JVM内存
Posted FindBetterMe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM内存相关的知识,希望对你有一定的参考价值。
JAVA能够实现跨平台的一个根本原因,是定义了class文件的格式标准,凡是实现该标准的JVM都能够加载并解释该class文件,据此也可以知道,为啥Java语言的执行速度比C/C++语言执行的速度要慢了,当然原因肯定不止这一个,如在JVM中没有数据寄存器,指令集使用的是栈来保存中间数据…等,尽管Java的贡献者们为执行速度的提高想了各种办法,如JIT、动态编译器等,以下是Leetcode中一道题目用不同的语言实现时的执行性能对比图…

以下是JVM的一个基本架构图,在这个基本架构图中,栈有两部份,Java线程栈以及本地方法栈,栈的概念与C/C++程序基本上都是一个概念,里面存放的都是栈帧,一个栈帧代表的就是一个函数的调用,在栈帧里面存放了函数的形参,函数的局部变量, 返回地址等,但是与C/C++的一个重要区别是,C/C++里面有传值以及传址的区别,当传的是一个对象时( 结构体也可以当成对象,其实就是对象~,只不过里面的方法默认都是public的,不信你可以试试,在结构体中加一个函数,编译器也不会报错,程序依旧运行~~~),会将对象复到到栈中,而Java中只有基本类型才是传值的,其他类型传的都是引用,什么是引用,学过C/C++的就把引用当作指针理解吧~~~,在这个基本架构图中,可以看出JVM还定义了一个本地方法栈,本地方法栈是为Java调用本地方法【这些本地方法是由其他语言编写的】服务的

上面的图中看到的是JVM中栈有两个,但是堆只有一个,每一个线程都有自已的线程栈【线程栈的大小可以通过设置JVM的-xss参数进行配置,32位系统下,JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K】,线程栈里面的数据属于该线程私有,但是所有的线程都共享一个堆空间,堆中存放的是对象数据,什么是对象数据,排除法,排除基本类型以及引用类型以外的数据都将放在堆空间中。其中方法区和堆是所有线程共享的数据区。
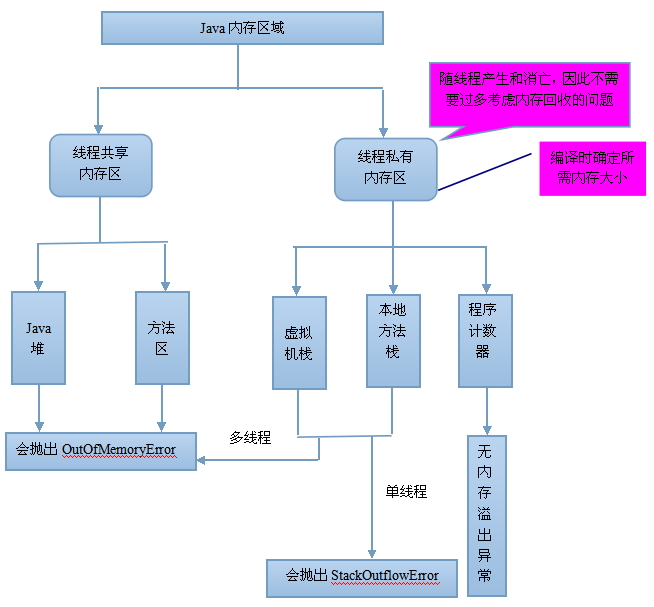
1.程序计数器
在CPU的寄存器中有一个PC寄存器,存放下一条指令地址,这里,虚拟机不使用CPU的程序计数器,自己在内存中设立一片区域来模拟CPU的程序计数器。只有一个程序计数器是不够的,当多个线程切换执行时,那就单个程序计数器就没办法了,虚拟机规范中指出,每一条线程都有一个独立的程序计数器。注意,Java虚拟机中的程序计数器指向正在执行的字节码地址,而不是下一条。
2. Java虚拟机栈
Java虚拟机栈也是线程私有的,虚拟机栈描述的是Java方法执行的内存模型:每个方法执行的时候都会创建一个栈帧,用于存放局部变量表,操作数栈,动态链接,方法出口等信息。每一个方法从调用直到执行完成的过程都对应着一个栈帧在虚拟机中的入栈到出栈的过程。我们平时把内存分为堆内存和栈内存,其中的栈内存就指的是虚拟机栈的局部变量表部分。局部变量表存放了编译期可以知道的基本数据类型(boolean、byte、char、short、int、float、long、double),对象引用(可能是一个指向对象起始地址的引用指针,也可能指向一个代表对象的句柄或者其他与此对象相关的位置),和返回后所指向的字节码的地址。其中64 位长度的long 和double 类型的数据会占用2个局部变量空间(Slot),其余的数据类型只占用1个。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。当递归层次太深时,会引发java.lang.StackOverflowError,这是虚拟机栈抛出的异常。
3. 本地方法栈
在HotSpot虚拟机将本地方法栈和虚拟机栈合二为一,它们的区别在于,虚拟机栈为执行Java方法服务,而本地方法栈则为虚拟机使用到的Native方法服务。
4. Java堆
Java 堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。这个区域是用来存放对象实例的,几乎所有对象实例都会在这里分配内存。堆是Java垃圾收集器管理的主要区域(GC堆),垃圾收集器实现了对象的自动销毁。Java堆可以细分为:新生代和老年代;再细致一点的有Eden空间,From Survivor空间,To Survivor空间等。Java堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,就像我们的磁盘空间一样。可以通过-Xmx和-Xms控制
5. 方法区
方法区也叫永久代。在过去(自定义类加载器还不是很常见的时候),类大多是”static”的,很少被卸载或收集,因此被称为“永久的(Permanent)”。虽然Java 虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java 堆区分开来。同时,由于类class是JVM实现的一部分,并不是由应用创建的,所以又被认为是“非堆(non-heap)”内存。HotSpot 虚拟机的设计团队选择把GC 分代收集扩展至方法区,或者说使用永久代来实现方法区而已。对于其他虚拟机(如BEA JRockit、IBM J9 等)来说是不存在永久代的概念的。
永久代也是各个线程共享的区域,它用于存储已经被虚拟机加载过的类信息,常量,静态变量(JDK7中被移到Java堆),即时编译期编译后的代码(类方法)等数据。这里要讲一下运行时常量池,它是方法区的一部分,用于存放编译期生成的各种字面量和符号引用(其实就是八大基本类型的包装类型和String类型数据(JDK7中被移到Java堆))(官方文档说明: In JDK 7, interned strings are no longer allocated in the permanent generation of the Java heap, but are instead allocated in the main part of the Java heap (known as the young and old generations), along with the other objects created by the application)。
在JDK1.7中的HotASpot中,已经把原本放在方法区的字符串常量池移出。
- 将interned String移到Java堆中
- 将符号Symbols移到native memory(不受GC管理的内存)
从JDK7开始永久代的移除工作,贮存在永久代的一部分数据已经转移到了Java Heap或者是Native Heap。但永久代仍然存在于JDK7,并没有完全的移除:符号引用(Symbols)转移到了native heap;字面量(interned strings)转移到了java heap;类的静态变量(class statics)转移到了java heap。随着JDK8的到来,JVM不再有PermGen。但类的元数据信息(metadata)还在,只不过不再是存储在连续的堆空间上,而是移动到叫做“Metaspace”的本地内存(Native memory)中。
在JVM中共享数据空间划分如下图所示
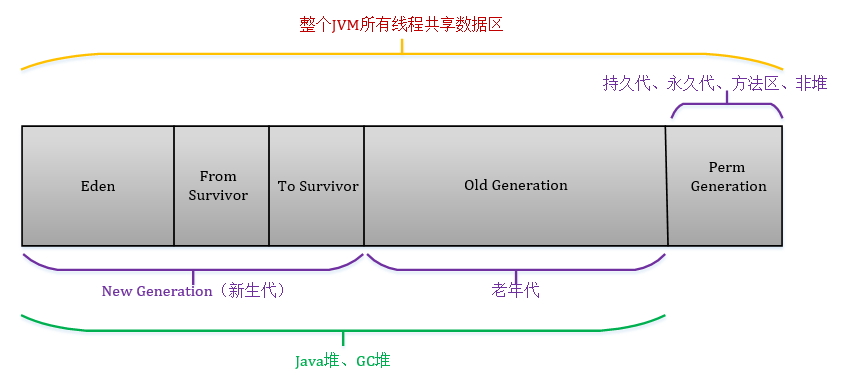
上图中,刻画了Java程序运行时的堆空间,可以简述成如下2条
1.JVM中共享数据空间可以分成三个大区,新生代(Young Generation)、老年代(Old Generation)、永久代(Permanent Generation),其中JVM堆分为新生代和老年代
2.新生代可以划分为三个区,Eden区(存放新生对象),两个幸存区(From Survivor和To Survivor)(存放每次垃圾回收后存活的对象)
3.永久代管理class文件、静态对象、属性等(JVM uses a separate region of memory, called the Permanent Generation (orPermGen for short), to hold internal representations of java classes. PermGen is also used to store more information )
4.JVM垃圾回收机制采用“分代收集”:新生代采用复制算法,老年代采用标记清理算法。
作为操作系统进程,Java 运行时面临着与其他进程完全相同的内存限制:操作系统架构提供的可寻址地址空间和用户空间。
操 作系统架构提供的可寻址地址空间,由处理器的位数决定,32 位提供了 2^32 的可寻址范围,也就是 4,294,967,296 位,或者说 4GB。而 64 位处理器的可寻址范围明显增大:2^64,也就是 18,446,744,073,709,551,616,或者说 16 exabyte(百亿亿字节)。
地址空间被划分为用户空间和内核空间。内核是主要的操作系统程序和C运行时,包含用于连接计算机硬件、调度程序以及提供联网和虚拟内存等服务的逻辑和基于C的进程(JVM)。除去内核空间就是用户空间,用户空间才是 Java 进程实际运行时使用的内存。
默认情况下,32 位 Windows 拥有 2GB 用户空间和 2GB 内核空间。在一些 Windows 版本上,通过向启动配置添加 /3GB 开关并使用 /LARGEADDRESSAWARE 开关重新链接应用程序,可以将这种平衡调整为 3GB 用户空间和 1GB 内核空间。在 32 位 Linux 上,默认设置为 3GB 用户空间和 1GB 内核空间。一些 Linux 分发版提供了一个hugemem内核,支持 4GB 用户空间。为了实现这种配置,将进行系统调用时使用的地址空间分配给内核。通过这种方式增加用户空间会减慢系统调用,因为每次进行系统调用时,操作系统必须在地址空间之间复制数据并重置进程地址-空间映射。
下图为一个32 位 Java 进程的内存布局:

可寻址的地址空间总共有 4GB,OS 和 C 运行时大约占用了其中的 1GB,Java 堆占用了将近 2GB,本机堆占用了其他部分。请注意,JVM 本身也要占用内存,就像 OS 内核和 C 运行时一样。
注意:
1. 上文提到的可寻址空间即指最大地址空间。
2. 对于2GB的用户空间,理论上Java堆内存最大为1.75G,但一旦Java线程的堆达到1.75G,那么就会出现本地堆的Out-Of-Memory错误,所以实际上Java堆的最大可使用内存为1.5G。
在JVM运行时,可以通过配置以下参数改变整个JVM堆的配置比例
1.Java heap的大小(新生代+老年代) -Xms堆的最小值 -Xmx堆空间的最大值 2.新生代堆空间大小调整 -XX:NewSize新生代的最小值 -XX:MaxNewSize新生代的最大值 -XX:NewRatio设置新生代与老年代在堆空间的大小 -XX:SurvivorRatio新生代中Eden所占区域的大小 3.永久代大小调整 -XX:MaxPermSize 4.其他 -XX:MaxTenuringThreshold,设置将新生代对象转到老年代时需要经过多少次垃圾回收,但是仍然没有被回收
在上面的配置中,老年代所占空间的大小是由-XX:SurvivorRatio这个参数进行配置的,看完了上面的JVM堆空间分配图,可能会奇怪,为啥新生代空间要划分为三个区Eden及两个Survivor区?有何用意?为什么要这么分?要理解这个问题,就得理解一下JVM的垃圾收集机制(复制算法也叫copy算法),步骤如下:
复制(Copying)算法
将内存平均分成A、B两块,算法过程:
1. 新生对象被分配到A块中未使用的内存当中。当A块的内存用完了, 把A块的存活对象对象复制到B块。
2. 清理A块所有对象。
3. 新生对象被分配的B块中未使用的内存当中。当B块的内存用完了, 把B块的存活对象对象复制到A块。
4. 清理B块所有对象。
5. goto 1。
优点:简单高效。缺点:内存代价高,有效内存为占用内存的一半。
图解说明如下所示:(图中后观是一个循环过程)

对复制算法进一步优化:使用Eden/S0/S1三个分区
平均分成A/B块太浪费内存,采用Eden/S0/S1三个区更合理,空间比例为Eden:S0:S1==8:1:1,有效内存(即可分配新生对象的内存)是总内存的9/10。
算法过程:
1. Eden+S0可分配新生对象;
2. 对Eden+S0进行垃圾收集,存活对象复制到S1。清理Eden+S0。一次新生代GC结束。
3. Eden+S1可分配新生对象;
4. 对Eden+S1进行垃圾收集,存活对象复制到S0。清理Eden+S1。二次新生代GC结束。
5. goto 1。
默认Eden:S0:S1=8:1:1,因此,新生代中可以使用的内存空间大小占用新生代的9/10,那么有人就会问,为什么不直接分成两个区,一个区占9/10,另一个区占1/10,这样做的原因大概有以下几种
1.S0与S1的区间明显较小,有效新生代空间为Eden+S0/S1,因此有效空间就大,增加了内存使用率
2.有利于对象代的计算,当一个对象在S0/S1中达到设置的XX:MaxTenuringThreshold值后,会将其分到老年代中,设想一下,如果没有S0/S1,直接分成两个区,该如何计算对象经过了多少次GC还没被释放,你可能会说,在对象里加一个计数器记录经过的GC次数,或者存在一张映射表记录对象和GC次数的关系,是的,可以,但是这样的话,会扫描整个新生代中的对象, 有了S0/S1我们就可以只扫描S0/S1区了~~~
以上是关于JVM内存的主要内容,如果未能解决你的问题,请参考以下文章