推荐系统中召回策略
Posted graybird
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统中召回策略相关的知识,希望对你有一定的参考价值。
推荐系统一般分为两个阶段,即召回阶段和排序阶段。召回阶段主要是从全量的商品库中得到用户可能感兴趣的一小部分候选集,排序阶段则是将召回阶段得到的候选集进行精准排序,推荐给用户。
推荐系统中几种常用的召回策略。主要有协同过滤、向量化召回和阿里最近在Aicon中提到的深度树匹配模型。
1、协同过滤
协同过滤主要可以分为基于用户的协同过滤、 基于物品的协同过滤、基于模型的协同过滤(如矩阵分解)
1.1 基于用户的协同过滤(userCF)
基本思想:当召回用户A的候选集时,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的、而用户A未交互的物品作为候选集。
1.2 基于物品的协同过滤(itemCF)
基本思想:给用户推荐那些和他们之前喜欢的物品相似的物品。
主要分为两步:
(1) 计算物品之间的相似度。
(2) 根据物品的相似度和用户的历史行为给用户生成召回候选集。
1.3 UserCF和ItemCF的比较
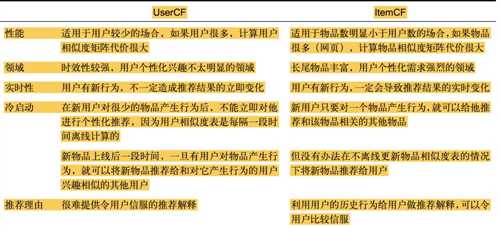
1.4 协同过滤总结
协同过滤方法通过在用户历史行为里面找相似的商品和用户,保证了基础的相关性。与此同时,因为只找相似的商品或相似用户的商品,所以系统屏蔽了大规模的计算,使整个召回的过程能够高效地完成。
弊端:在召回的时候,并不能真正的面向全量商品库来做检索,如itemCF方法,系统只能在用户历史行为看过的商品里面找到侯选的相似商品来做召回,使得整个推荐结果的多样性和发现性比较差。这样做的结果就是,用户经常抱怨:为什么总给我推荐相同的东西!
2、向量化召回
向量化召回,主要通过模型来学习用户和物品的兴趣向量,并通过内积来计算用户和物品之间的相似性,从而得到最终的候选集。其中,比较经典的模型便是Youtube召回模型。
2.1 Youtube召回模型
论文解读:https://www.jianshu.com/p/8fa4dcbd5588
Youtube召回模型的架构如下:
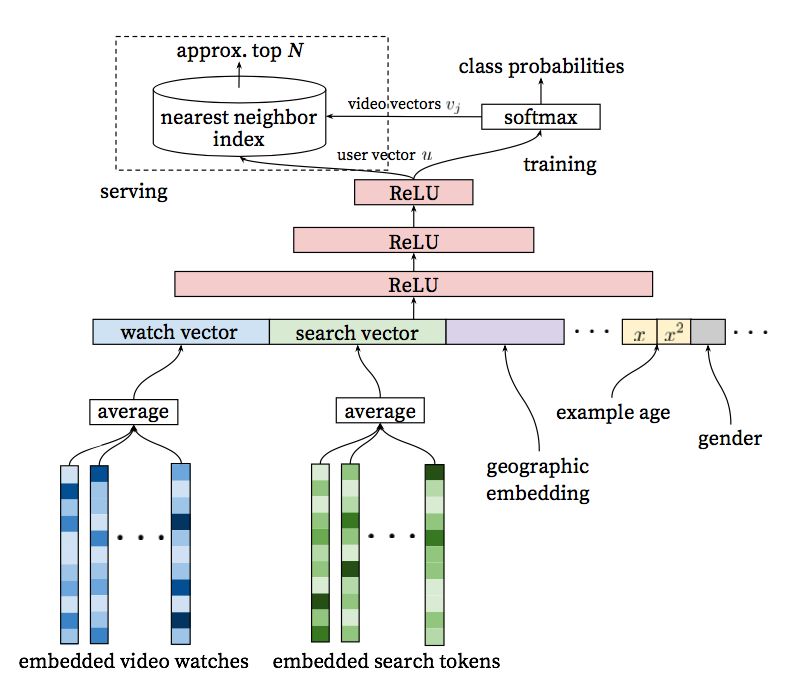
从模型结构可以看出,在离线训练阶段,将其视为一个分类问题。我们使用隐式反馈来进行学习,用户完整观看过一个视频,便视作一个正例。如果将视频库中的每一个视频当作一个类别,那么在时刻t,对于用户U和上下文C,用户会观看视频i的概率为:
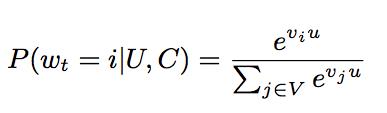
其中,u是用户的embedding,这个embedding,是网络最后一个Relu激活函数的输出,vi是视频i的embedding。那么问题来了,输入时,每一个视频也有一个对应的
embedding,这个embedding是不是计算softmax的embedding呢?个人认为是两组不同的embedding,输入层的embedding分别是用户空间和视频空间的向量,最终的
输出层,二者通过一系列全联接层的线性变化,转换到了同一空间,所以对于用户和视频来说,输出层的embedding是同一空间,可以认为是兴趣空间,这样二者的内积可
以代表相似性。
使用多分类问题的一个弊端是,我们有百万级别的classes,模型是非常难以训练的,因此在实际中,Youtube并使用负样本采样(negative sampling)的方法,将class的数量减小。对于在线服务来说,有严格的性能要求,必须在几十毫秒内返回结果。因此,youtube没有重新跑一遍模型,而是通过保存用户兴趣embedding和视频兴趣embedding,通过最近邻搜索的方法得到top N的结果。该近似方法中的代表是局部敏感Hash方法。
2.2 局部敏感哈希(Locality-Sensitive Hashing, LSH)
LSH的基本思想:我们首先对原始数据空间中的向量进行hash映射,得到一个hash table,我们希望,原始数据空间中的两个相邻向量通过相同的hash变换后,被映射到同一个桶的概率很大,而不相邻的向量被映射到同一个桶的概率很小。因此,在召回阶段,我们便可以将所有的物品兴趣向量映射到不同的桶内,然后将用户兴趣向量映射到桶内,此时,只需要将用户向量跟该桶内的物品向量求内积即可。这样计算量被大大减小。
关键的问题是,如何确定hash-function?在LSH中,合适的hash-function需要满足下面两个条件:
1)如果d(x,y) ≤ d1, 则h(x) = h(y)的概率至少为p1;
2)如果d(x,y) ≥ d2, 则h(x) = h(y)的概率至多为p2;
其中d(x,y)表示x和y之间的距离, h(x)和h(y)分别表示对x和y进行hash变换。
满足以上两个条件的hash function称为(d1,d2,p1,p2)-sensitive。而通过一个或多个(d1,d2,p1,p2)-sensitive的hash function对原始数据集合进行hashing生成一个或多个hash table的过程称为Locality-sensitive Hashing。
2.3 向量化召回评价
向量化召回是目前推荐召回核心发展的一代技术,但是它对模型结构做了很大的限制,必须要求模型围绕着用户和向量的embedding展开,同时在顶层进行内积运算得到相似性。在深度学习领域其实模型结构层出不穷,百花齐放,但是这样一个特定的结构实际上对模型能力造成了很大的限制。
3、深度树匹配
参考:https://blog.csdn.net/leadai/article/details/89391366
以上是关于推荐系统中召回策略的主要内容,如果未能解决你的问题,请参考以下文章