mysql查询语句中使用星号真的慢的要死?
Posted johntsu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql查询语句中使用星号真的慢的要死?相关的知识,希望对你有一定的参考价值。
前言
之所以写这篇文章,是源于以前看过的关于sql语句优化的帖子,里面明确提到了在sql语句中不要使用 * 来做查询,就像下面的规则中说的
2、尽量避免使用select *,返回无用的字段会降低查询效率。如下: SELECT * FROM t 优化方式:使用具体的字段代替*,只返回使用到的字段。
但是中国有句姥话叫“尽信书不如无书”,难道在sql查询语句中使用星号就真的慢的要死,难道加索引也不行?带着这些个疑问,我进行了一些测试。结果发现,江湖传说未必真的靠得住。那具体测试情况是咋样的呢?下面且听我给各位看官慢慢分解。
事先声明,本文是抛砖文,只进行测试,不做原理分析(要不然篇幅太长,各位看官估计要看睡着了)。本文的一切测试均以实际测试数据为准,拒绝假大空。
测试环境准备
我这次测试的系统环境如下:
- Win10系统
- mysql5.7.26 64位版本,使用默认的InnoDB存储引擎
然后我准备了一张tb_item表,用来存放测试数据,数据是我跟朋友要的一些商品信息数据。
下图是tb_item表的结构
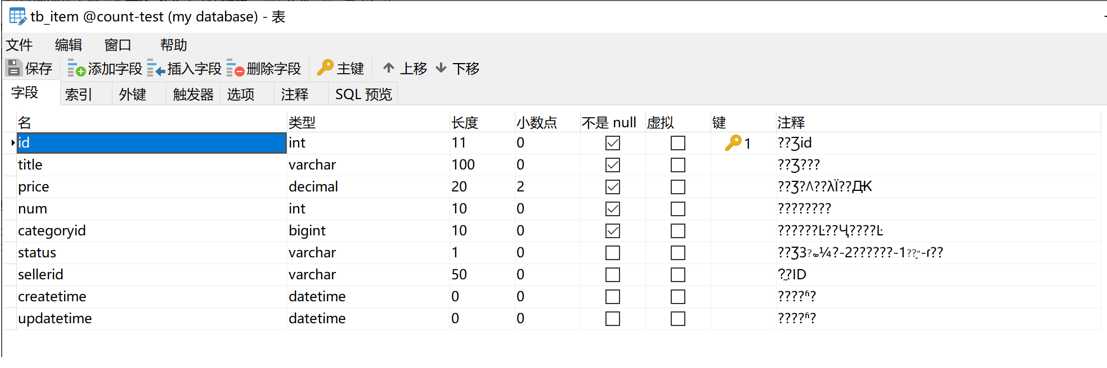
tb_item表中的部分数据
我将从以下几个方面去进行测试:
- count查询
- 联表查询
- 分页查询
好,闲话不多说,马上开整。
一.count查询
在count查询操作中,又分为两种情况,不带where条件的count查询,和带where条件的count查询。那我们就依次来测试一下。
1. 不带where条件的count查询
我们先来测试一下统计整个表的记录数。首先给大家剧透一下,tb_item表一共有300万条数据。执行 SELECT COUNT(*) FROM tb_item,结果如下图所示
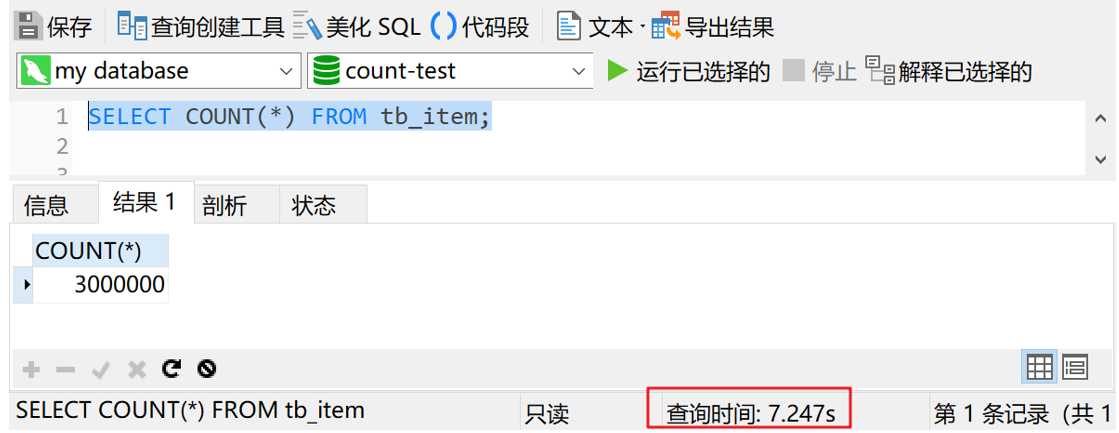
可以看到,查询时间是7秒多。如果是配置一般的机器,估计会更慢。显然,统计整张表的数据量,使用星号貌似是不行的。
那有没有办法可以优化一下呢?当然有啊,而且我都给大家测试好了。在tb_item表中有一个 status 字段,不知道大家注意到了没有
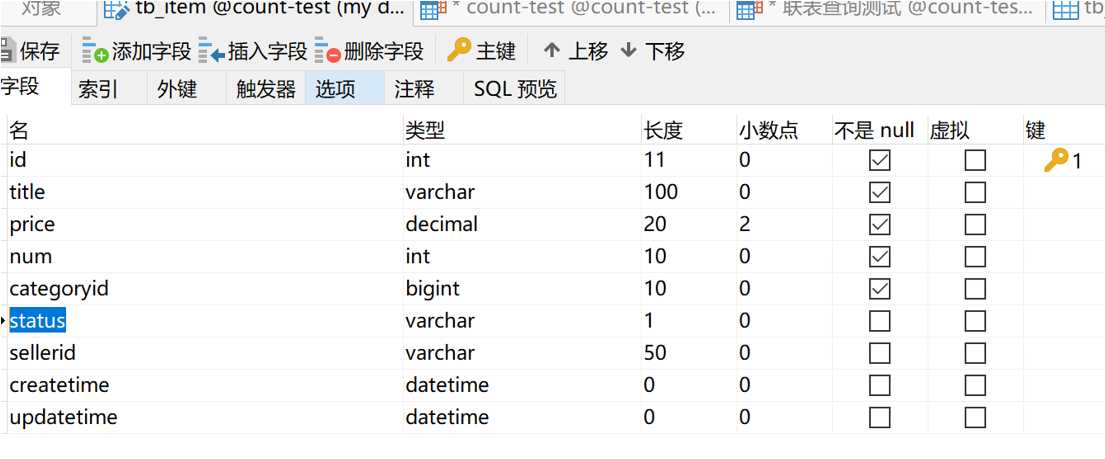
我们发现,这个字段的长度才占一个varchar。那如果我们修改一下刚才的sql,改成
SELECT COUNT(STATUS) FROM tb_item
又会如何呢?我们执行一下这条sql,看一下结果
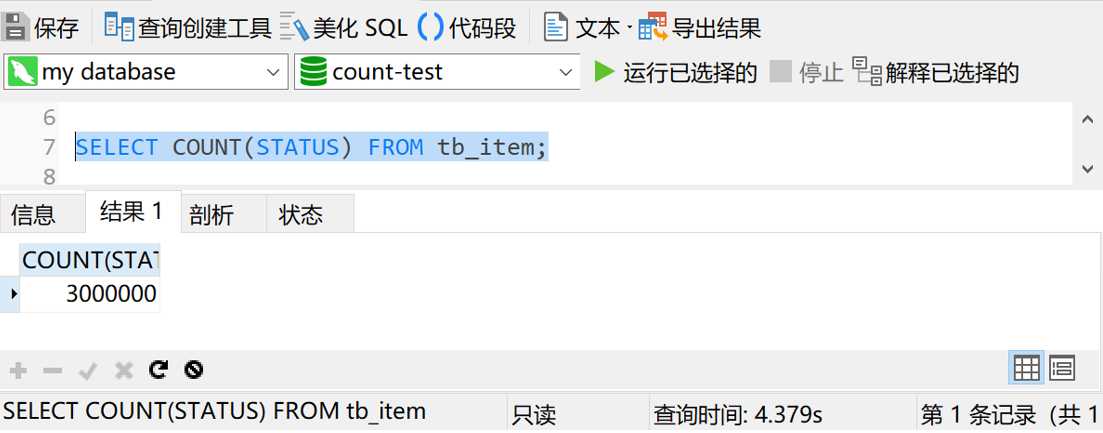
可以看到,这次的查询时间是4秒多,快了将近一半。
如果我们给 status 字段加个索引,结果又会怎样呢?那我们就加个索引试试。执行
CREATE INDEX idx_tb_item_status ON tb_item(STATUS)
然后我们再执行一下 SELECT COUNT(STATUS) FROM tb_item,结果如下图
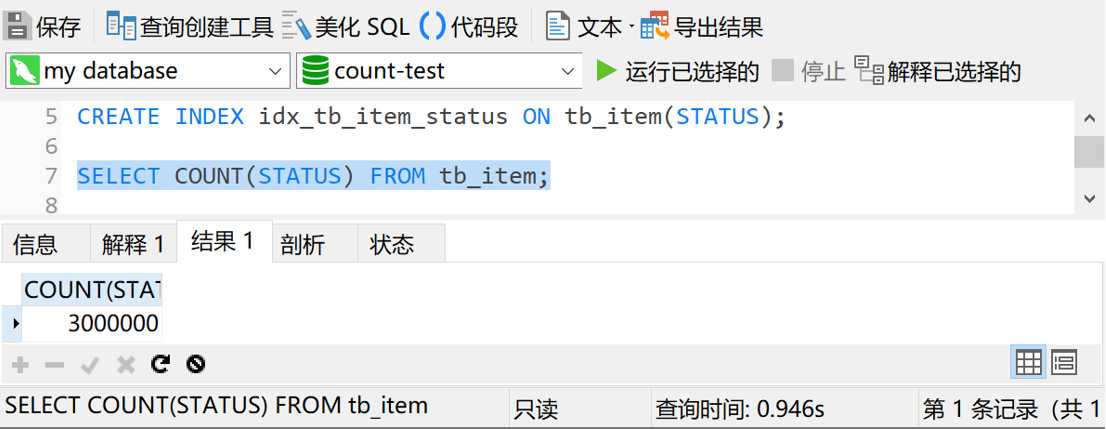
这次的查询时间是0.9秒,不到1秒。
从一开始的7秒多到现在的不到1秒,查询时间缩短了85%。这个优化结果真是爽的一批啊。
2. 带where条件的count查询
现在我们再试一下使用星号执行带where条件的查询操作会是个什么情况。我们简单一些,就查询价格小于1000块钱的商品数据。
执行 SELECT COUNT(*) FROM tb_item t WHERE t.price<1000,结果如下图
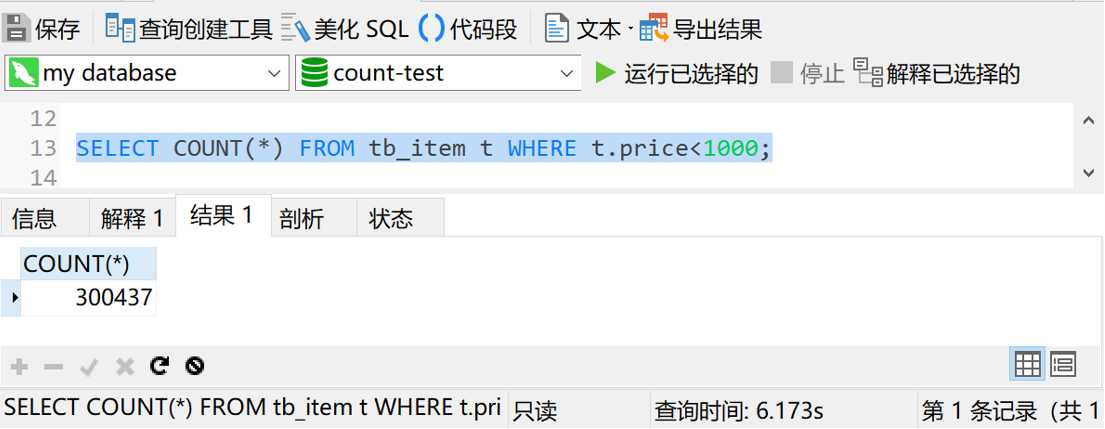
查询时间是6秒多。那我们给price字段加上索引后,再看看是个什么情况。执行下面的sql给price字段加索引
CREATE index idx_tb_item_price ON tb_item(price)
然后再次执行 SELECT COUNT(*) FROM tb_item t WHERE t.price<1000,结果如下图
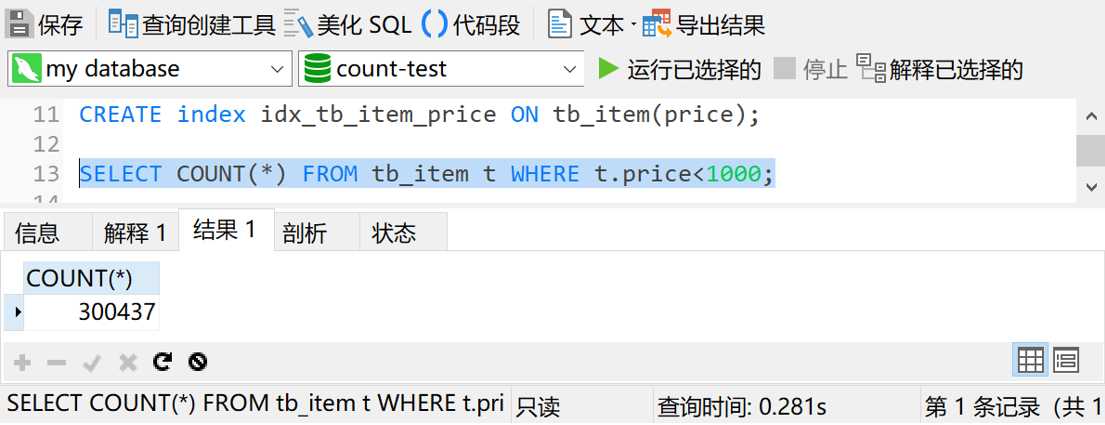
各位朋友,你们没有看错,加了索引之后,查询时间确实只有0.28秒。这查询效率提升了 99% 啊,简直爽得不要不要的。
那如果我们将星号换成长度只有一个varchar的 status 字段,情况又会是咋样的呢?我们来试一下
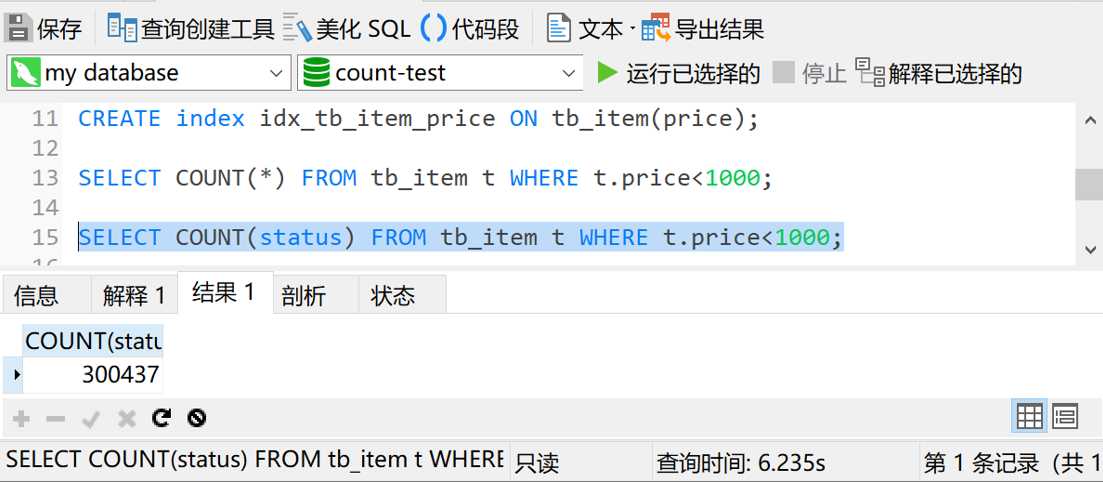
是的,你没看错,这次查询又花了6秒多的时间。也就是说,price字段的索引失效了。
看来带where条件的情况下,直接指定具体字段还不如直接用星号呢。
刚才我们只测试了带一个查询条件的情况,下面我们再来试试带多个查询条件的情况。这次我查询price大于1000,sellerid(品牌代码)字段是oppo的数据。预期查询时间小于1秒
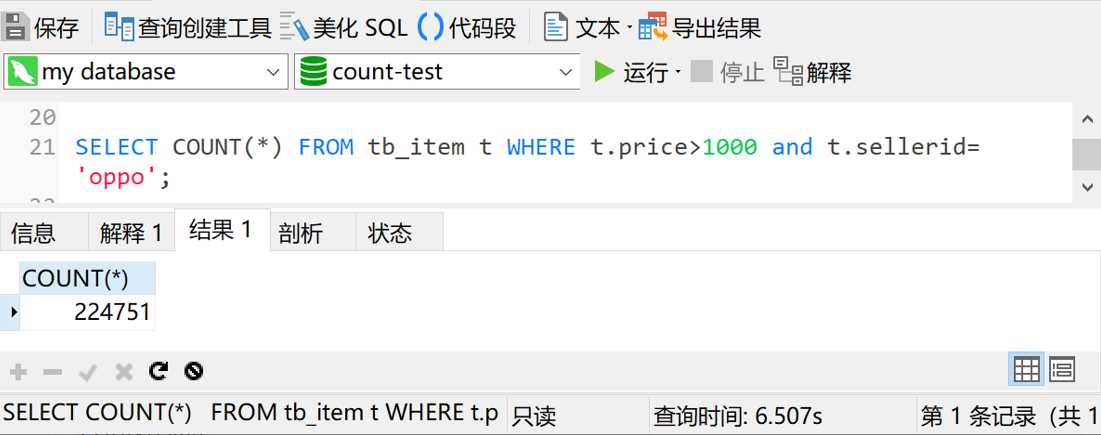
查询时间6秒多,不能接受。那我先给sellerid字段上个索引再试试
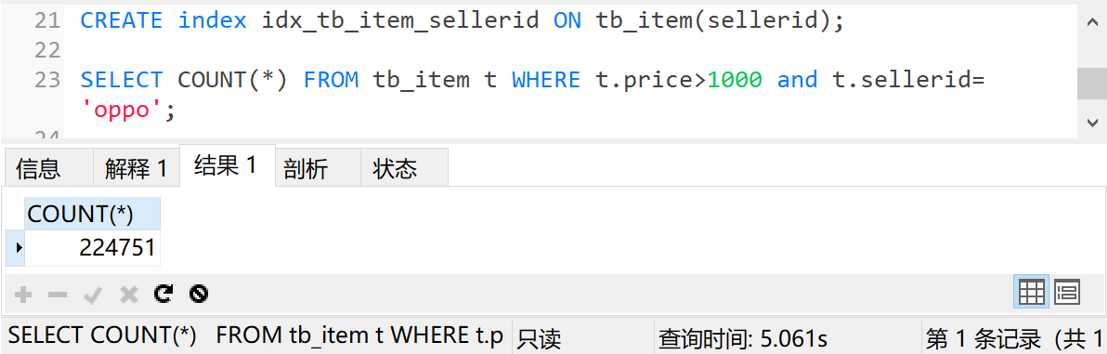
查询时间5秒,还是太慢。那就上个组合索引,给price和sellerid字段加个组合索引再试试。
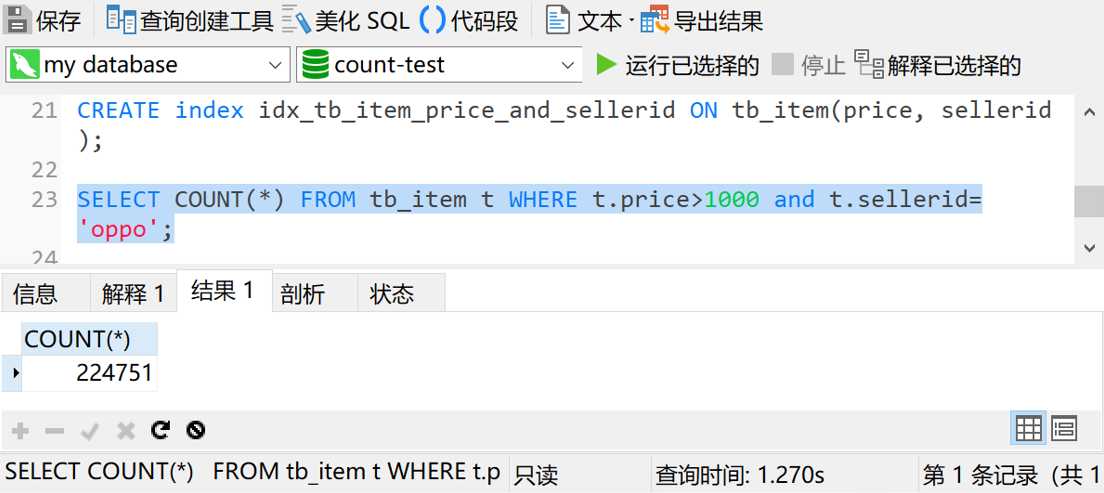
这次的查询时间是1秒多,虽然已经算不错了,但是还是没有达到我们预期的结果。而且我总不能增加一个查询条件,就改一次索引吧?
所以,对于这种百万级别数据的多条件查询的情况,最好的解决办法就是上一个数据检索系统,比如lucence或者elastic search,然后把数据导入到数据检索系统中,让它帮mysql完成数据的条件检索,Mysql只提供数据的详情查询服务。而且,像es这样的系统还带有分词功能,可以轻松通过关键词实现数据的检索。这比使用mysql的like操作来检索数据,效率不知道要高多少倍。所以,专业的事情还是交给专业的系统去干。别跟我说公司没钱,上不起es。数据量达到300w的业务,你跟我说没钱?
二.联表查询
刚才我们测试了在count查询操作中使用星号的情况,但是都是针对tb_item这一张表的操作。在实际的业务中,更多的是进行联表查询的操作。其中一个典型的业务场景,就是字典代码联表查询。比如在tb_item表中有一个sellerid字段,如下图
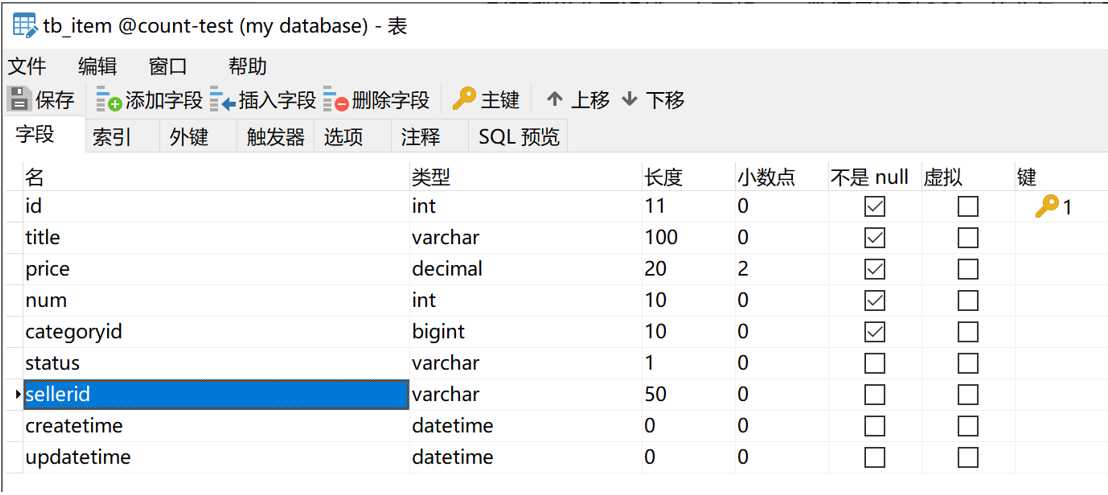
我们使用group by 加distinct关键字,看一下这个字段都有些什么内容
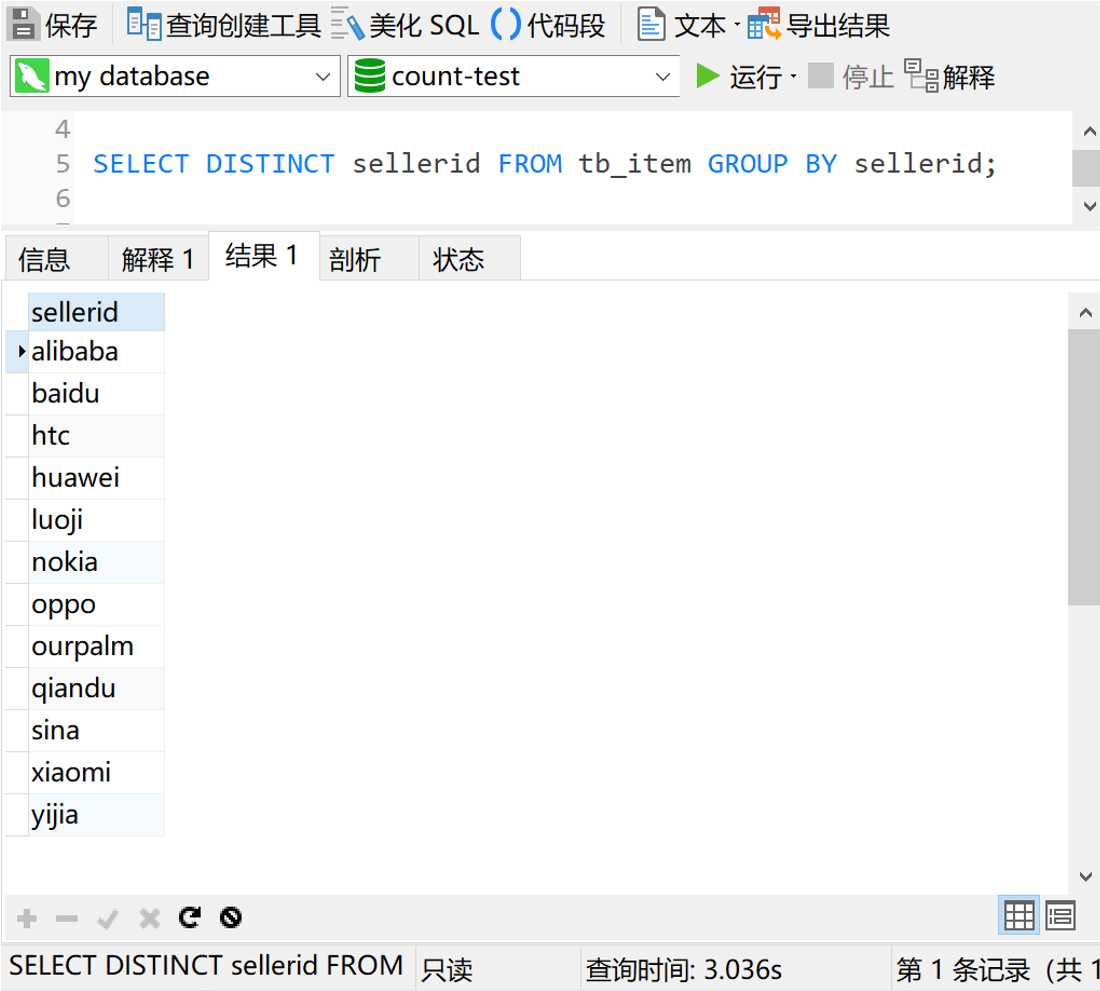
可以看出来,这都是些品牌的英文或者汉语拼音。那样的话,我们就可以创建一张品牌信息表tb_seller_info,用来存放品牌的字典码和名称。tb_seller_info表的表结构如下图
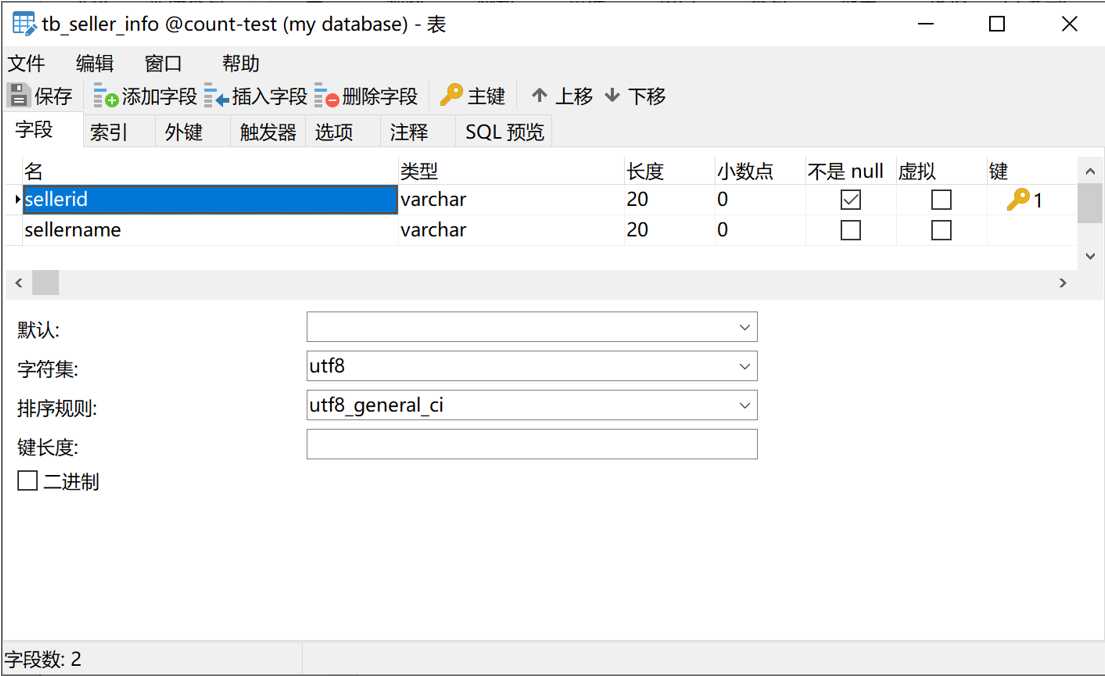
下图是表中的数据
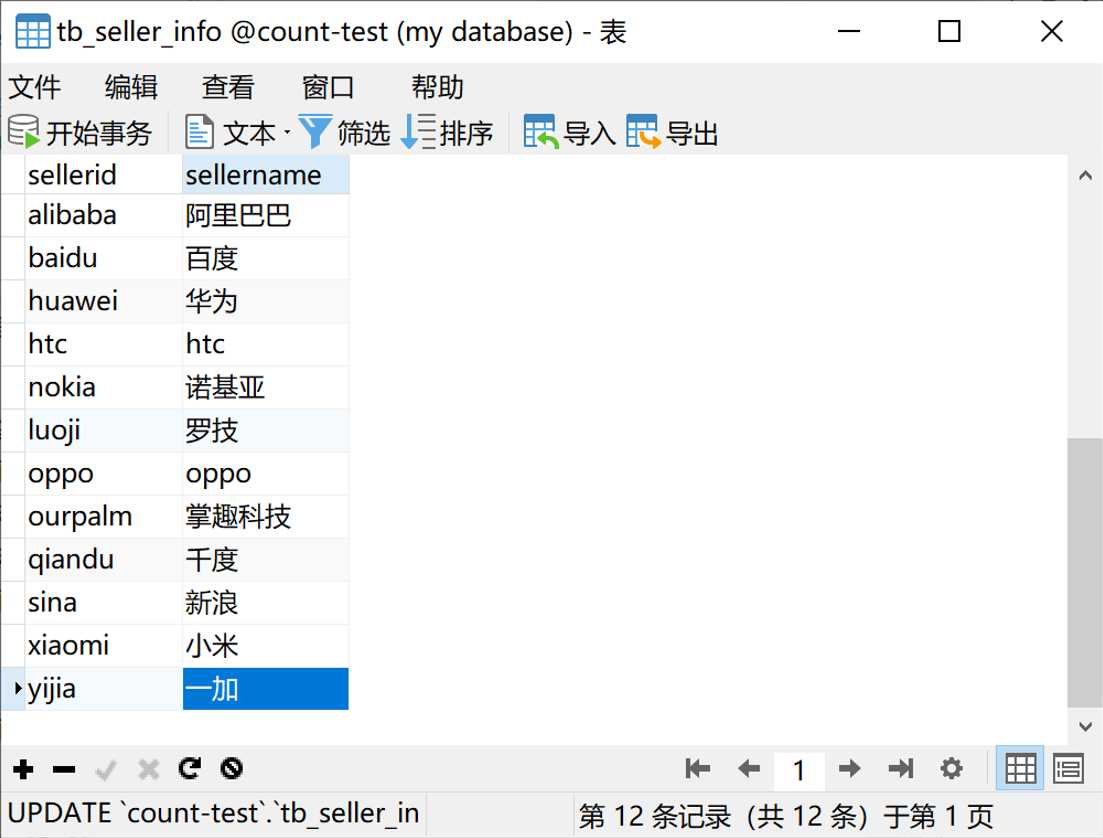
有了这张表,我们就可以做联表查询了。首先我们先来测试一下联表count查询tb_item表中“小米”公司的产品数据。执行下面的sql
SELECT COUNT(*) FROM tb_item t INNER JOIN tb_seller_info si ON t.sellerid=si.sellerid WHERE si.sellername=‘小米‘
结果如下图
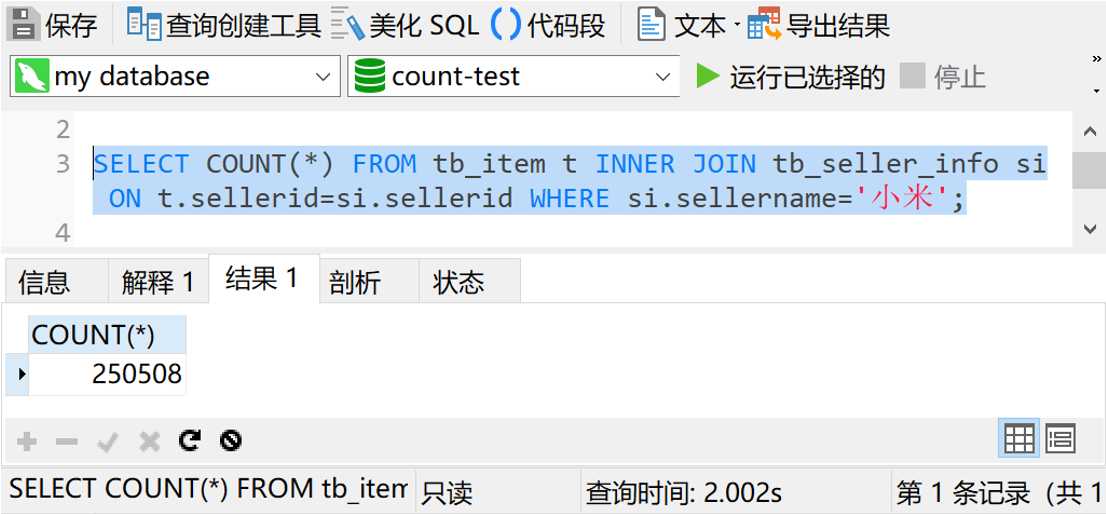
查询时间是2秒。现在,我们给tb_item表中的sellerid字段加个索引,再测试一下
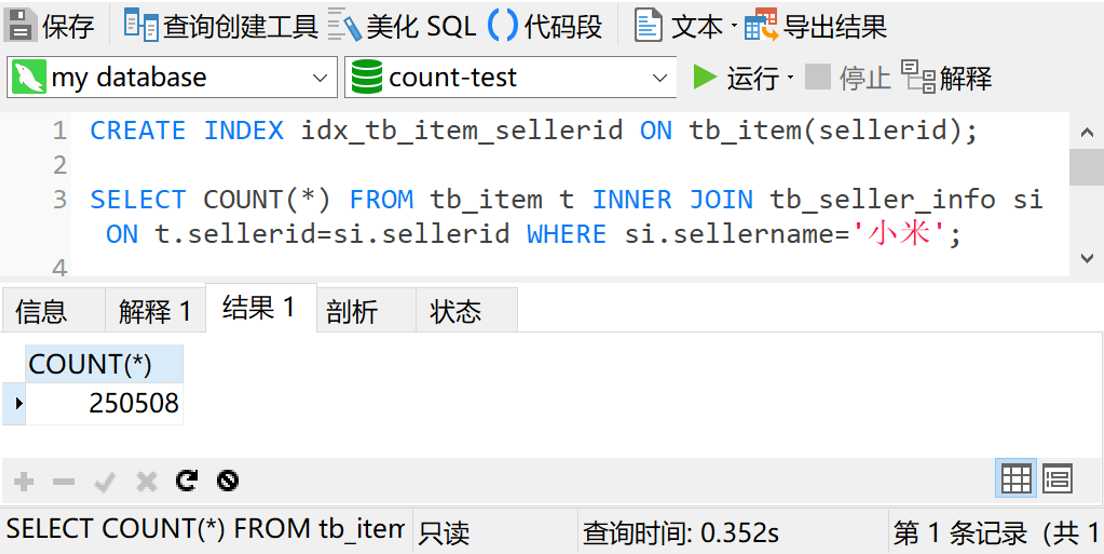
可以看到,这次查询只用了0.35秒。提升效果十分地明显。
如果我们把星号换成某个具体的字段,比如id字段,又是什么情况呢?我们试一下
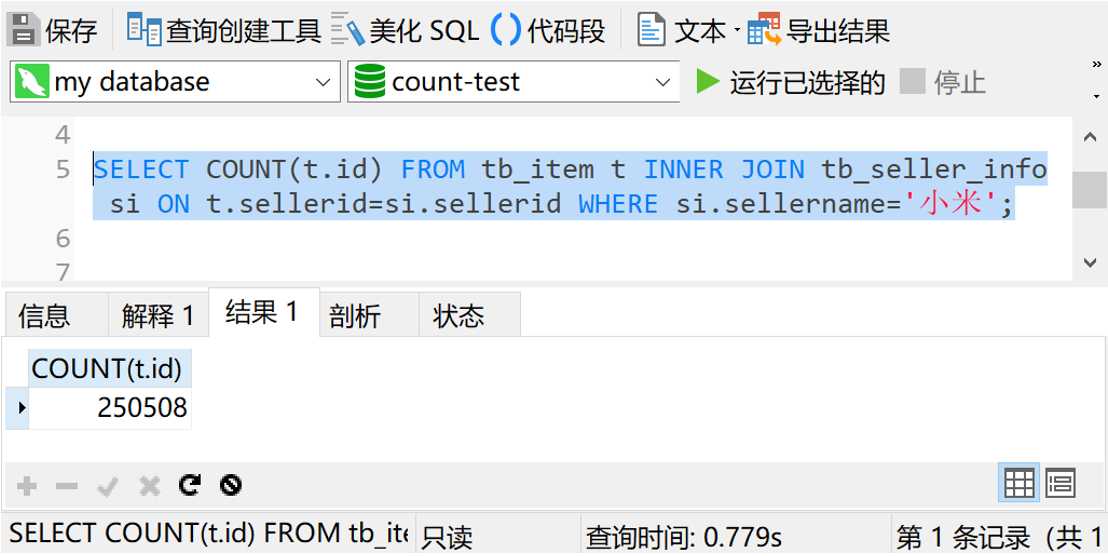
可以看到,查询时间和使用星号的情况差不多。
那如果我们不做count查询,而是查询具体的数据呢?
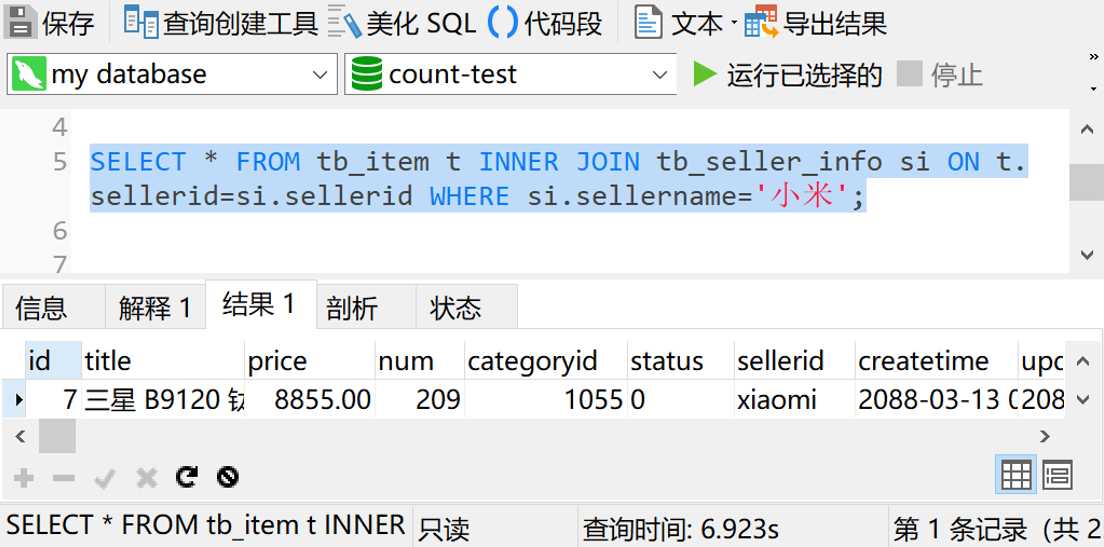
这一下查询时间就变成了将近7秒。OMG。我们得继续想办法优化了。我们先试试给tb_item表的sellerid字段加个索引试试。
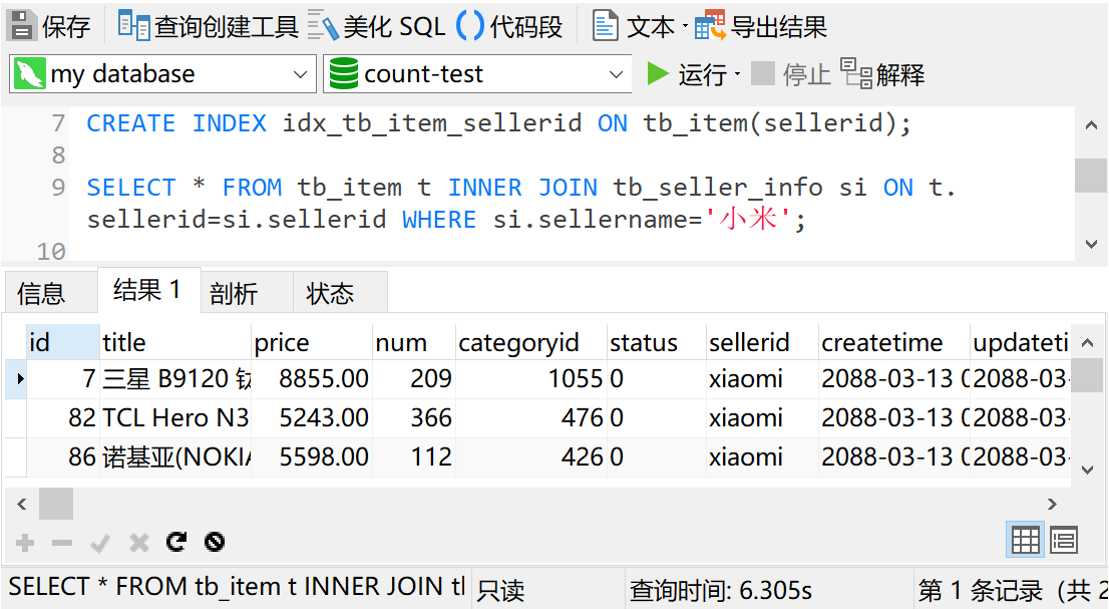
可以看到,查询时间是6秒多,还是不理想。那么我们把星号换成查询id字段再试试
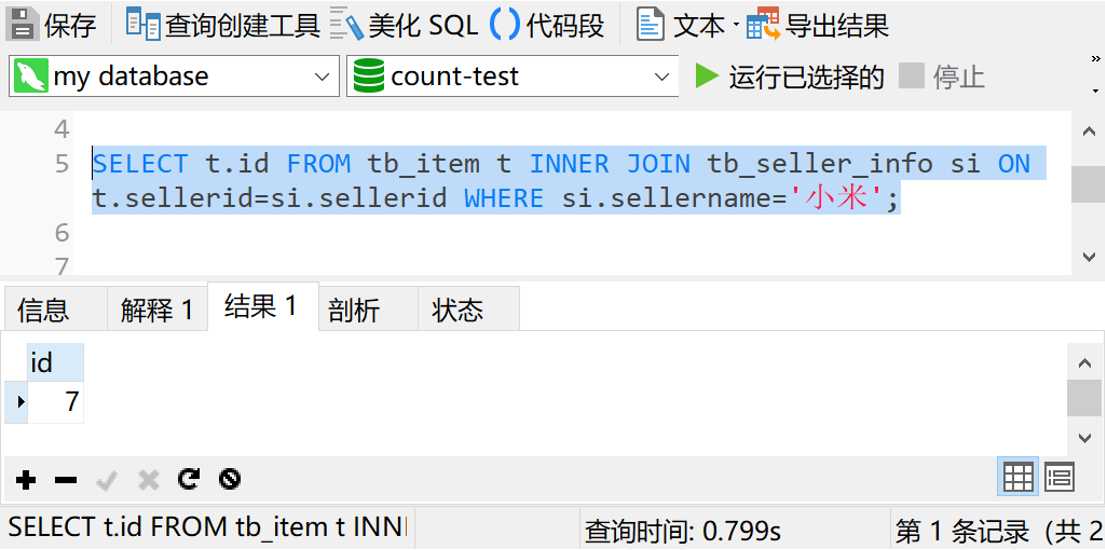
嘿,只查询id字段,竟然不到1秒就搞定了。各位亲们,看到这个,你们有没有想到什么?是不是觉得在id字段上建个hash索引,然后再搞个子查询,就OK了?说实话,我也想这样干。但是理想很美好,现实却很蛋疼。因为mysql5.7默认的InnoDB存储引擎不支持创建hash类型的索引。

那有人可能会说了,用那个MEMORY存储引擎啊,那个支持创建hash类型的索引。那如果我告诉你,这个存储引擎是非事务安全的,你还想用吗?
那么,我们就真的一点办法都没有了吗?哈哈,如果真的一点办法都没有,那我肯定就写不下去了啊。既然遇到问题了,总得解决不是。这里我先把图放出来,勾引勾引你们
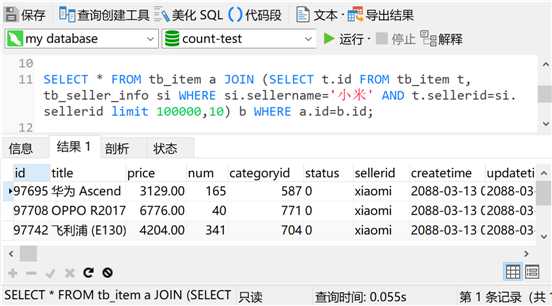
查询时间0.055秒,这个结果你们觉得爽不爽?
细心的朋友肯定看到了,我的这个sql中使用了分页查询。所以把联表查询改造成使用子查询,再结合分页查询,效果立马就出来了。由此也引出了我要写的第三部分内容,分页查询。
三.分页查询
提到这个,很多朋友的第一印象肯定是,页数越大,查询速度越慢。大家的感觉是对的,确实如此,我们可以先来测试一下。比如我从第200万条记录开始,查询10条记录
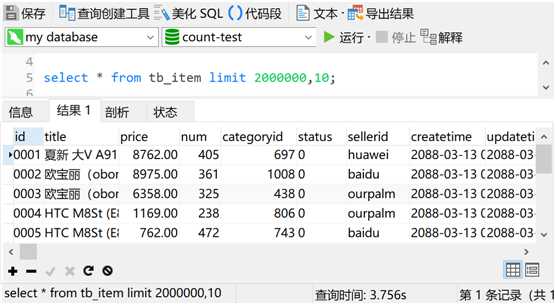
查询时间3秒多,如果是配置一般的机器,估计时间会更长。
关于分页查询如何优化,百度上一艘一大把,我这里就不废话了,直接上图
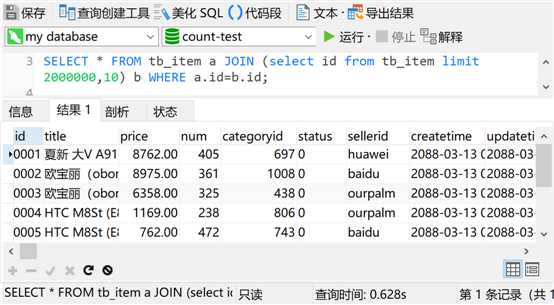
可见,分页查询的优化,也是使用了联表和子查询。回想刚才第二部分的联表查询,是不是就感觉豁然开朗了呢?(分页查询可是很多系统经常使用的功能呢)。
总结
通过一系列的测试,可以看出来,在sql查询中,并非不是不能使用星号的。只要根据实际情况,合理搭配使用索引,子查询等优化方法,用星号反而能让我们少写不少代码。而且不用在添加表字段后,再去修改相应的sql查询语句。当然,如果再搭配sql查询分析器去做针对性的优化,那就更完美了。
所以,古人诚不欺我,“尽信书不如无书”,说得太对了。必须向前辈们致敬一下。
今天做测试用的数据已上传到百度云,朋友们想自己测试娱乐一下的可以去下载。测试数据文件是个sql脚本文件,可以整库导入。百度云链接如下
链接:https://pan.baidu.com/s/1bWNvIyIviC_2swG3rSd3Fg
提取码:f3of
以上是关于mysql查询语句中使用星号真的慢的要死?的主要内容,如果未能解决你的问题,请参考以下文章