Zookeeper
Posted -levi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper相关的知识,希望对你有一定的参考价值。
为什么要有Zookeeper?
电视里经常会有一些狗血的设定,队长和副队长一起出去执行任务,执行完任务后副队长回来报到了,但是队长可能因为天气原因导致航班延期了,暂时回不来,这个时候副队长左等右等还等不到队长回来,而且副队长担心队长如果出事了,下面的队员没有人约束,大家可能就会松懈下来,副队长等了一个星期后,自己当队长了。
结果过了两个星期后,队长回来了,这个时候就产生了连个队长,这个时候组员就麻烦了,他们不知道听谁的,假设也有可能写一份报告时,都给两位队长。
这里面如果还有一个支援保障小队,发现队长还没回来啊,那么这个支援保障小队就去查队长是不是遇到什么事了,结果一查,队长没出事,平安大吉,那么支援保障小队就告诉副队长,你不用担心了,他没事,我们会告知委员会,委员会会选举出一个队长,选到你了会正式通知你的。
什么是Zookeeper?
Zookeeper是一个Apache下的开源分布式协调框架,就是为分布式应用提供协调服务的。
Zookeeper从设计模式的角度来理解,是一个基于观察者模式设计的分布式服务管理框架,负责存储和管理都关心的数据(状态),然后接受观察者的注册,一旦这些数据的状态发生了变化,Zookeeper就通知已经在Zookeeper上注册的那些观察者这做出相应的反应,从而实现集群中类似Master/Slave管理模式。
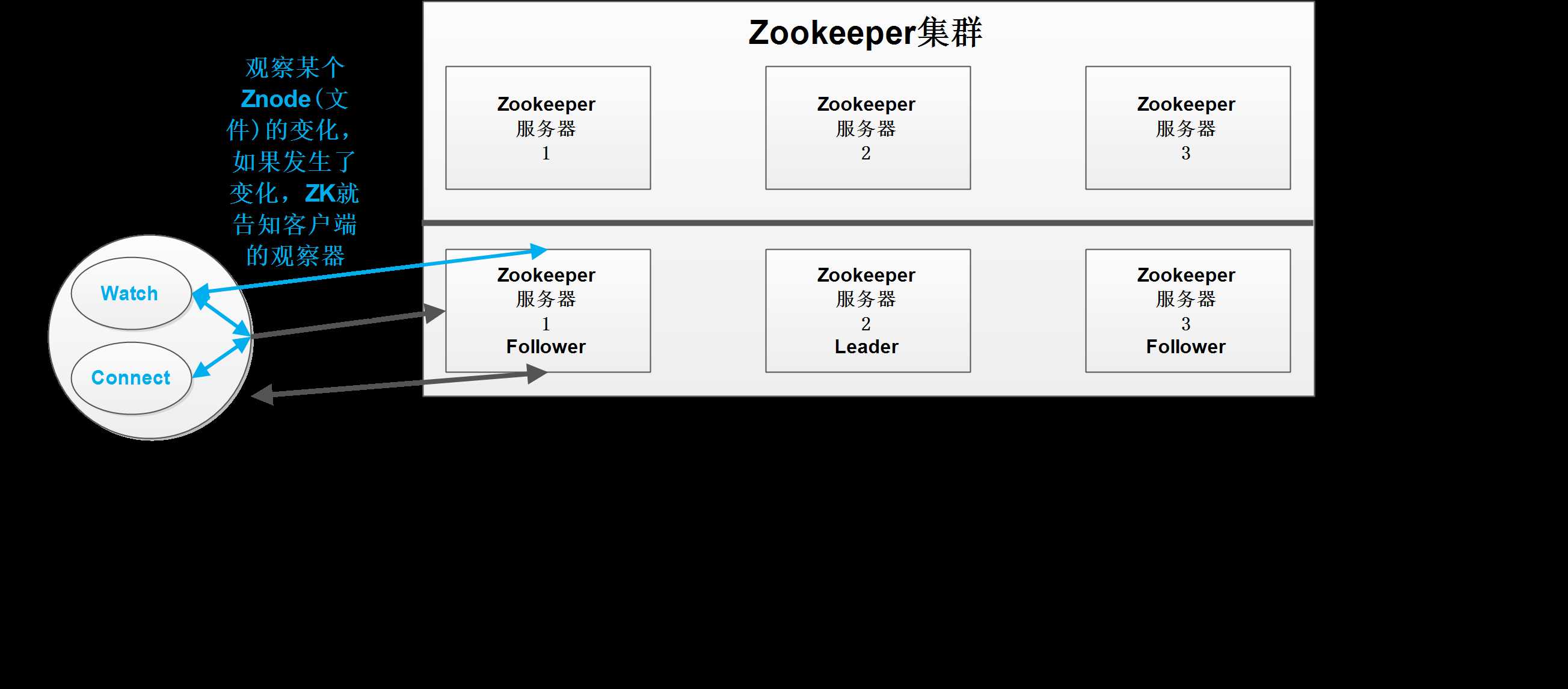
特点
1、Zookeeper是由一个Leader和多个Follower组成的集群。
2、Leader负责进行投票发起和发起决议,更新系统状态
3、Follower用于接收客户端的请求并返回结果,在选举Leader过程中参与投票。
4、Follower负责读请求,写请求则要提交给Leader决定。
5、集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。
6、更新请求顺序执行,来自同一个客户端的更新请求时按照发送顺序依次执行。
7、数据更新的原子性,要么更新数据成功,要么失败。
8、实时性,在一定时间的范围内客户端可以读到最新的数据
选举机制(Leader)
配置文件中没有指定Leader和Follower的话,Zookeeper会内部进行选举。
假设:
服务器1、2、3。
服务器1启动,但是只有自己一个人,选举状态为Looking。
服务器2启动,首先和已经启动的服务器1进行通信,交换选举信息,但是服务器1和2都没有历史数据,那么他们都投票给了自己,但是id值大的服务器2胜出。
服务器3启动,和服务器1、2进行通信,发现已经选举出了2作为Leader,那么就成为Follower了,但是如果服务器2发生网络问题了,一直没有发送出去交互信息,到把消息发送出去的时候,发现别人的投票已经处于第二轮,而它发出去的是第一轮,这里就涉及到逻辑时钟(时间同步)了,所以则服务器3成为Leader。
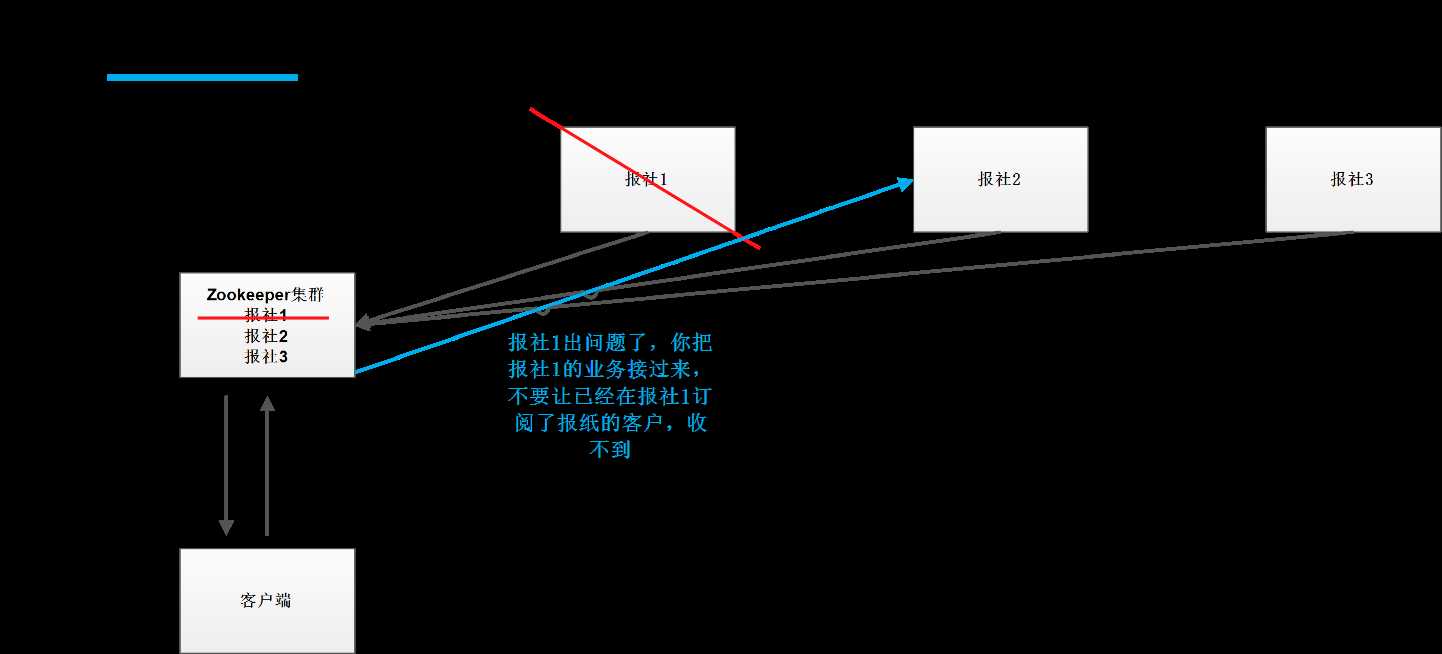
应用场景
Zookeeper提供的服务数据发布订阅、负载均衡、命中服务、分布式协调/通知、分布式锁、分布式队列等功能。
Zookeeper就是一个监控、通知、辅助(其他).
如:分布式锁,其他用户在操作,通知其他服务器有人在操作,等用户操作完了就告诉其他服务器,他操作完了。
案例
配置文件
tickTime:服务器和服务器之间,或服务器和客户端之间发送心跳消息的时间间隔,session的最小超时时间为2*tickTime
initLimit:Leader和Follower的初始连接时心跳数(时间=initLimit * tickTime);Follower在启动的时候,会从Leader同步所有最新的数据,以确定自己对外服务的状态;投票选举新Leader的初始化时间;
syncLimit:Leader和Follower的之间的最大等待响应时间(syncLimit * tickTime),超过这个时间,Leader就可以认为这个Follower挂了。
dataDir:数据文件存放路径
clientPort:客户端连接ZK服务端的端口
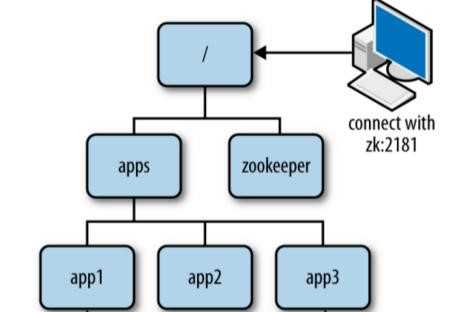
数据结构
Zookeeper的数据结构是一个树状化的结构,每个节点称为Znode,每个ZNode默认存储1MB的数据可以通过路径进行唯一标识。(/apps/app1)
节点类型
短暂(ephemeral):客户端和服务器端断开后,这种类型的节点就会删除。
短暂序号:创建这种节点的时候,会自动的加上一个递增序号。
持久(persistent):客户端和服务器端断开连接,这种类型的节点不会被删除。
持久序号:创建这种节点的时候,会自动的加上一个递增序号。
常用命令
应用程序命令
启动服务器端:/bin/zkServer.sh start
关闭服务器端:/bin/zkServer.sh stop
启动客户端:bin/zkCli.sh
客户端命令
退出客户端:quit
查看节点下的子节点:ls /
节点下的子节点变化监听:ls /test watch
查看节点下的子节点详细信息:ls2 /
创建普通节点:create /test “data”
创建普通节点(序号):create -s /test “data”
创建短暂节点:create -e /testE “data”
创建短暂节点(序号):create -e -s /testES "data"
修改节点数据值:set /test “new data”
获取节点值:get /test
节点值变化监听(监听一次,注册一次):get /test watch
删除节点:delete /test
递归删除节点:rmr /test
查看节点详情:stat /test
czxid:引起这个znode创建的zxid,创建节点的事务zxid
ctime:znode被创建的毫秒数(从1970开始)
mzxid:znode最后更新的zxid
mtime:znode最后修改的毫秒数(从1970开始)
pZxid:znode最后更新的子节点zxid
cversion:znode子节点的变化号,子节点修改次数
dataversion:znode数据变化号
aclVersion:znode访问控制列表的变化号
ephemeralOwner:如果是临时节点,这个znode拥有者的sesion id,如果不是临时节点就为0
dataLength:znod的数据长度
numChildren:znode子节点数量
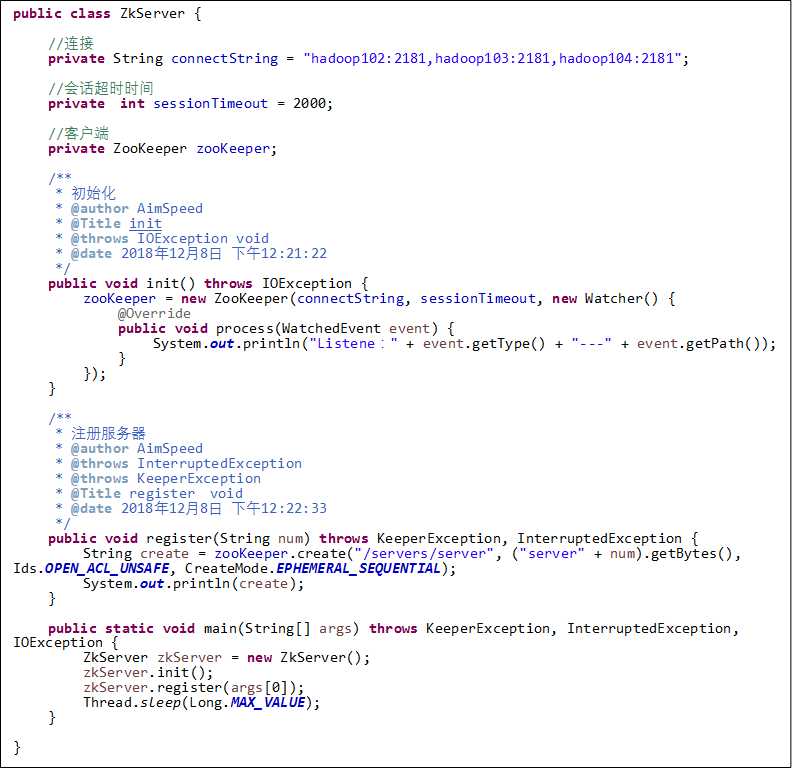
Java – API(模拟Zookeeper监控)
ZkClient

ZkServer
以上是关于Zookeeper的主要内容,如果未能解决你的问题,请参考以下文章