目录
BN的由来
BN的作用
BN的操作阶段
BN的操作流程
BN可以防止梯度消失吗
为什么归一化后还要放缩和平移
BN在GoogLeNet中的应用
参考资料
|
BN的由来 |
BN是由Google于2015年提出,论文是《Batch Normalization_ Accelerating Deep Network Training by Reducing Internal Covariate Shift》,这是一个深度神经网络训练的技巧,主要是让数据的分布变得一致,从而使得训练深层网络模型更加容易和稳定。所以目前BN已经成为几乎所有卷积神经网络的标配技巧了。
|
BN的作用 |
Internal Convariate shift是BN论文作者提出来的概念,表示数据的分布在网络传播过程中会发生偏移,我们举个例子来解释它,假设我们有一个玫瑰花的深度学习网络,这是一个二分类的网络,1表示识别为玫瑰,0则表示非玫瑰花。我们先看看训练数据集的一部分:

直观来说,玫瑰花的特征表现很明显,都是红色玫瑰花。 再看看训练数据集的另一部分:

很明显,这部分数据的玫瑰花各种颜色都有,其特征分布与上述数据集是不一样的。
通俗地讲,刚开始的数据都是同一个分布的,模型学习过程中,模型的参数已经适合于一种分布,突然又要适应另一种分布,这就会让模型的参数发生很大的调整,从而影响到收敛速度和精度,这就是Internal covariate shift。
而BN的作用就是将这些输入值或卷积网络的张量进行类似标准化的操作,将其放缩到合适的范围,从而加快训练速度;另一方面使得每一层可以尽量面对同一特征分布的输入值,减少了变化带来的不确定性。
|
BN的操作阶段 |
某一批次的张量通过卷积层并加上偏置后,relu激活之前,即

|
BN的操作流程 |
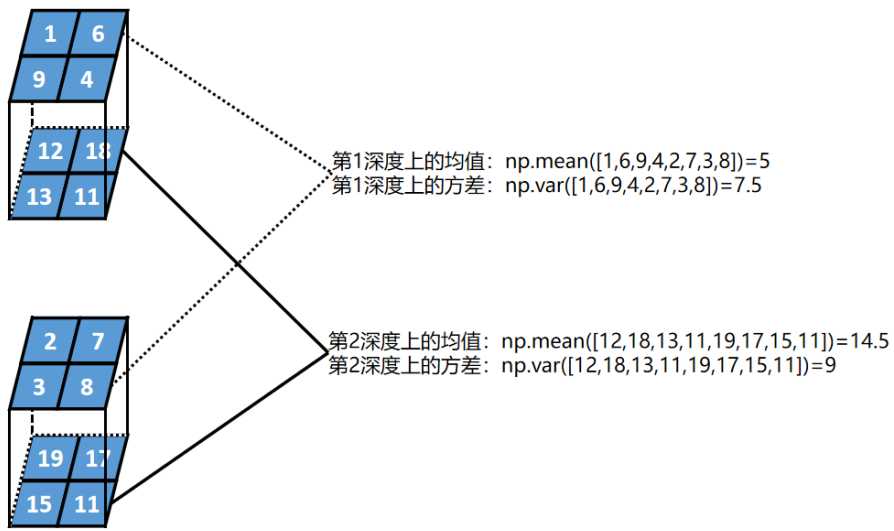
假设某一批次的数据为2个2行2列2深度的张量,BN的过程如下:

第一步:
计算每一层深度的均值和方差
第二步:
对每一层设置2个参数,γ和β。假设第1深度γ=2、β=3;第2深度γ=5、β=8。
计算公式:

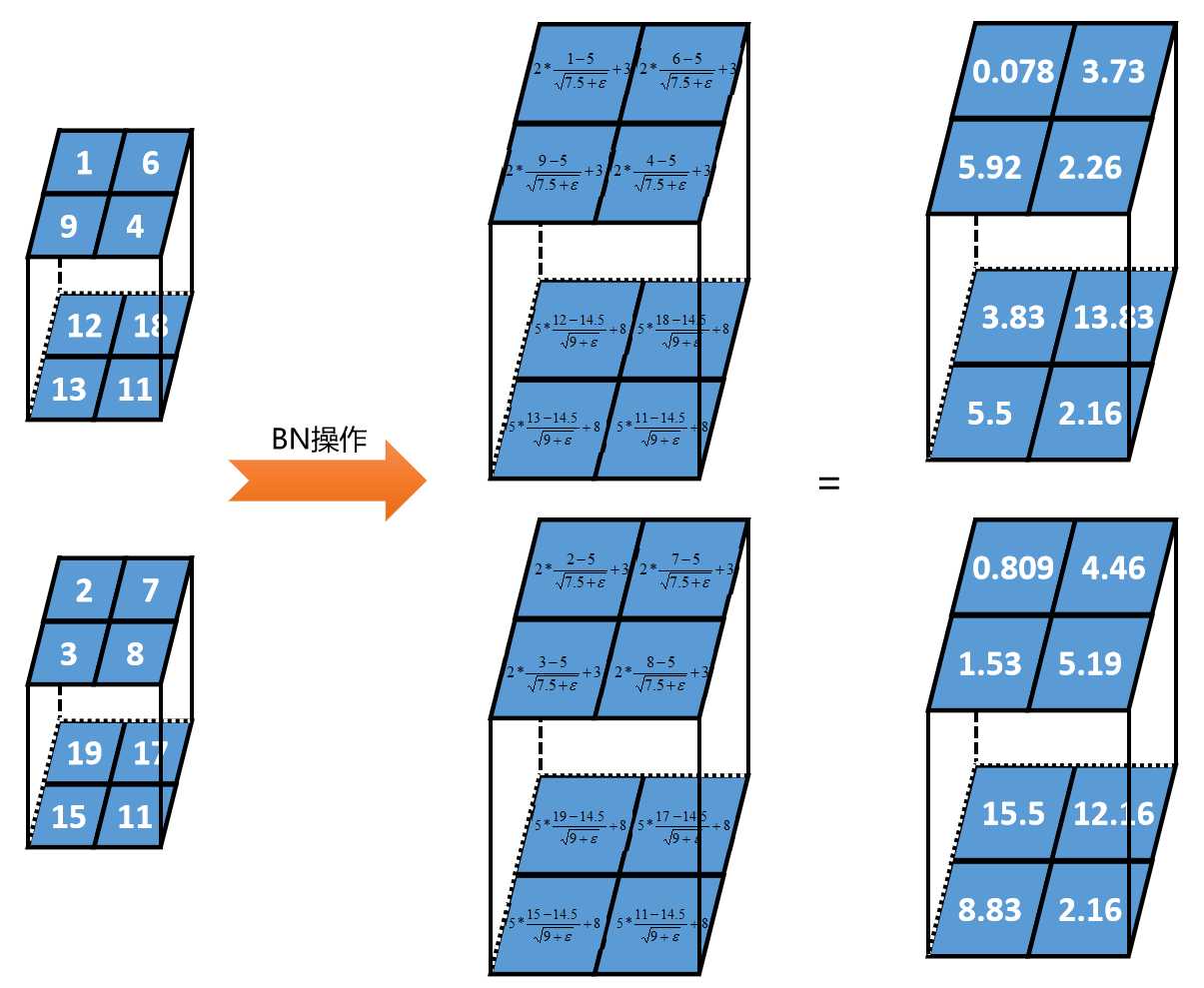
|
BN可以防止梯度消失吗 |
BN可以防止学习过程中梯度消失,这一点论文中有阐述,作者说可以如果使用sigmod激活函数的时候,如果不用BN的话,会让反向传播的过程中梯度消失(当输出值较大或较小时,sigmod函数就会进入饱和区域,导致其导数几乎为零),但是可以通过使用Relu激活函数来解决,那就意味着BN主要还是让数据分布变为一致。
|
为什么归一化后还要放缩和平移 |
减均值除方差得到的分布是正态分布,我们能否认为正态分布就是最好或最能体现我们训练样本的特征分布呢?
非也,如果激活函数在方差为1的数据上,没有表现最好的效果,比如Sigmoid激活函数。这个函数在-1~1之间的梯度变化不大。假如某一层学习到特征数据本身就分布在S型激活函数的两侧,把它归一化处理、标准差也限制在了1,把数据变换成分布于s函数的中间部分,就没有达到非线性变换的目的,换言之,减均值除方差操作后可能会削弱网络的性能。
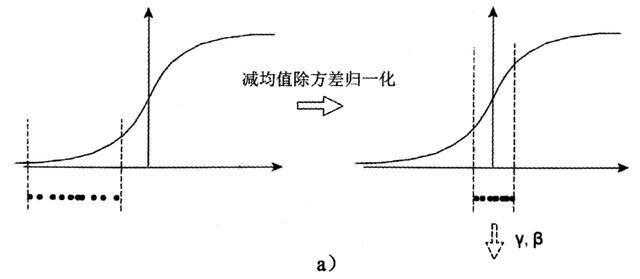
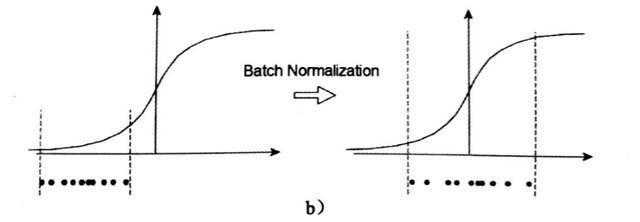
不光是Sigmoid激活函数,Tanh函数在零附近也变成线性
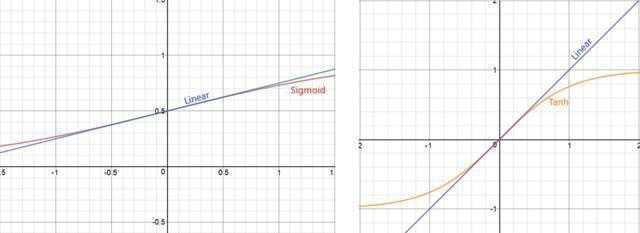
而Relu activation函数,则将一半的输入清零。
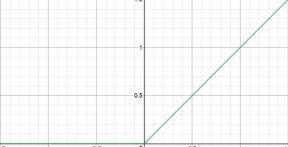
因此,必须进行一些转换才能将分布从0移开。使用缩放因子γ和移位因子β来执行此操作。
随着训练的进行,这些γ和β也通过反向传播学习以提高准确性。这就要求为每一层学习2个额外的参数来提高训练速度。
这个最终转换因此完成了批归一算法的定义。缩放和移位是算法比较关键,因为它提供了更多的灵活性。假设如果我们决定不使用BatchNorm,我们可以设置γ=σ和β= mean,从而返回原始值。
PS:γ和β也是待学习的参数,在网络学习的过程中会被更新

|
BN在GoogLeNet中的应用 |
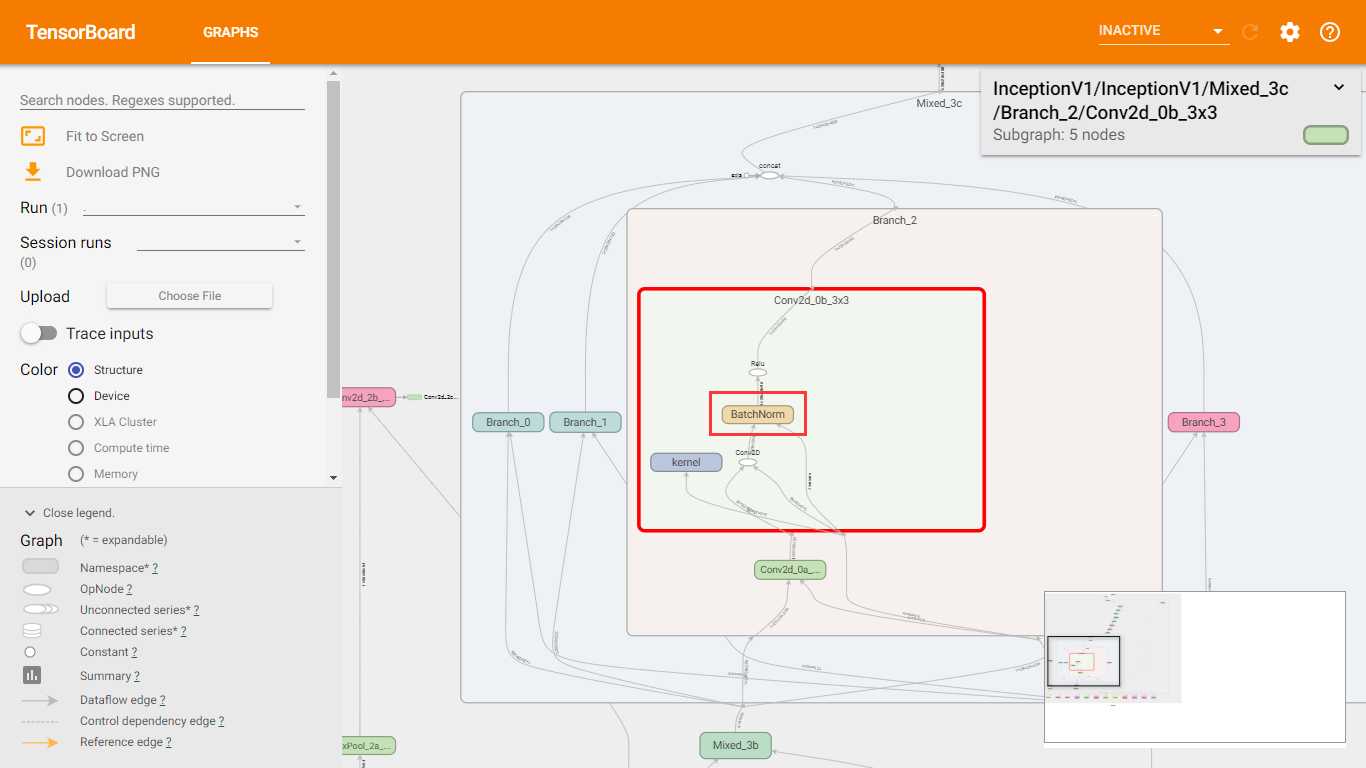
在slim中,BN已经用在了InceptionV1中了,如下图所示。
BN是2015年提出的,InceptionV1是2014年提出的,但是slim的代码是2016年完成的。在Inception的其他版本中也有应用BN。
|
参考资料 |
《图解深度学习与神经网络:从张量到TensorFlow实现》_张平
Batch Normalization_ Accelerating Deep Network Training by Reducing Internal Covariate Shift
《深-度-学-习-核-心-技-术-与-实-践》
【深度学习】批归一化(Batch Normalization)
https://www.cnblogs.com/skyfsm/p/8453498.html
深度学习基础系列(七)| Batch Normalization
https://www.cnblogs.com/hutao722/p/9842199.html
深度学习 --- 优化入门四(Batch Normalization(批量归一化)一)
https://blog.csdn.net/weixin_42398658/article/details/84560411
批归一化Batch Normalization的原理及算法
https://baijiahao.baidu.com/s?id=1612936475591914473&wfr=spider&for=pc