# [爬虫Demo] pyquery+csv爬取猫眼电影top100
Posted sstealer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了# [爬虫Demo] pyquery+csv爬取猫眼电影top100相关的知识,希望对你有一定的参考价值。
[爬虫Demo] pyquery+csv爬取猫眼电影top100
站点分析
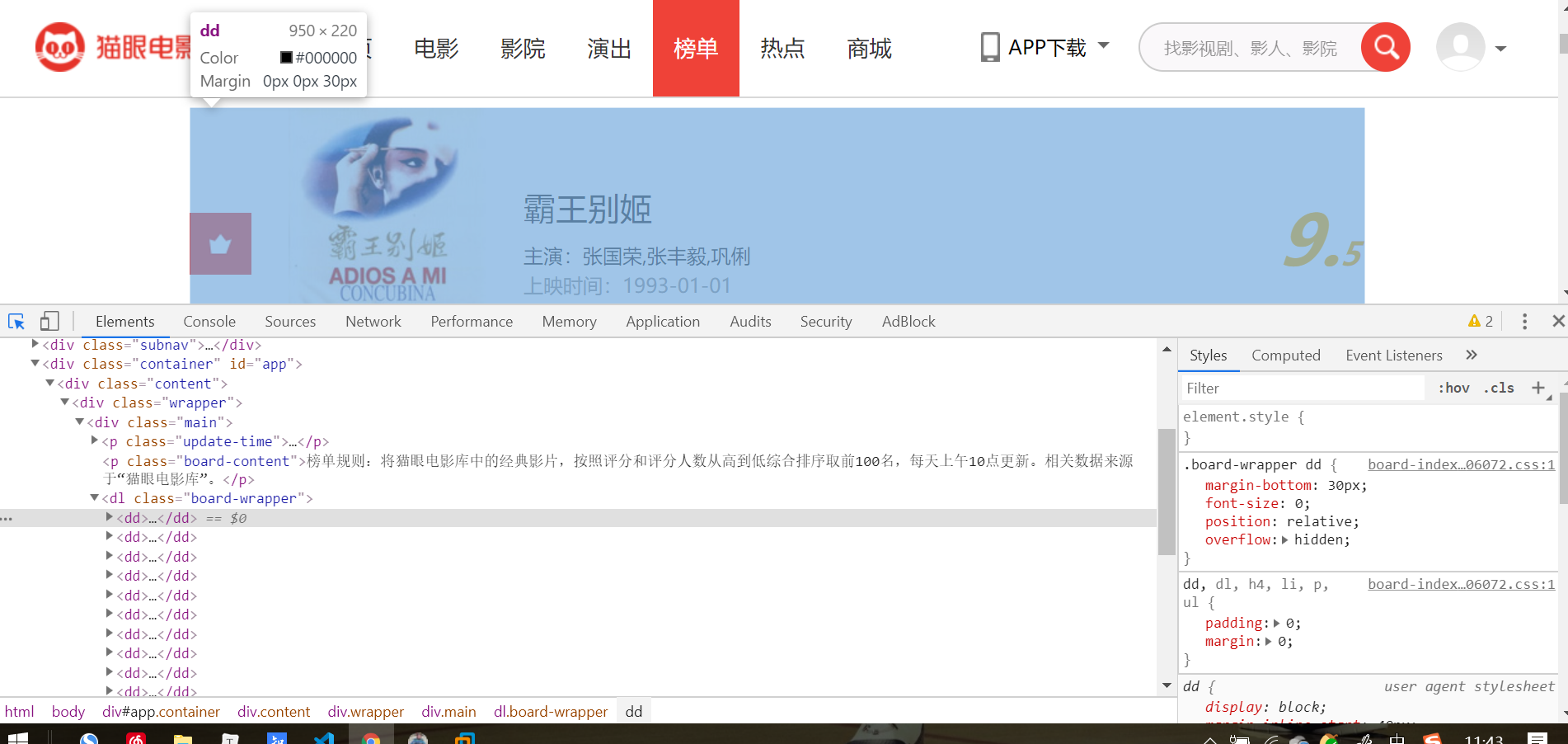
https://maoyan.com/board/4?offset=0
翻页操作只会改变offset偏移量,每部电影的信息都在dd标签内,使用pyquery库中的css选择器直接解析页面
代码君
- css选择器直接选择和使用find()方法的区别:find()用于选择子节点,因此限定了选择的区域,速度可能要快些,直接传入
‘’选择器可能要全盘扫描(这里只是为了我自己方便记忆,信息可能有误,欢迎指出) - 一般先直接传入选择器选择出包含所需信息的大标签,再使用find()选择大标签里面的细节信息
- 还有需要注意的一点是,不能直接在Elements选项卡中直接查看源码,那里的源码可能经过javascript渲染而与原始请求不同,而是需要从Network选项卡部分查看原始请求得到的源码
使用csv格式存储:相比txt格式,csv格式更利于数据存储和处理,大规模数据可以使用数据库存储
#use pyquery get the data and save as csv
from pyquery import PyQuery as pq #as是为PyQuery类取一个别名
import csv
import time
begin=time.clock() #添加程序开始时间
def get_page(url):
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
#添加头部信息,防止被网站识别出是python爬虫而被禁止访问
doc=pq(url,headers=headers)
return doc
def parse_page(doc):
dict=
dd=doc('.board-wrapper').find('dd')
'''yield在函数中的功能类似于return,不同的是yield每次返回结果之后函数并没有退出,而是每次遇到yield关键字后返回相应结果,并保留函数当前的运行状态,等待下一次的调用。如果一个函数需要多次循环执行一个动作,并且每次执行的结果都是需要的,这种场景很适合使用yield实现。'''
for item in dd.items():
yield #返回一个字典
'rank':item.find('.board-index').text(),
'name':item.find('.name').text(),
'img':item.find('.board-img').attr('data-src'),
'star':item.find('.star').text(),
'time':item.find('.releasetime').text().strip(),#strip()转化为字符串去除前后空格,strip()[3:]表示从取下标从3的位置开始到文件结尾
'score':item.find('.score').find('.integer').text().strip()+item.find('.score').find('.fraction').text().strip(),
def write_to_file(item): #接收一个字典
writer.writerow((item['rank'],item['name'],item['img'],item['star'],item['time'],item['score']))
def main():
for i in range(10):
url='https://maoyan.com/board/4?offset='+str(i*10)
doc=get_page(url)
#print(doc)
for item in parse_page(doc):
print(item)
write_to_file(item)
#线程推迟1s,一些反爬取网站,如果速度过快会无响应,故增加一个延时等待
time.sleep(1)
if __name__ == '__main__':
f = open('test.csv', 'a', newline='', encoding='utf-8')
writer = csv.writer(f)
writer.writerow(('Rank','Name','Picture','Star','Time','Score'))#写入头部信息
main()
f.close() #手动关闭文件对象
end=time.clock() #添加程序结束时间
# 输出CPU耗时,不包括线程推迟的时间,是正常情况下(不考虑等待)程序的耗时
print("爬取完毕,CPU耗时:%f s"%(end-begin))使用文本txt格式存储
'''pyquery get the data and save as txt'''
import json
import time
import requests
from pyquery import PyQuery as pq
def get_page(url):
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
doc=pq(url)
return doc
def parse_page(doc):
dd=doc('.board-wrapper').find('dd')
for item in dd.items():
yield
'index': item.find('.board-index').text(),
'image': item.find('.board-img').attr('data-src'),
'title': item.find('.name').text(),
'actor': item.find('.star').text().strip()[3:],
'time': item.find('.releasetime').text(),
'score': item.find('.score').find('.integer').text().strip() + item.find('.score').find(
'.fraction').text().strip()
def write_to_file(item):
with open('test.csv','a',encoding='utf-8') as f:
f.write(json.dumps(item,ensure_ascii=False)+'\n')#False表示不使用ascii表示中文,可以直接显示中文
def main():
for i in range(10):
url = 'https://maoyan.com/board/4?offset='+str(i*10)
doc=get_page(url)
for item in parse_page(doc):
print(item)
write_to_file(item)以上是关于# [爬虫Demo] pyquery+csv爬取猫眼电影top100的主要内容,如果未能解决你的问题,请参考以下文章