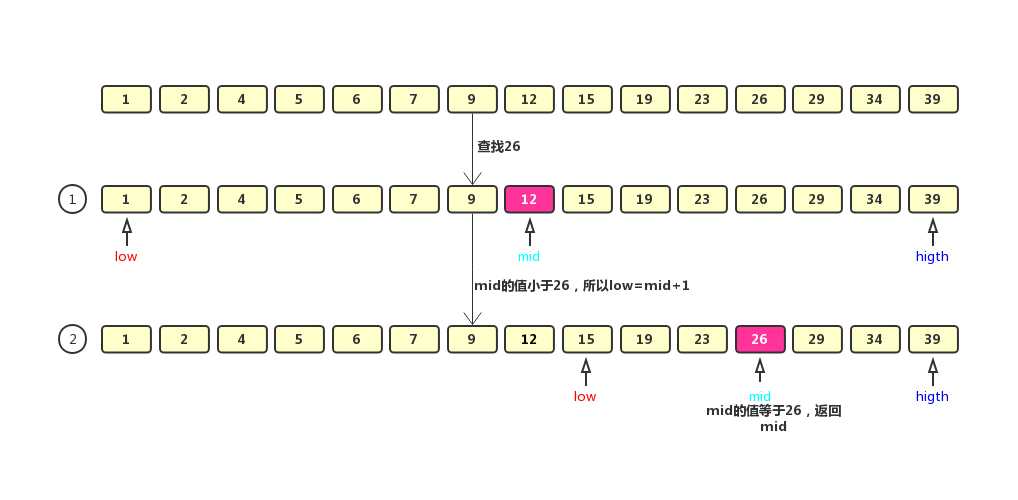
二分查找的过程就像上图一样,如果中间值大于查找值,则往数组的左边继续查找,如果小于查找值这往右边继续查找。二分查找的思想虽然非常简单,但是查找速度非常长,二分查找的时间复杂度为O(logn)。虽然二分查找的时间复杂度为O(logn)但是比很多O(1)的速度都要快,因为O(1)可能标示一个非常大的数值,比例O(1000)。我们来看一张二分查找与遍历查找的效率对比图。

图片来源网络
从图中可以看出二分查找用了三步就找到了查找值,而遍历则用了11步才找到查找值,二分查找的效率非常高。但是二分查找的局限性非常大。那二分查找有哪些局限性呢?
局限性
二分查找依赖数组结构
二分查找需要利用下标随机访问元素,如果我们想使用链表等其他数据结构则无法实现二分查找。
二分查找针对的是有序数据
二分查找需要的数据必须是有序的。如果数据没有序,我们需要先排序,排序的时间复杂度最低是 O(nlogn)。所以,如果我们针对的是一组静态的数据,没有频繁地插入、删除,我们可以进行一次排序,多次二分查找。这样排序的成本可被均摊,二分查找的边际成本就会比较低。
但是,如果我们的数据集合有频繁的插入和删除操作,要想用二分查找,要么每次插入、删除操作之后保证数据仍然有序,要么在每次二分查找之前都先进行排序。针对这种动态数据集合,无论哪种方法,维护有序的成本都是很高的。
所以,二分查找只能用在插入、删除操作不频繁,一次排序多次查找的场景中。针对动态变化的数据集合,二分查找将不再适用
数据量太小不适合二分查找
如果要处理的数据量很小,完全没有必要用二分查找,顺序遍历就足够了。比如我们在一个大小为 10 的数组中查找一个元素,不管用二分查找还是顺序遍历,查找速度都差不多,只有数据量比较大的时候,二分查找的优势才会比较明显。
数据量太大不适合二分查找
二分查找底层依赖的是数组,数组需要的是一段连续的存储空间,所以我们的数据比较大时,比如1GB,这时候可能不太适合使用二分查找,因为我们的内存都是离散的,可能电脑没有这么多的内存。
代码实现
二分查找可以使用循环或者递归来实现,我们来看看两种实现方式的代码。
循环
/**
* 循环版二分查找
*
* @param nums 数组
* @param n 数组长度
* @param value 要查找的值
* @return
*/
private static int bserach(int[] nums, int n, int value)
int low = 0;
int high = n - 1;
while (low <= high)
// 找出中间下标
int mid = low + ((high - low) >> 1);
if (nums[mid] > value)
high = mid - 1;
else if (nums[mid] < value)
low = mid + 1;
else
return mid;
return -1;
递归
/**
* 递归算法实现二分查找
*
* @param nums 数组
* @param low 左下标
* @param high 右下标
* @param value 要查找的值
* @return
*/
private static int recursiveBserach(int[] nums, int low, int high, int value)
if (low > high) return -1;
// 找出中间下标
int mid = low + ((high - low) >> 1);
if (nums[mid] == value)
return mid;
else if (nums[mid] > value)
return recursiveBserach(nums, low, mid - 1, value);
else
return recursiveBserach(nums, mid + 1, high, value);
二分查找的代码实现起来比较简单,需要说明的地方是中间值的计算,中间值得计算有两种方式,方式一:int mid = (low +high)>>1,方式二:int mid = low + ((high - low) >> 1)。方式一存在溢出的风险,当low和high比较大时,有可能会导致mid的值错误,从而使程序出错。方式二则可以保证生成的mid一定大于low,小于high。
上面的二分查找比较简单,我们来看看变形的二分查找。
查找第一个等于给定值的元素
比如我们给定数组1,2,3,4,4,4,5,6,7,7,8,9,我们需要查找第一个等于4的元素。
/**
* 查找第一个等于给定值的元素
*
* @param nums
* @param length
* @param value
* @return
*/
private static int bsearchFirstValue(int[] nums, int length, int value)
int low = 0;
int high = length - 1;
while (low <= high)
int mid = low + ((high - low) >> 1);
if (nums[mid] > value)
high = mid - 1;
else if (nums[mid] < value)
low = mid + 1;
else
// 判断当前是第一个元素或者前一个元素不等于要查找的值,则返回下标,如果前一个元素也等于要查找的值,则继续往前查找。
if ((mid == 0) || (nums[mid - 1] != value)) return mid;
else high = mid - 1;
return -1;
其他的都差不多,主要的区别是在nums[mid]==value时候,因为我们要查找的是第一个等于给定值的元素,所以我们需要判断mid的前一个元素等不等于给定值,如果前一个元素也等于给定值,则需要继续往左边查找。
查找第一个大于给定值的元素
比如我们给定数组1,2,3,4,4,4,5,6,7,7,8,9,15,26,34,45,我们随便输入一个值,这个值可以是数组里面的值,也不可不在数组里面,查找出第一个比给定值大的元素。
/**
* 查找第一个大于给定值的元素
*
* @param nums 数组
* @param length 数组的长度
* @param value 给定的值
* @return
*/
private static int bserachFirstOverVlaue(int[] nums, int length, int value)
int low = 0;
int high = length - 1;
while (low <= high)
int mid = low + ((high - low) >> 1);
if (nums[mid] > value)
// 判断当前是第一个元素或者前一个元素小于等于给定值,则返回下标,如果前一个元素大于给定的值,则继续往前查找。
if ((mid == 0) || nums[mid - 1] <= value) return mid;
else high = mid - 1;
else
low = mid + 1;
return -1;
我们需要判断当nums[mid] > value时,nums[mid-1]是否小于或者等于给定值,如果是则mid就是第一个大于给定值的元素,如果不是这继续往左边查找。
以上就是关于二分查找的相关知识,二分查找虽然性能比较优秀,但应用场景也比较有限,底层必须依赖数组,并且还要求数据是有序的。所以我们在选用算法时需要从多方面考虑。
个人公众号

以上是关于程序员,你应该知道的二分查找算法的主要内容,如果未能解决你的问题,请参考以下文章