指令选择器调查(7完)
Posted wuhui_gdnt
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了指令选择器调查(7完)相关的知识,希望对你有一定的参考价值。
6. 模拟
指令选择器的最后一个分类是那些通过分析及比较一条指令在目标机器上的作用,决定选择哪条指令。与输入程序给定部分具有相同作用的一条指令是兼容的,因此该部分可由这条指令来达成(参考图6.1)。我们称这些概念为模拟(simulation)。模拟与基于覆盖方法间的一个关键区别是,在输入程序不能观察到所有输出模式(即模式不是确切匹配输入图)时,后者通常不能利用具有多个输出的模式。相反,基于模拟的做法能够忽略这些不可见的影响。事实上,几个这些模拟方法在内部应用覆盖技术以确定相容性。
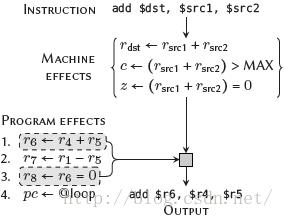
图6.1:加法指令的效果可以如何模拟,以在一个输入程序上执行指令选择的例子。
模拟的思想可以直接应用于汇编程序,即比较一个机器指令序列是否等效于单个复杂机器指令。如果单个指令的开销比长序列的开销小,那么替换它将产生该程序的一个改进。这样的优化程式,称为窥孔优化器,首先被用作一个代码生成后步骤(post-code generation step)以提高代码指令,但我们将看到如何可以改造这个技术来执行指令选择。
6.1. 窥孔优化
一个早期——但仍然在应用的——提升代码质量的方法是在生成代码中执行局部检查,力图改进低效的指令序列。这个早在1965年McKeeman就主张【171】的技术,称为窥孔优化,因为在其分析的任何时间,该优化例程通常局限于程序一个很窄的窗口。最简单的窥孔优化器在汇编代码中检查特定的线性指令序列,以更廉价的等价物来替换它们。因此这样的优化器在代码已经被流出后,但在链接器运行前执行。第一批实现,就像最早的指令选择器,通常是手写并为特定的目标架构特别设计。
在1979年Fraser【96】展示了这样的优化例程减少重指向开销的第一个做法(这也在Davidson与Fraser【62】在更长的一篇论文里描述了)。不是把目标汇编指令编码进优化器,Fraser开发了一个窥孔优化器,称为PO,从一个符号化的机器描述提取这些知识。这个描述通过描述一条指令对机器寄存器的作用,定义了它的语义。Fraser称这些作用为寄存器传输,因此每条指令具有一个相应的寄存器传输模式或寄存器传输列表(RTL)。在这篇报告里我们将始终使用后者。例如,这个形式的3地址中间加法指令的RTL
add $r[d], $r[s], #imm
它还设置一个0符号Z,将是
rd ← rs+ imm; Z ← rs + imm = 0
为了处理跳转指令,这个做法假定机器使用一个跳转时会设置的程序计数器。它进一步假设寄存器不受程序外部事件的影响。
PO通过综合邻接指令对的效果,然后检查是否存在单条可以导致相同结果的指令(通过一系列字符串比较)来改进给定的汇编程序。如果找到了这样一条指令,替换这个指令对。这个实现是简单的。在输入程序上进行一个第一次后向遍来确定每条指令的作用。这个遍向后忽略对程序行为没有影响的结果(即一个条件标记的值是不可见的,如果没有后续使用它的指令,或者它被其他指令改写了)。后跟一个第二遍,它合并了两条字母序相邻指令的效果,并查找带有相匹配效果的单条指令。如果替换了,优化器后退以检查新指令与其邻居的组合。这样多个单条指令可以通过级联替换来合并,但这要求存在实现每个中间替换步骤效果的指令。
尽管先进,PO也有几个局限。主要的缺点是它仅能处理两条指令的组合,而且在输入代码中这些指令必须字母序相邻。也不允许指令对越过标记边界(即属于不同的基本块)。后来Davidson与Fraser【60】通过在数据流图而不是直接在文本输入上构建及操作,消除了字母序相邻的限制。他们还把指令组合从对扩展到了三元组。
已经有许多技术专门致力于改善窥孔优化,我们将仅简单论及某些多年来做出的进步。Giegerich【109】开发了一个形式化的做法,消除了窄窗口的需求。Kessler【144】提出了一个方法,在编译器构建时完成模拟,因此减少了编译时间。后来Kessler将在【143】的做法扩展到长度为n的指令窗口,虽然是指数级开销。Massalin【170】开发了实现在Superoptimizer的一个算法,它详尽地组合了机器指令序列以找出实现了与给定汇编程序相同行为的最小程序。后来Granlund与Kenner【118】采纳了Massalin的工作,从给定的汇编程序中消除跳转。两者都不保证确性,因此要求人工检查任何要执行的优化。最近,Joshi等【134,135】提出了一个方法帮助自动化编写特别的优化例程过程。不像之前的优化器,他们的算法通过使用SAT解决的自动定理证明,找出给定程序的最优实现。不过,这是一个指数级开销。
6.2. 通过窥孔优化的指令选择
在1984年,Davidson与Fraser【60】将窥孔优化的思想整合进执行指令选择。该思想首先使用宏展开流出指令代码,然后通过窥孔优化后续优化它。当时树匹配算法仍然在开发,这个做法使用了更为成熟的技术。现在这个做法被称为Davidson-Fraser方法,显示在图6.2里。

图6.2:Davidson-Fraser指令选择方法的概览(来自【60】)
这个指令选择器包含两个部分:一个扩展器及一个组合器。扩展器的任务是使用寄存器传递实现中间形式的输入程序。这个做法假定一个不变量,称为机器不变量,即每个RTL必须可由至少一条机器指令实现。组合器的任务是将多个RTL组合为一个也可由某条机器指令实现的更大的RTL。这步通过我们前面讨论的窥孔优化来完成。因为代码将由组合器改进,扩展器可由简化为一个简单的一对多映射器,将一个IR操作转换为许多连续的RTL。例如,一个内存到内存的移动
$m[@a + 8] ← $m[@a + 12]
可以被扩展为以下的RTL,每个仅包含一个操作:
r1 ← 12
r2 ← @a + r1
r3 ← $m[t2]
r4 ← 8
r5 ← @a + r4
$m[t5] ← r3
这样的映射器通常使用宏扩展来实现,一个我们之前就知道实现与重指位都很简单的技术(参考第二章)。
Davidson与Fraser在他们的YC编译器中实现了这个做法——它还在RTL层次执行公共子表达式消除(参考Davidson与Fraser【61】)——但他们不是第一个这样做的。类似的,一开始流出低效的代码,然后改进它的更早期的策略被Auslander与Hopkins【21】以及Harrison【123】采用。不过,Davidson与Fraser坚持在可重指向性及代码质量间合适的平衡,使得他们的做法超过了之前的尝试。这个技术随后的实现在由Appel等开发的Zephyr/VPO系统【14】,由Tanenbaum等开发的Amsterdam Compiler Kit(ACK)及gcc(在【146,214】中讨论)这个最著名应用中。
与在本报告中讨论的其他做法相比,Davidson-Fraser做法的优点是其可扩展的机器指令支持。例如,对比基于树覆盖及DAG覆盖的做法,应用Davidson-Fraser技术的指令选择器可以更容易地处理跳转及多个输出的机器指令。这是可能的,因为组合器可以分析任何指令组合,潜在地跨过基本块边界。不过为了适用,某些指令可能要求一个过分大的指令窗口。另外,为机器指令建模的寄存器传递列表排除了基于循环的机器指令,因为没有处理指令内循环的概念。因此,虽然窥孔优化器在理论上可用于非常复杂的机器指令,在实践中这样做的代价通常太高了。此外,不确定这些类型的指令选择器是否能够适用于产生最优代码。
Dias及Ramsey采用了与Davidson-Fraser方法稍微不同的做法。在Davidson-Fraser的做法里,机器不变量通过每个优化例程来强制实施。相反,Dias与Ramsey采用了一个检查优化步骤是否违反该不变量的识别器(参考图6.3)。如果违反,拒绝该优化,回滚汇编代码。这简化了优化例程,因为它们不再需要担心遵守这个不变量。在【66】Dias与Ramsey展示了如何自动地从一个以λ-RTL编写的声明性机器模式产生这个识别器。由Ramsey与Davidson【192】开发的λ-RTL是一个基于ML的高级、强类型、多态、纯函数式寄存器转移语言,它提高了编写寄存器传递列表的抽象层次。它是一个称为计算机系统描述语言(CSDL)框架的部分,这个框架是致力于自动化生成有用编译器工具的Zephyr/VPO系统的部分。通过将RTL从机器描述转换为线性化树模式生成这个识别器。因此检查一个RTL是否满足该机器不变量简化为一个存在高效算法的树模式匹配问题(参考第三章)。虽然这将识别器局限于在一个语法尺寸上推理RTL,效率的需求阻止了更昂贵的语法分析(记得对于每个要执行的优化步骤都需要查询识别器)。
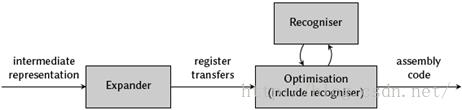
图6.3:Dias与Ramsey对Davidson-Fraser方法改编的概览(来自【66】)
后来Dias与Ramsey【65,193】开发了一个设计,减少了新目标机器,比如X86与PowerPC,甚至每个新架构族,比如基于寄存器及基于栈的机器,手动重指向的工作量。这个思想在于一组预定义的,特定于一个特定目标架构族的覆瓦(tiles)。一个覆瓦代表一个属于该架构族任何机器上必须的简单操作。例如,基于栈的机器要求push与pop操作的覆瓦,它们在具有寄存器的机器上不是必须的。现在,不是在输入程序中将每个IR节点展开一系列RTL,扩展器将其扩展为一系列的覆瓦。因为覆瓦集对同一个族的每个机器都是相同的,实现的正确性仅需要被证明一次。在他们的工作中,Dias与Ramsey使用一个了贪婪的(maximum-munch)树覆盖方法(参考第三章)来实现扩展器。假定合并器可以很好地改进流出代码,指令选择问题被归约为选择合适的机器指令来实现每个覆瓦。幸运地,Dias与Ramsey发现这个过程可以被自动化。通过使用λ-RTL描述覆瓦集机器指令,Dias与Ramsey开发了一个技术,其中机器指令的RTL被合并,使得效果等同于一个覆瓦的RTL。直觉是维护一个RTL池,然后使用顺序和代数法则迭代地增长它,直到实现所有的覆瓦,或到达某个终止条件。后者是必须的,因为Dias与Ramsey证明查找一个覆瓦的实现是不可判定的(即没有算法可以保证对所有可能的覆瓦能终止且找到一个实现)。
Dias与Ramsey方法比之Davidson与Fraser方法——及其他许多方法的主要优点,就此而言,是基于λ-RTL的机器描述比例如gcc的要更短、更简单。此外,声明性的描述更精确、明白,使得自动验证指令说明成为可能(参考Fernández与Ramsey【89】以及Bailey与Davidson【22】)。不过,因为Dias与Ramsey的工作在于促进可重指向性,它并不必然提高代码指令。此外,λ-RTL也不能用于一条机器指令内循环的建模。
6.3. 其他基于模拟的做法
在他们的调查论文里Ganapathi等【108】讨论了一个称为UGEN的代码生成器,它跟踪每个IR节点在一个虚拟U代码机器【185】上的改变。使用预定义的纲要(schemata),代码生成器流出在目标机器上具有相同效果的代码。因此重指向的努力被隔离为重写纲要。不幸,UGEN没有更多的信息了,因为该论文缺少对这项工作的引用,并且在相关的文献中也没有被援引。
Fraser与Wendt【95】开发了一个方法,其中指令选择器在两步里生成。在第一步,指令选择器包含一系列switch语句以及实现一个简单宏展开器的goto语句。宏展开器一开始仅将输入DAG中的每个节点替换为单条机器指令。接着在一个仔细选择的训练集上执行它。同宏展开器合作,针对已发现的,可以在生成代码上执行的优化机会,一个可重指向窥孔优化器收集其追踪信息及统计数据。这通过内嵌在指令选择器中的函数调用来实现。基于这些结果,指令选择器被增强为带有条件语句以及额外的goto语句,这些语句实际上包含了选中的优化,因此消除了一个独立窥孔优化器的需要。另外,因为仅实现了被认为有用的优化,代码指令以最小的开销得到改善。后来Wendt【235】通过提供一个允许IR操作及表示目标机器指令为RTL的规范,改进了这个方法。这个系统可以自动地推导如何将每个IR映射为机器代码,一个之前的方法必须用手工实现的任务。这还演变为一个用于编写这样代码生成器的紧凑语言(参考Fraser【94】)。
Hoover与Zadeck【131】开发了一个称为TOAST(定制优化与语义翻译,Tailored Optimisation and Semantic Translation)的系统,尝试从一个给定的声明性机器描述,自动地生成整个编译器框架。至于指令选择他们应用了一个算法,对于输入中每个IR节点,递归地枚举机器指令的所有组合,其集合效果等同于那个节点的作用。如果由选中机器指令实现的操作覆盖了由该IR节点生成的RTL图,效果是相同的。通过检查剩下未覆盖的节点是否仍然可覆盖,应用一个启发式来约束查找空间。
6.4. 总结
在本章我们讨论了依赖于某种形式模拟的方法。在这样的做法中,通常使用精确捕捉了指令效果的寄存器传递列表(RTL)来描述机器指令。通过流出总体效果与输入IR效果相同的指令来执行指令选择。为了简化这个任务,首先以简捷、缺乏效率的方式完成代码流出,随后使用窥孔优化(这通常被称为Davidson-Fraser方法)来改进代码。窥孔优化器合并、比较,并使用单一等价对象替换多态指令,因此比基于树或DAG覆盖的指令选择器有更强的处理复杂指令能力。这是因为没有限制窥孔优化器将机器指令建模为限制图形。另一个结果是它看起来还使得基于模拟的指令选择器更容易重指向。不过,这样优化器的效率受该优化器一次可以分析的指令树的限制。此外,在当前基于RTL的做法中,用于机器指令建模的寄存器传递列表不能捕捉基于循环的机器指令的特性。
这些做法的另一个重要的缺点是没有尝试去生成最优代码。这应该要求,不清楚如何及它们是否可以扩展来实现这样一个目标。另外,基于Davidson-Fraser方法的代码质量关键依赖于窥孔优化器的效率,因此使得这些方法不可能用于高度受限的目标环境,比如DSP及嵌入式系统。
7. 结论
在本报告中我们考察并评估了所有现存、可以找到的关于指令选择的文献。该工作被分为5个部分——宏展开,树覆盖,DAG覆盖,图覆盖,以及模拟——它们都具有各自的优缺点。在附录C有一张图显示看每个类别的研究如何随时间进展的。我们已经看到这个领域如何从专有的、手写的一体程序开始,逐渐地在某种程度上,为更形式化的技术所替代。不仅最新的指令选择器产生更好的代码质量并扩展了对机器指令的支持,而且它们还改善了编译器的可重指向性,因为指令选择器的一大部分可以从一个声明性的机器描述自动生成。不过,这些新方法增强的能力和效能是以增加复杂性换来的。例如,随着输入表示从树转换到DAG,指令选择从一个可以在线性时间最优解决的任务变为一个NP完全问题。因为这本质上是一个困难的问题,大多数方法应用启发式来控制复杂度——许多以线性时间运行,并据报道通常生成近似最优的质量。
尽管这些巨大的进步,最先进的方法仍然具有几个重大的缺陷。最显著的缺点是,就我所知,没有一个能建模包含内部跳转或循环的机器指令。这通常包括实现了算术操作的指令,这些操作之前通过编译器固有函数(compiler intrinsics)及调用直接以汇编实现的库函数来处理。虽然这使得指令选择器部分地扩展了其对机器指令的支持,但这方法远不算理想;以新固有函数扩展编译器要求大量的人力;而且对每个目标机器都需要重写库函数。因此许多机器指令仍然没有完全支持,而是要求编译器开发者实现定制的例程以辅助指令选择器。另外,基于启发式的展开选择器通常依赖于目标机器的假设,使得它非常难重指向,以及为复杂的架构,比如DSP与嵌入式系统,生成高效代码。
另一个一再出现的限制是指令选择通常局限在基本块。考虑整个函数的方法——因而执行全局指令选择——开始出现,但这些通常受其他方面的限制,比如机器指令的支持。
最后,为了实现全局最优代码生成,必须同时考虑代码生成的所有三个方面。换而言之,最优指令选择如果孤立完成,本质上是徒劳的。例如,不考虑调度,有效利用条件代码(也称之为状态标记)是不可能的,因为必须确定这些标记没有过早地被其他指令改写。这同样适用于能并行执行多条指令的VLIW架构。另一个情形是重新实现(rematerialisation),其中选中的指令被允许重合,因而形成一种重复形式。在保存一个值于后面使用比重新计算它开销更大的情形下,这是有利的。不过,仅当减少的寄存器压力确实帮助了寄存器分配器,这才是有用的。在带有多个寄存器类别,对访问每个寄存器类别要求特殊指令集的目标机器里,指令选择与寄存器分配间的联系变得更为紧密。话虽如此,大多数现代的方法仅孤立地考虑指令选择,因此很难完整及有效地整合指令调度与寄存器分配。
尽管有这些问题,几个基于源自运筹学领域研究技术的方法显示出很大的前景。追求最优,这些想法通常也能处理更复杂的机器指令,以及可以扩展到考虑整个函数。特别的,新兴的研究针对基于约束规划的方法(参考Bashford与Leupers【24】,Kuchcinski【155】,及Castañeda Lozano等【39】)显示代码生成的各个方面可以被整合入一个单一约束模型,因为目标机器的任意限制可以很容易地被表示为额外的约束,以重指向性而言,它极端弹性及灵活的。不过,当前的实现通常比启发式的对手慢上一个数量级,这意味着它仍然是一个不成熟的技术,需要进一步的研究。
最后,虽然这个领域自1960年代肇始,已经有了长足的进步,指令选择仍然是——尽管有共识——一个难以理解的问题。另外,当前嵌入式系统、DSP与应用特定加速处理器更紧密结合的潮流意味着目标机器只会变得更复杂,而不是更简单。因此,以这个观点看来,指令选择比之以前更需要增加理解。
以上是关于指令选择器调查(7完)的主要内容,如果未能解决你的问题,请参考以下文章