python 进程和线程-进程和线程的比较以及分布式进程
Posted gaoqiking
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 进程和线程-进程和线程的比较以及分布式进程相关的知识,希望对你有一定的参考价值。
进程和线程的比较
参考链接:https://www.liaoxuefeng.com/wiki/1016959663602400/1017631469467456
我们介绍了多进程和多线程,这是实现多任务最常用的两种方式。现在,我们来讨论一下这两种方式的优缺点。
首先,要实现多任务,通常我们会设计Master-Worker模式,Master负责分配任务,Worker负责执行任务,因此,多任务环境下,通常是一个Master,多个Worker。
如果用多进程实现Master-Worker,主进程就是Master,其他进程就是Worker。
如果用多线程实现Master-Worker,主线程就是Master,其他线程就是Worker。(注意是一个主线程,不是一个主进程)
进程稳定性高,但开销大
多进程模式最大的优点就是稳定性高,因为一个子进程崩溃了,不会影响主进程和其他子进程。(当然主进程挂了所有进程就全挂了,但是Master进程只负责分配任务,挂掉的概率低)著名的Apache最早就是采用多进程模式。
多进程模式的缺点是创建进程的代价大,在Unix/Linux系统下,用fork调用还行,在Windows下创建进程开销巨大。另外,操作系统能同时运行的进程数也是有限的,在内存和CPU的限制下,如果有几千个进程同时运行,操作系统连调度都会成问题。
多线程模式通常比多进程快一点,但是也快不到哪去,而且,多线程模式致命的缺点就是任何一个线程挂掉都可能直接造成整个进程崩溃,因为所有线程共享进程的内存。在Windows上,如果一个线程执行的代码出了问题,你经常可以看到这样的提示:“该程序执行了非法操作,即将关闭”,其实往往是某个线程出了问题,但是操作系统会强制结束整个进程。
在Windows下,多线程的效率比多进程要高,所以微软的IIS服务器默认采用多线程模式。由于多线程存在稳定性的问题,IIS的稳定性就不如Apache。为了缓解这个问题,IIS和Apache现在又有多进程+多线程的混合模式,真是把问题越搞越复杂。
线程切换
保存现场和准备环境
作者举了一个写不同科目的作业来详细说明了保存现场和准备环境的工作都有哪些
操作系统在切换进程或者线程时也是一样的,它需要先保存当前执行的现场环境(CPU寄存器状态、内存页等),然后,把新任务的执行环境准备好(恢复上次的寄存器状态,切换内存页等),才能开始执行。这个切换过程虽然很快,但是也需要耗费时间。如果有几千个任务同时进行,操作系统可能就主要忙着切换任务,根本没有多少时间去执行任务了,这种情况最常见的就是硬盘狂响,点窗口无反应,系统处于假死状态。
所以,多任务一旦多到一个限度,就会消耗掉系统所有的资源,结果效率急剧下降,所有任务都做不好。
计算密集型 vs. IO密集型
计算密集型的对语言的执行效率要求较高,python是一种运行效率低的语言
是否采用多任务的第二个考虑是任务的类型。我们可以把任务分为计算密集型和IO密集型。
计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
第二种任务的类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。(为什么最差呢?不是花在cpu上的时间很少吗?那不就是说语言执行效率的高低就没有影响了吗?)
异步IO
考虑到CPU和IO之间巨大的速度差异,一个任务在执行的过程中大部分时间都在等待IO操作,单进程单线程模型会导致别的任务无法并行执行,因此,我们才需要多进程模型或者多线程模型来支持多任务并发执行。
现代操作系统对IO操作已经做了巨大的改进,最大的特点就是支持异步IO。如果充分利用操作系统提供的异步IO支持,就可以用单进程单线程模型来执行多任务,这种全新的模型称为事件驱动模型,nginx就是支持异步IO的Web服务器,它在单核CPU上采用单进程模型就可以高效地支持多任务。在多核CPU上,可以运行多个进程(数量与CPU核心数相同),充分利用多核CPU。由于系统总的进程数量十分有限,因此操作系统调度非常高效。用异步IO编程模型来实现多任务是一个主要的趋势。
对应到Python语言,单线程的异步编程模型称为协程,有了协程的支持,就可以基于事件驱动编写高效的多任务程序。
分布式进程(只是看了一遍)
参考链接:https://www.liaoxuefeng.com/wiki/1016959663602400/1017631559645600
在Thread和Process中,应当优选Process,因为Process更稳定,而且,Process可以分布到多台机器上,而Thread最多只能分布到同一台机器的多个CPU上。
Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上。一个服务进程可以作为调度者,将任务分布到其他多个进程中,依靠网络通信。由于managers模块封装很好,不必了解网络通信的细节,就可以很容易地编写分布式多进程程序。
举个例子:如果我们已经有一个通过Queue通信的多进程程序在同一台机器上运行,现在,由于处理任务的进程任务繁重,希望把发送任务的进程和处理任务的进程分布到两台机器上。怎么用分布式进程实现?
这个简单的Master/Worker模型有什么用?其实这就是一个简单但真正的分布式计算,把代码稍加改造,启动多个worker,就可以把任务分布到几台甚至几十台机器上,比如把计算n*n的代码换成发送邮件,就实现了邮件队列的异步发送。
我们先看服务进程,服务进程负责启动Queue,把Queue注册到网络上,然后往Queue里面写入任务:
# task_master.py
import random, time, queue
from multiprocessing.managers import BaseManager
# 发送任务的队列:
task_queue = queue.Queue()
# 接收结果的队列:
result_queue = queue.Queue()
# 从BaseManager继承的QueueManager:
class QueueManager(BaseManager):
pass
# 把两个Queue都注册到网络上, callable参数关联了Queue对象:
QueueManager.register(‘get_task_queue‘, callable=lambda: task_queue)
QueueManager.register(‘get_result_queue‘, callable=lambda: result_queue)
# 绑定端口5000, 设置验证码‘abc‘:
manager = QueueManager(address=(‘‘, 5000), authkey=b‘abc‘)
# 启动Queue:
manager.start()
# 获得通过网络访问的Queue对象:
task = manager.get_task_queue()
result = manager.get_result_queue()
# 放几个任务进去:
for i in range(10):
n = random.randint(0, 10000)
print(‘Put task %d...‘ % n)
task.put(n)
# 从result队列读取结果:
print(‘Try get results...‘)
for i in range(10):
r = result.get(timeout=10)
print(‘Result: %s‘ % r)
# 关闭:
manager.shutdown()
print(‘master exit.‘)
请注意,当我们在一台机器上写多进程程序时,创建的Queue可以直接拿来用,但是,在分布式多进程环境下,添加任务到Queue不可以直接对原始的task_queue进行操作,那样就绕过了QueueManager的封装,必须通过manager.get_task_queue()获得的Queue接口添加。
然后,在另一台机器上启动任务进程(本机上启动也可以):
# task_worker.py
import time, sys, queue
from multiprocessing.managers import BaseManager
# 创建类似的QueueManager:
class QueueManager(BaseManager):
pass
# 由于这个QueueManager只从网络上获取Queue,所以注册时只提供名字:
QueueManager.register(‘get_task_queue‘)
QueueManager.register(‘get_result_queue‘)
# 连接到服务器,也就是运行task_master.py的机器:
server_addr = ‘127.0.0.1‘
print(‘Connect to server %s...‘ % server_addr)
# 端口和验证码注意保持与task_master.py设置的完全一致:
m = QueueManager(address=(server_addr, 5000), authkey=b‘abc‘)
# 从网络连接:
m.connect()
# 获取Queue的对象:
task = m.get_task_queue()
result = m.get_result_queue()
# 从task队列取任务,并把结果写入result队列:
for i in range(10):
try:
n = task.get(timeout=1)
print(‘run task %d * %d...‘ % (n, n))
r = ‘%d * %d = %d‘ % (n, n, n*n)
time.sleep(1)
result.put(r)
except Queue.Empty:
print(‘task queue is empty.‘)
# 处理结束:
print(‘worker exit.‘)
任务进程要通过网络连接到服务进程,所以要指定服务进程的IP。
现在,可以试试分布式进程的工作效果了。先启动task_master.py服务进程:
$ python3 task_master.py Put task 3411... Put task 1605... Put task 1398... Put task 4729... Put task 5300... Put task 7471... Put task 68... Put task 4219... Put task 339... Put task 7866... Try get results...
task_master.py进程发送完任务后,开始等待result队列的结果。现在启动task_worker.py进程:
$ python3 task_worker.py Connect to server 127.0.0.1... run task 3411 * 3411... run task 1605 * 1605... run task 1398 * 1398... run task 4729 * 4729... run task 5300 * 5300... run task 7471 * 7471... run task 68 * 68... run task 4219 * 4219... run task 339 * 339... run task 7866 * 7866... worker exit.
task_worker.py进程结束,在task_master.py进程中会继续打印出结果:
Result: 3411 * 3411 = 11634921 Result: 1605 * 1605 = 2576025 Result: 1398 * 1398 = 1954404 Result: 4729 * 4729 = 22363441 Result: 5300 * 5300 = 28090000 Result: 7471 * 7471 = 55815841 Result: 68 * 68 = 4624 Result: 4219 * 4219 = 17799961 Result: 339 * 339 = 114921 Result: 7866 * 7866 = 61873956
Queue对象存储在哪?注意到task_worker.py中根本没有创建Queue的代码,所以,Queue对象存储在task_master.py进程中:
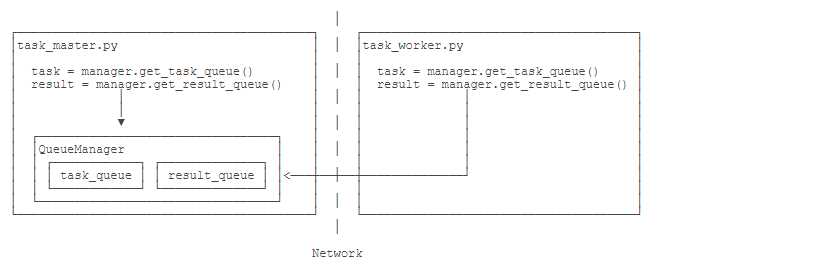
而Queue之所以能通过网络访问,就是通过QueueManager实现的。由于QueueManager管理的不止一个Queue,所以,要给每个Queue的网络调用接口起个名字,比如get_task_queue。
authkey有什么用?这是为了保证两台机器正常通信,不被其他机器恶意干扰。如果task_worker.py的authkey和task_master.py的authkey不一致,肯定连接不上。
小结
Python的分布式进程接口简单,封装良好,适合需要把繁重任务分布到多台机器的环境下。
注意Queue的作用是用来传递任务和接收结果,每个任务的描述数据量要尽量小。比如发送一个处理日志文件的任务,就不要发送几百兆的日志文件本身,而是发送日志文件存放的完整路径,由Worker进程再去共享的磁盘上读取文件。
以上是关于python 进程和线程-进程和线程的比较以及分布式进程的主要内容,如果未能解决你的问题,请参考以下文章