使用neo4j图数据库的import工具导入数据 -方法和注意事项
Posted jpfss
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用neo4j图数据库的import工具导入数据 -方法和注意事项相关的知识,希望对你有一定的参考价值。
背景
最近我在尝试存储知识图谱的过程中,接触到了Neo4j图数据库,这里我摘取了一段Neo4j的简介:
Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
在下载了Neo4j Server(3.4.1)以后,我开始着手把手头的三元组数据存储进neo4j的数据库中,用的是python的py2neo库,我的思路是:读取文件,将每行的实体抽取出来,在图中查找是否有该(两个)实体节点,如果不存在就插入节点,然后插入该行三元组表示的边。
但是这样做的效率很低(我的图要至少连续一个月才能存完)。我分析了一下,原因在于:每次插入实体节点都需要先查询图中是否存在该实体节点,随着图的增大,查询所需的时延也越来越长。
在查了官方文档以后,我找到了一个高效率的导入数据的方法–neo4j的import工具,这里我将我在导入过程中遇到的问题和我的解决方案和分析分享出来,供大家参考。
导入方法
import工具命令为如下格式:
neo4j-admin import [--mode=csv] [--database=<name>]
[--additional-config=<config-file-path>]
[--report-file=<filename>]
[--nodes[:Label1:Label2]=<"file1,file2,...">]
[--relationships[:RELATIONSHIP_TYPE]=<"file1,file2,...">]
[--id-type=<STRING|INTEGER|ACTUAL>]
[--input-encoding=<character-set>]
[--ignore-extra-columns[=<true|false>]]
[--ignore-duplicate-nodes[=<true|false>]]
[--ignore-missing-nodes[=<true|false>]]
[--multiline-fields[=<true|false>]]
[--delimiter=<delimiter-character>]
[--array-delimiter=<array-delimiter-character>]
[--quote=<quotation-character>]
[--max-memory=<max-memory-that-importer-can-use>]
[--f=<File containing all arguments to this import>]
[--high-io=<true/false>]或:
neo4j-admin import --mode=database [--database=<name>]
[--additional-config=<config-file-path>]
[--from=<source-directory>]方括号内为可以选择的参数,其中我们常用的是第一种格式,即从独立的文件里导入图数据,常用参数为--nodes和--relationships,分别用来引入节点的CSV文件和边的CSV文件。
举个例子:
bin/neo4j-admin import --nodes <filepath of the csv file of nodes> --relationships <filepath of the csv file of relationships>1. 生成CSV文件
Neo4j的import工具要求数据使用CSV文件保存,因此在导入数据前需要将数据转乘CSV文件。节点和关系需要不同的文件,一种节点的CSV文件可以分为多个文件储存,传递参数的时候需要按顺序加上所有文件的文件名(绝对路径),工具读取第一个文件的表头作为节点/边的属性名,该文件剩下所有行以及后续文件的所有行作为属性值。多种节点(如包含不同属性集合)的导入需要分别为每一种节点分别引入(即使用多次--node参数)。
在我的需求中,节点和边都只包含一个名称(数据格式每行为<subject>\\t<predicate>\\t<object> .),因此我将节点和边分别仅用一个CSV文件储存,使用python的csv库,csv库写csv文件的方法为(以下代码不可执行):
import csv
csvf = open(filepath,‘w‘,newline=‘‘,encoding=‘utf-8‘)
w = csv.writer(csvf)
w.writerow((column_name_1, column_name_2, ...))#写入表头
for i in some_range:
w.writerow((column_1, column_2, ...))#写入行
csvf.close()注意,writerow传入的参数为含有多个字符串的tuple,而不是多个字符串。
我生成的CSV文件表头结构如下:
node.csv: name:ID(node), :LABEL
rel.csv: :START_ID(node), :END_ID(node), :TYPE,name
其中:
name:ID表示该列的属性名为name,ID
表示该属性是唯一标示一个实体的属性(类似关系型数据库中的主码),括号表示一个id-group,即表示该ID唯一表示括号内种类的实体,而不是所有实体;:LABEL表示节点的标签;START_ID和END_ID表示边的起点和终点的ID,可以加上它们各自的id-group;:TYPE表示该边的种类,注意种类个数不应超过65535。
2.使用import指令导入
在CSV文件准备就绪以后,打开电脑的终端,执行:
1.改变工作目录至Neo4j的根目录,(打开该目录以后应当能看到bin, conf, data, import, lib等文件夹):
cd filepath_to_neo4j_home_directory2.运行neo4j-admin import指令,注意:
在此之前应当保证在Neo4j的目录下的data/databases/graph.db 下没有文件,即该指令要求数据库为空;
Neo4j应当关闭,处于stopped状态(关闭方法:终端在Neo4j的根目录执行./bin/neo4j stop),
--nodes 和--relationships 后的文件名应当是绝对路径。
bin/neo4j-admin import --nodes some_path_to/node.csv --relationships some_path_to/rel.csv不出意料,该指令执行结果是:
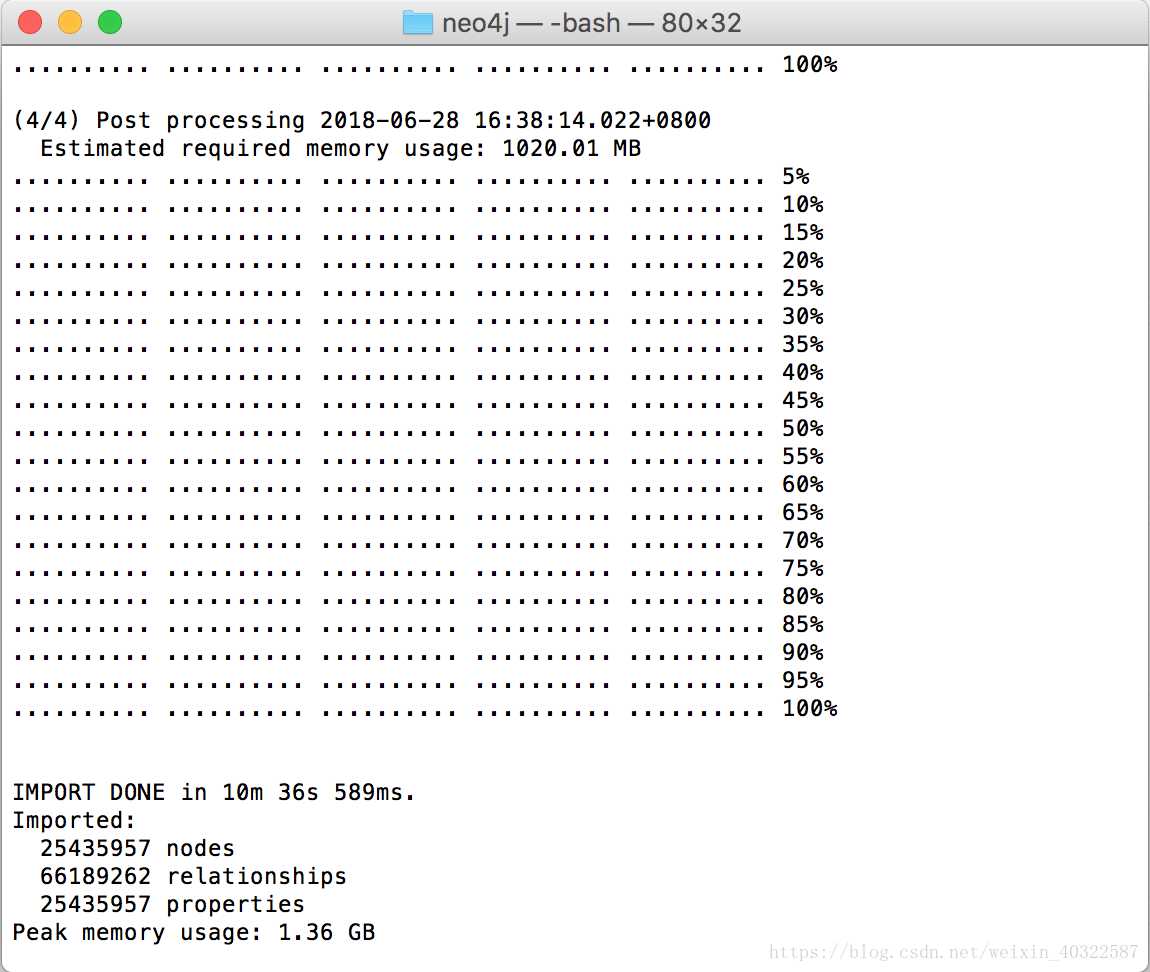
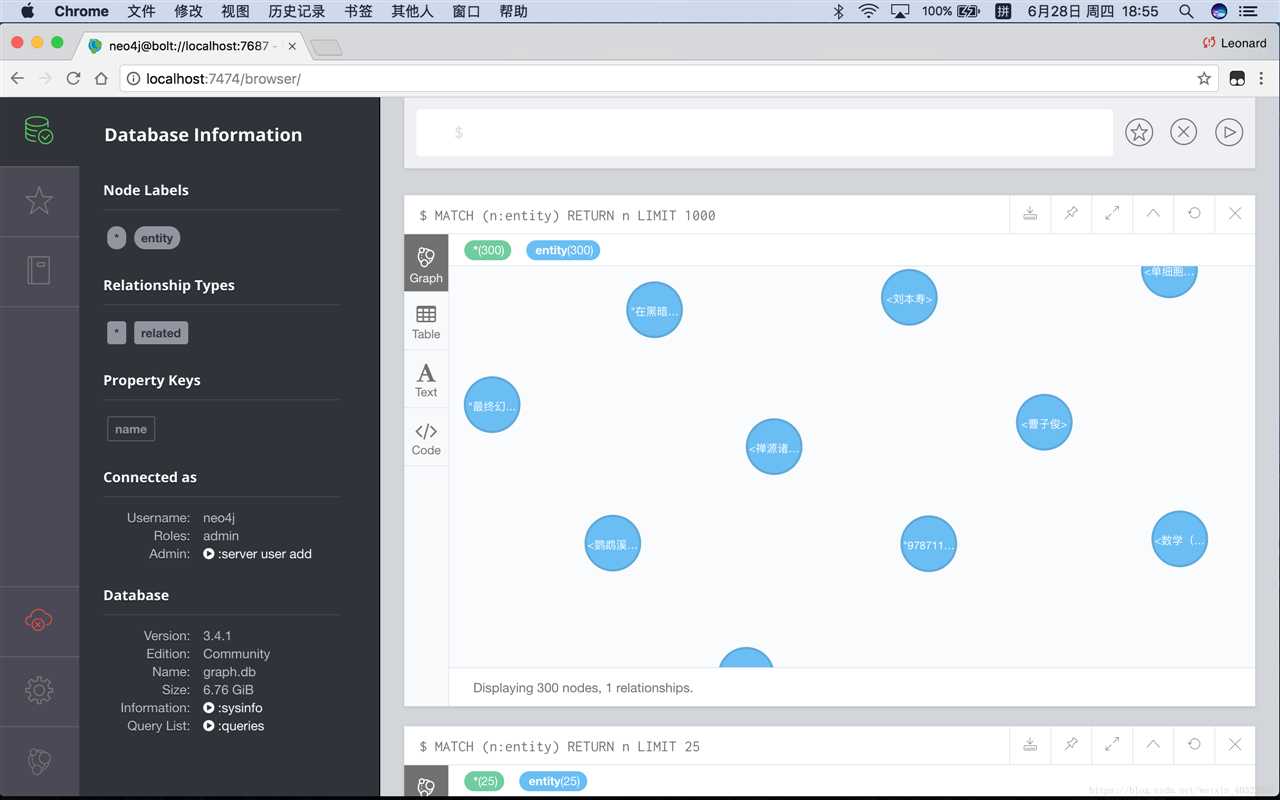
3.重新启动Neo4j,进入浏览器输入IP+端口(默认为http://localhost:7474/)查看结果,启动的指令是:
./bin/neo4j start如果正确操作,且不出意外的话,在浏览器中应当能查询正确导入的图谱:
总结&注意事项
1.传入文件名的时候务必使用绝对路径,否则将会抛出以下错误:
Expected ‘--nodes‘ to have at least 1 valid item, but had 0 []Expected ‘--relationships‘ to have at least 1 valid item, but had 0 []2.使用neo4j-admin import指令导入之前先将原数据库从neo4j_home/data/databases/graph.db/中移除,即指令要求目录下不含数据库,否则指令无法执行;
3.在执行指令之前务必保证Neo4j处于关闭状态,如果不确定可以在Neo4j根目录下运行./bin/neo4j status 查看当前状态。如果数据库未关闭,可能会导致数据库即使成功导入,也无法查询到(我的经验是这样);
4.写CSV文件的时候务必确保所有的节点的CSV文件的ID fileds的值都唯一、不重复(类似SQL中的primary key),并且确保所有的边的CSV文件的START_ID 和 END_ID都包含在节点CSV文件中(参考SQL中的referential integrity constraint);
5.若要使用其他参数请参考官方的文档,我在下面的References中给出;
6.我的Neo4j运行环境是OS X系统,如果你使用的是其他操作系统,指令可能有所不同,比如启动和终止服务的指令。
References:
[1]https://neo4j.com/developer/guide-import-csv/
[2]https://neo4j.com/docs/operations-manual/current/tutorial/import-tool/
以上是关于使用neo4j图数据库的import工具导入数据 -方法和注意事项的主要内容,如果未能解决你的问题,请参考以下文章